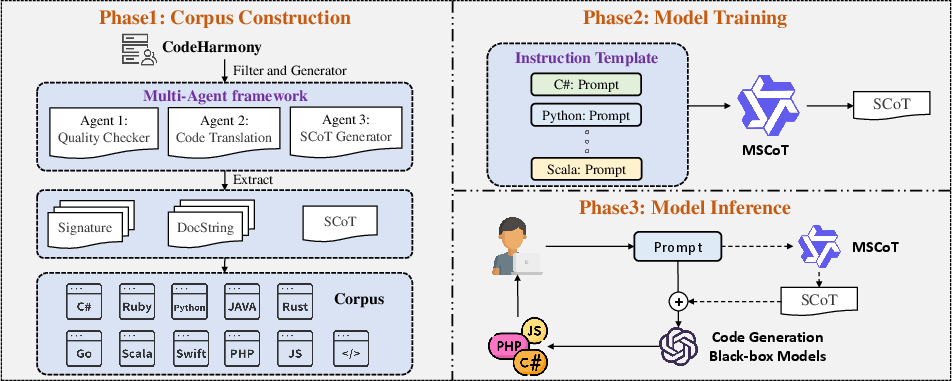
- The paper introduces MSCoT which constructs a large-scale multilingual chain-of-thought dataset covering 12 programming languages and boosts pass@1 scores by up to 16.25%.
- It proposes a novel multi-agent framework employing CQAgent, CTAgent, and SCoTAgent to ensure high-quality dataset synthesis, style-aware translation, and structured reasoning.
- The approach achieves near GPT-4-level performance with lower resource demands, significantly improving cross-language code generation and reasoning robustness.
MSCoT: Structured Chain-of-Thought Generation for Multilingual Code Generation
The increasing prevalence of multi-language development environments necessitates code generation models capable of reasoning across diverse programming languages. Most prevailing chain-of-thought (CoT) generation methods are tailored for Python-centric code and lack robust generalization to other languages, constraining their effectiveness in multilingual settings. There exists a notable shortage of high-quality CoT datasets spanning multiple programming languages, impeding the training of models with cross-language reasoning abilities.
MSCoT addresses this gap by constructing a large-scale CoT dataset covering 12 programming languages and proposing a structured chain-of-thought generation approach optimized for multilingual code generation scenarios.
Dataset Construction and Multi-Agent Framework
MSCoT employs a multi-agent system to synthesize high-quality CoT datasets. The workflow integrates three specialized agents:
The final dataset comprises 84,000 samples (7,000 per language), encompassing CSharp, Go, Java, JavaScript, Kotlin, Perl, PHP, Python, Ruby, Scala, Swift, and TypeScript.
Model Architecture and Training Methodology
MSCoT is instantiated via fine-tuning the 7B-parameter Qwen2.5Coder model using Low-Rank Adaptation (LoRA) for parameter-efficient learning. A novel Instruction Template standardizes input prompts and guides the model to generate coherent, structured CoTs, enhancing reasoning interpretability and cross-language consistency.
In inference, MSCoT utilizes greedy decoding for stable CoT generation, and is designed to function as a modular component in code generation pipelines—activating only when the baseline model fails to produce correct code.
Empirical Results: Quantitative and Qualitative Evaluation
MSCoT's efficacy was benchmarked using DeepSeek-Coder 6.7B-instruct and Qwen2.5Coder 7B-instruct across HumanEval-XL, a comprehensive multilingual code generation testbed.
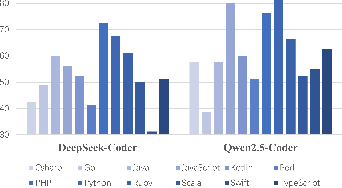
Figure 2: Comparative performance of code generation models on HumanEval-XL, highlighting the variance across languages and the positive impact of CoT-guided approaches.
Integrating MSCoT as a CoT generator led to substantial improvements:
- DeepSeek-Coder's average pass@1 score improved from 52.92% to 66.04% (+13.12%), with notable gains in Python (+16.25%), JavaScript (+12.5%), and Java (+13.75%).
- Qwen2.5Coder's average pass@1 score increased from 61.56% to 72.29% (+10.73%).
MSCoT consistently outperformed baseline CoT generation approaches (Zero-Shot CoT, Self-CoT, COTTON) and reduced the performance gap with GPT-4-based solutions to less than 3.2% in most cases, despite significantly lower resource requirements.
CoT generated by MSCoT exhibited strong language-agnostic reasoning and semantic consistency across different implementation languages, in contrast to COTTON, which displayed marked variation and reduced adaptability.
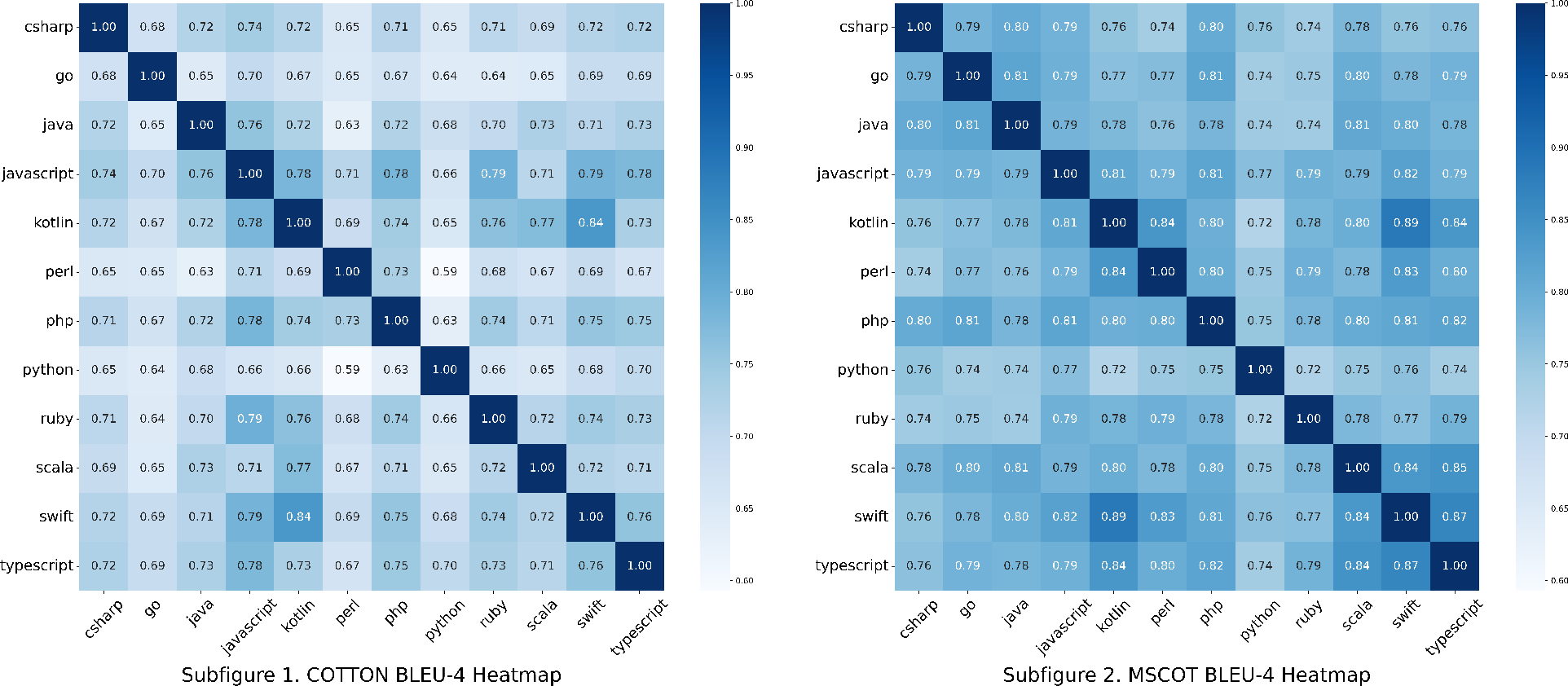
Figure 3: Correlation heatmap between COTTON and MSCoT CoTs, illustrating MSCoT's superior consistency and language-agnostic reasoning patterns.
A human study evaluated CoTs along dimensions of similarity, naturalness, and educational value. In all metrics, MSCoT surpassed COTTON:
- Similarity: 3.47 vs. 2.78
- Naturalness: 3.33 vs. 2.57
- Educational Value: 3.28 vs. 2.50
These results validate MSCoT's ability to generate CoTs that are semantically faithful, interpretable, and pedagogically beneficial across languages.
Chain-of-Thought Generation Mechanics
CoT reasoning in MSCoT decomposes complex code generation problems into sub-tasks and sequential reasoning steps. By utilizing program structure templates, MSCoT ensures the methodology is invariant to syntax differences, yielding high cross-language generalizability.
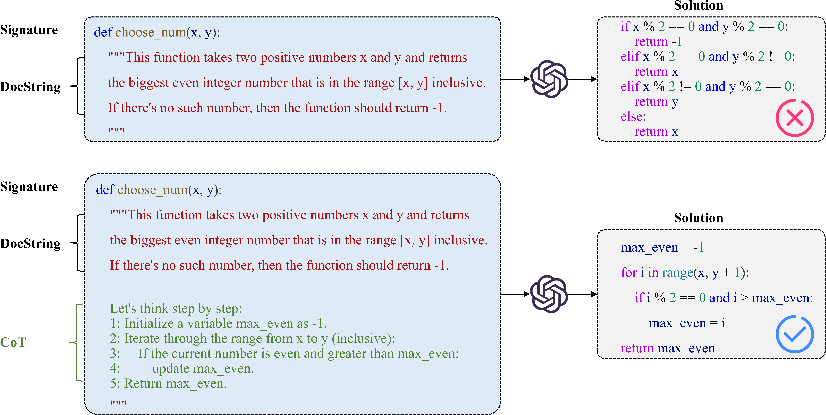
Figure 4: Example of CoT generation, demonstrating sequential decomposition and stepwise reasoning for code synthesis.
Practical and Theoretical Implications
MSCoT's structured, language-agnostic CoT generation has several implications:
- Enables robust code generation support for multi-language projects, critical in microservice, frontend-backend, and cross-platform ecosystems.
- Lowers resource barriers by achieving near-GPT-4-level performance with small models, facilitating wider deployment.
- Advances theoretical understanding of reasoning transfer between natural language and programming language domains.
- Provides an open-source dataset and model, catalyzing further research in multilingual code intelligence and CoT prompting strategies.
Prospects for Future Research
Extensions of MSCoT may encompass broader language coverage, integration with more complex programming paradigms, improved efficiency via dynamic prompt adaptation, and real-world deployment studies. Investigating the interplay of structured CoT with self-aligned and self-planning methods may further boost reasoning robustness in code generation LLMs.
Conclusion
MSCoT delivers a scalable, structured chain-of-thought generation framework for multilingual code synthesis. Its multi-agent dataset curation, instruction template-guided modeling, and efficient adaptation mechanisms yield strong empirical and qualitative results, bridging the gap between lightweight and large-code LLM reasoning. The open-sourced dataset and model lay a foundation for future advancements in AI-driven software engineering and code intelligence.