- The paper presents a dual-space knowledge distillation framework that projects hidden states between teacher and student models to overcome vocabulary mismatches.
- The paper incorporates an Exact Token Alignment algorithm to ensure effective knowledge transfer by focusing only on shared tokens between differing model vocabularies.
- The paper extends the framework to on-policy scenarios, demonstrating significant Rouge-L score improvements with minimal computational overhead.
A Dual-Space Framework for General Knowledge Distillation of LLMs
Introduction
The paper introduces a dual-space knowledge distillation (DSKD) framework aimed at addressing limitations in traditional knowledge distillation (KD) methods for LLMs. Existing KD approaches face challenges when dealing with models that have different prediction heads and vocabularies, limiting their practical applications. The proposed DSKD framework seeks to unify the prediction heads by projecting hidden states between teacher and student models, allowing for more effective knowledge transfer even across models with different vocabularies.
Methodology
Dual-Space Knowledge Distillation Framework
The DSKD framework operates by projecting hidden states of the teacher and student models into each other's representation spaces. This is achieved using linear projectors that are initialized to maintain the logits' invariance before and after projection. The framework's key aspects include:
- Student Space Projection: The teacher's hidden states are mapped to the student's representation space using a projector Wt→s, allowing the student to use its prediction head for achieving aligned outputs.
- Teacher Space Projection: Similarly, the student's hidden states are projected into the teacher's space with another projector Ws→t to fortify learning using the teacher's head.
In doing so, DSKD facilitates Knowledge Distillation by synchronizing the distributions to a common space, ensuring compatibility even when teachers and students have different vocabularies.
Exact Token Alignment (ETA)
For LLMs with differing vocabularies, DSKD incorporates an Exact Token Alignment (ETA) algorithm. ETA identifies tokens shared between the teacher and the student, conducting KD only on these aligned positions. This alignment ensures that KD can proceed naturally despite differing underlying vocabularies without performance degradation.
Extension to On-Policy Scenarios
DSKD is further extended to the on-policy scenario, allowing the student model to learn from its generated outputs rather than the fixed ground truth. This methodology mitigates discrepancies arising from training versus inference conditions.
Experimental Evaluation
Off-Policy and On-Policy KD
Extensive experiments were conducted to compare the proposed DSKD framework under both off-policy and on-policy KD scenarios for models with the same and different vocabularies. Models such as GPT2-120M, TinyLLaMA-1.1B, and others were evaluated against substantial instruction-following, math, and code generation benchmarks.
- Performance Metrics: Metrics such as Rouge-L scores were employed to measure improvements in model outputs post KD.
- Results: The DSKD framework showed significant improvements over traditional KD frameworks, particularly with noticeable gains in Rouge-L scores, suggesting more effective distillation.
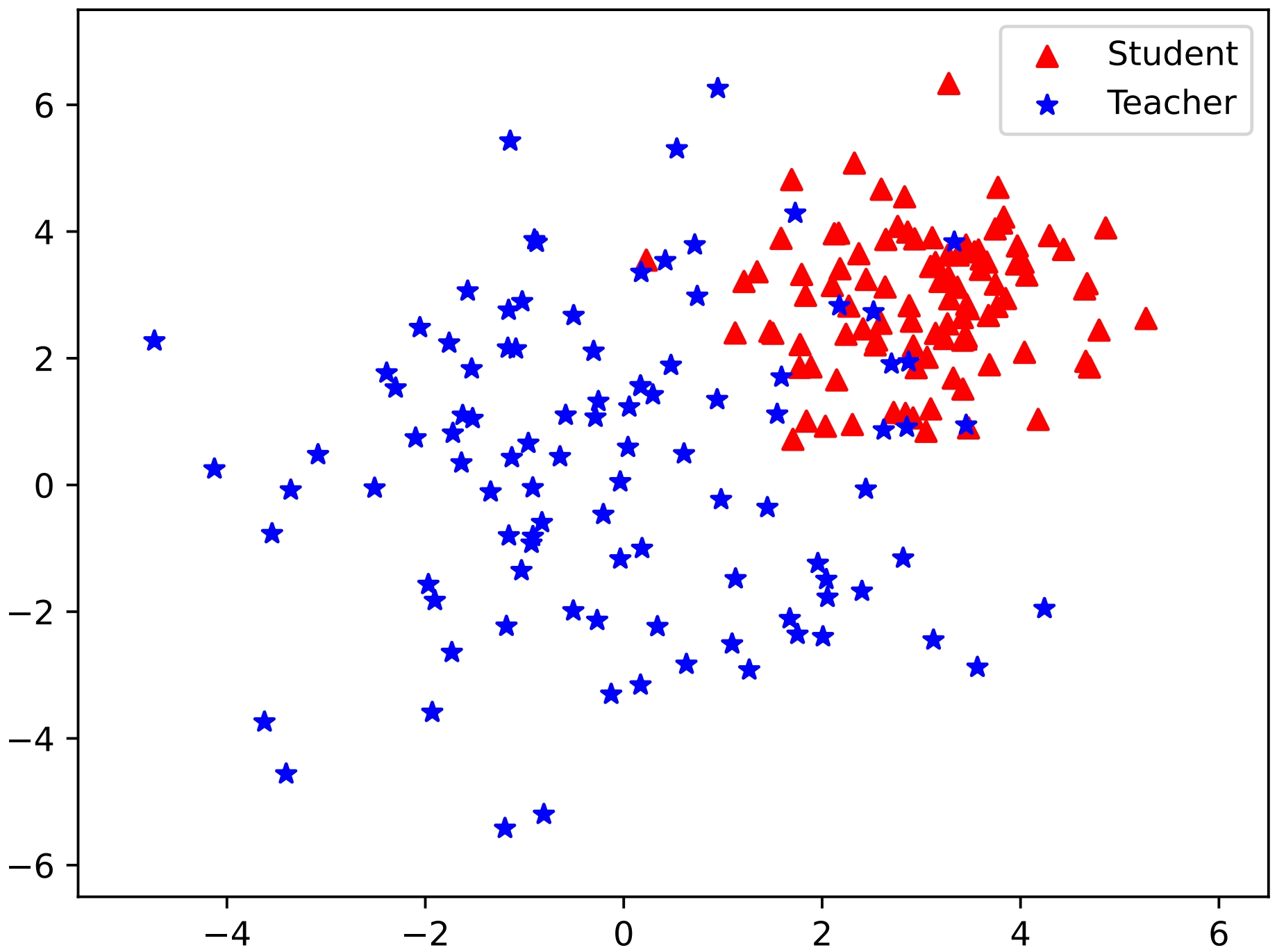
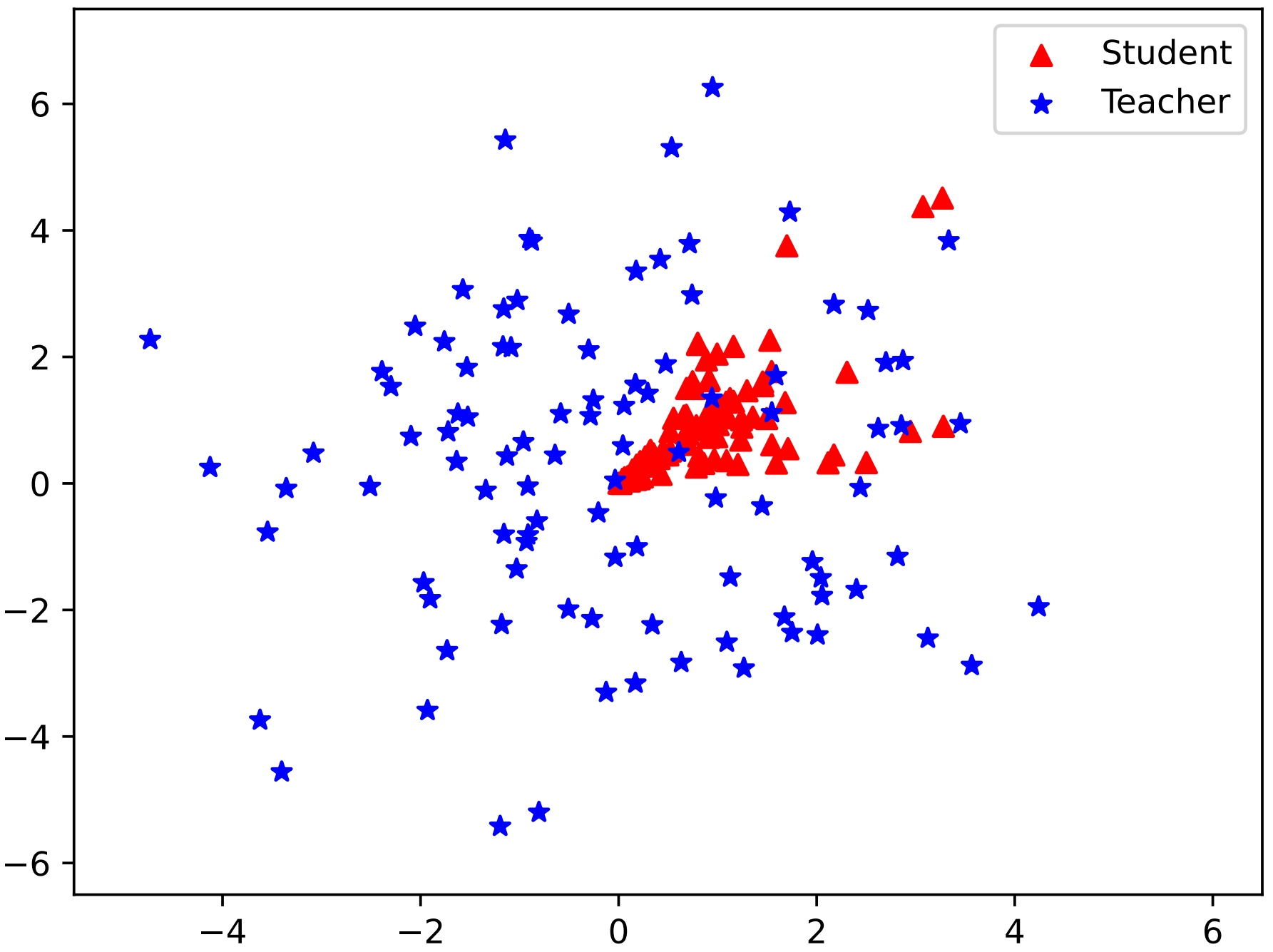
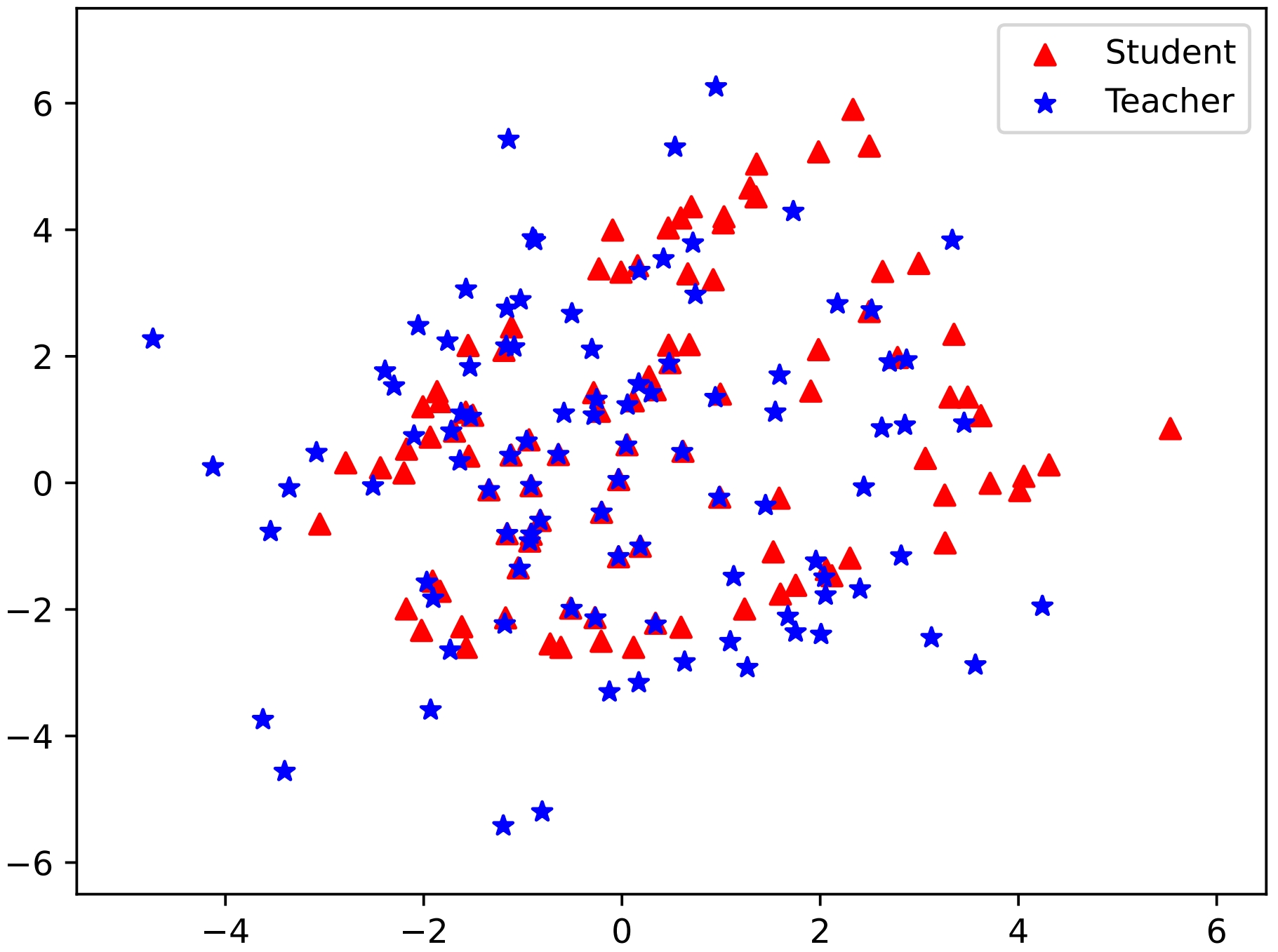
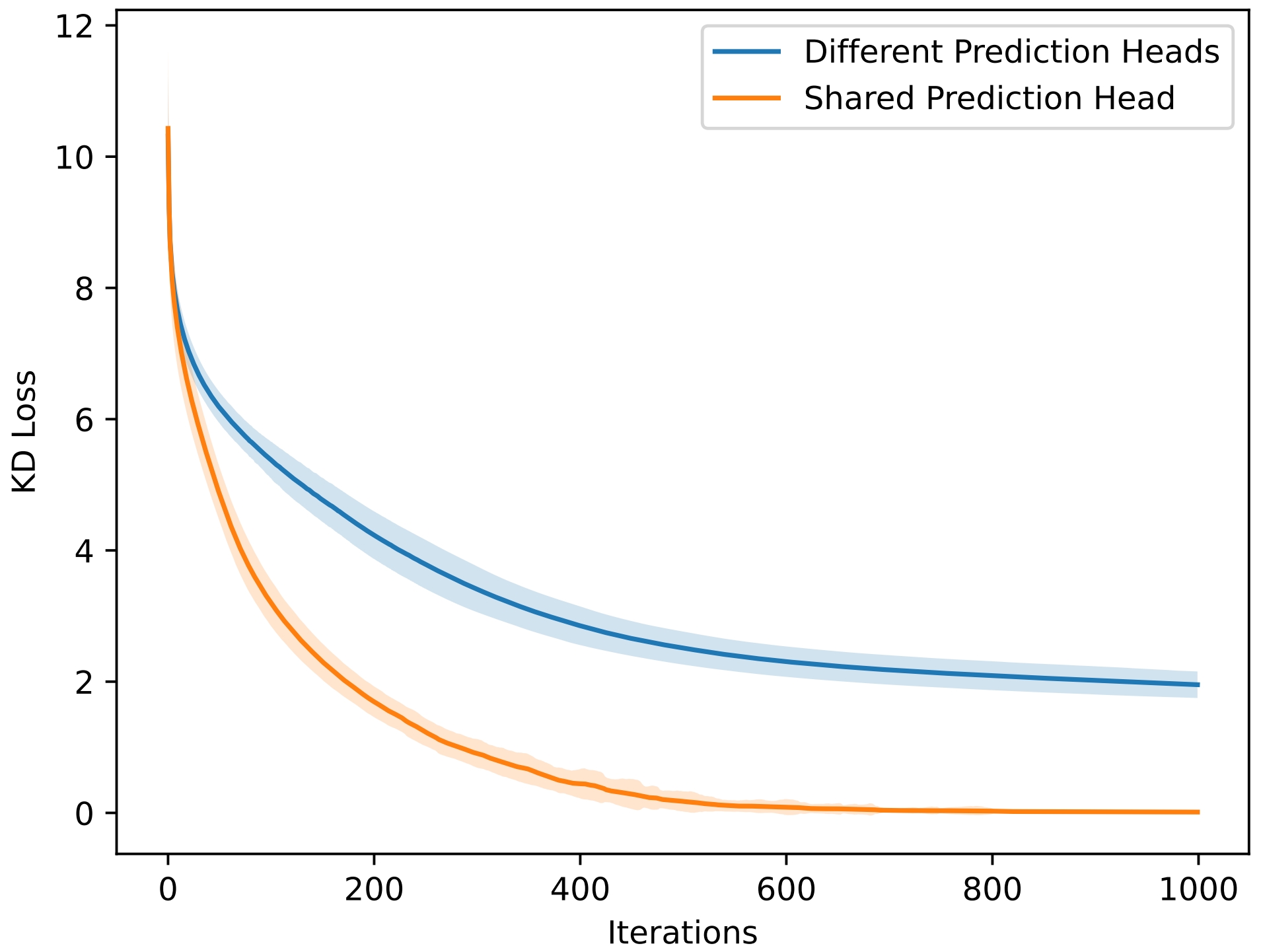
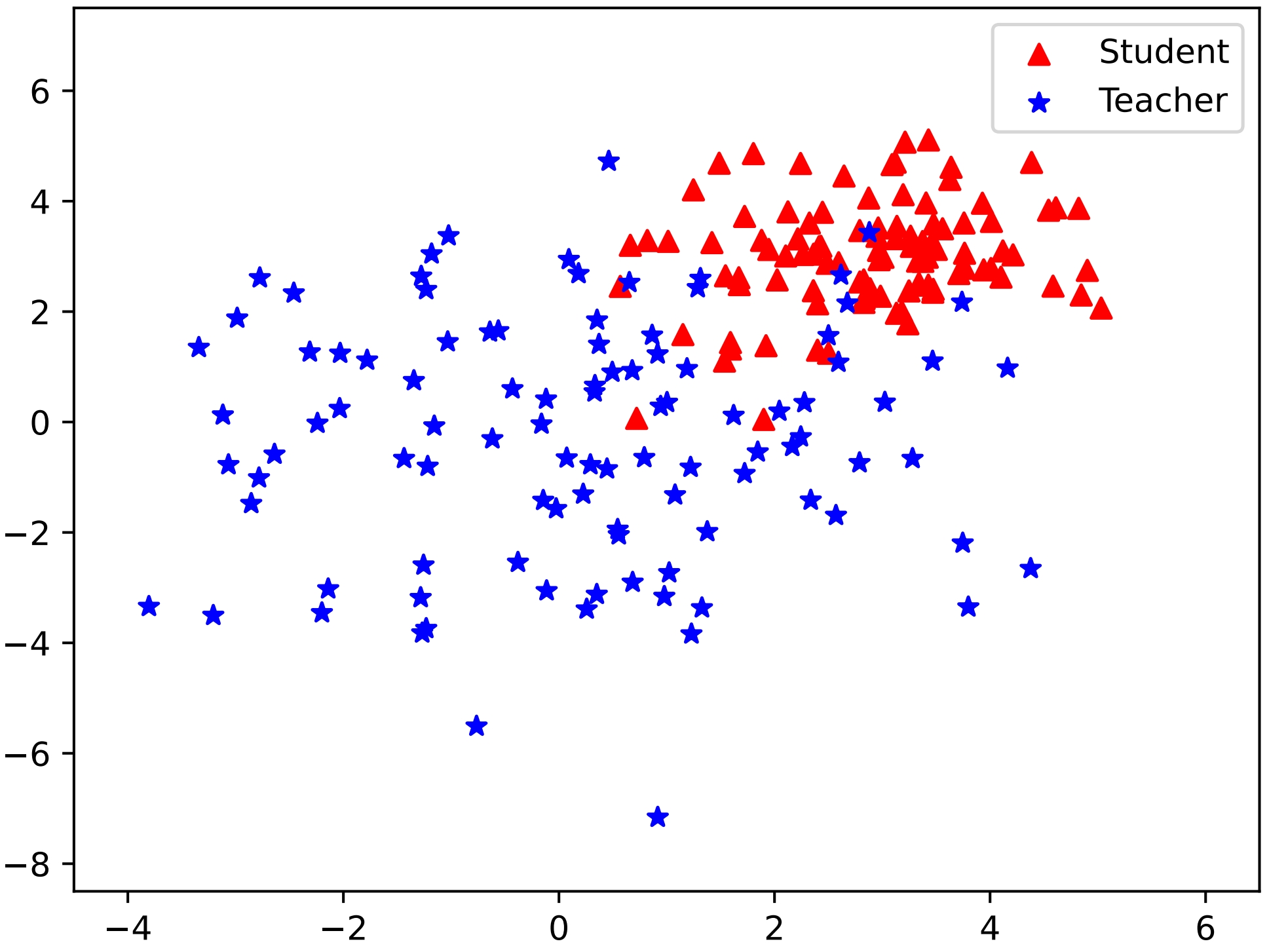
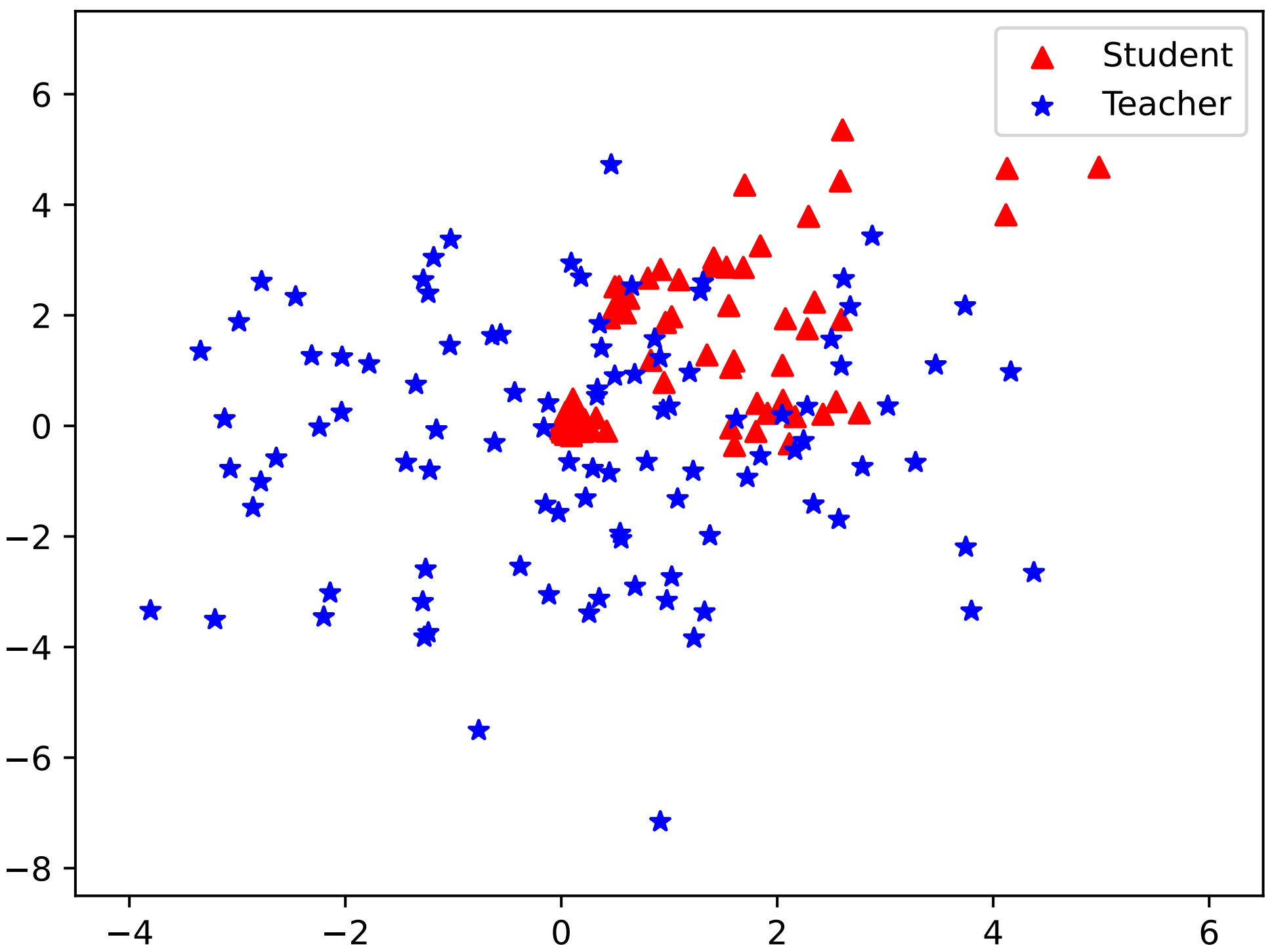
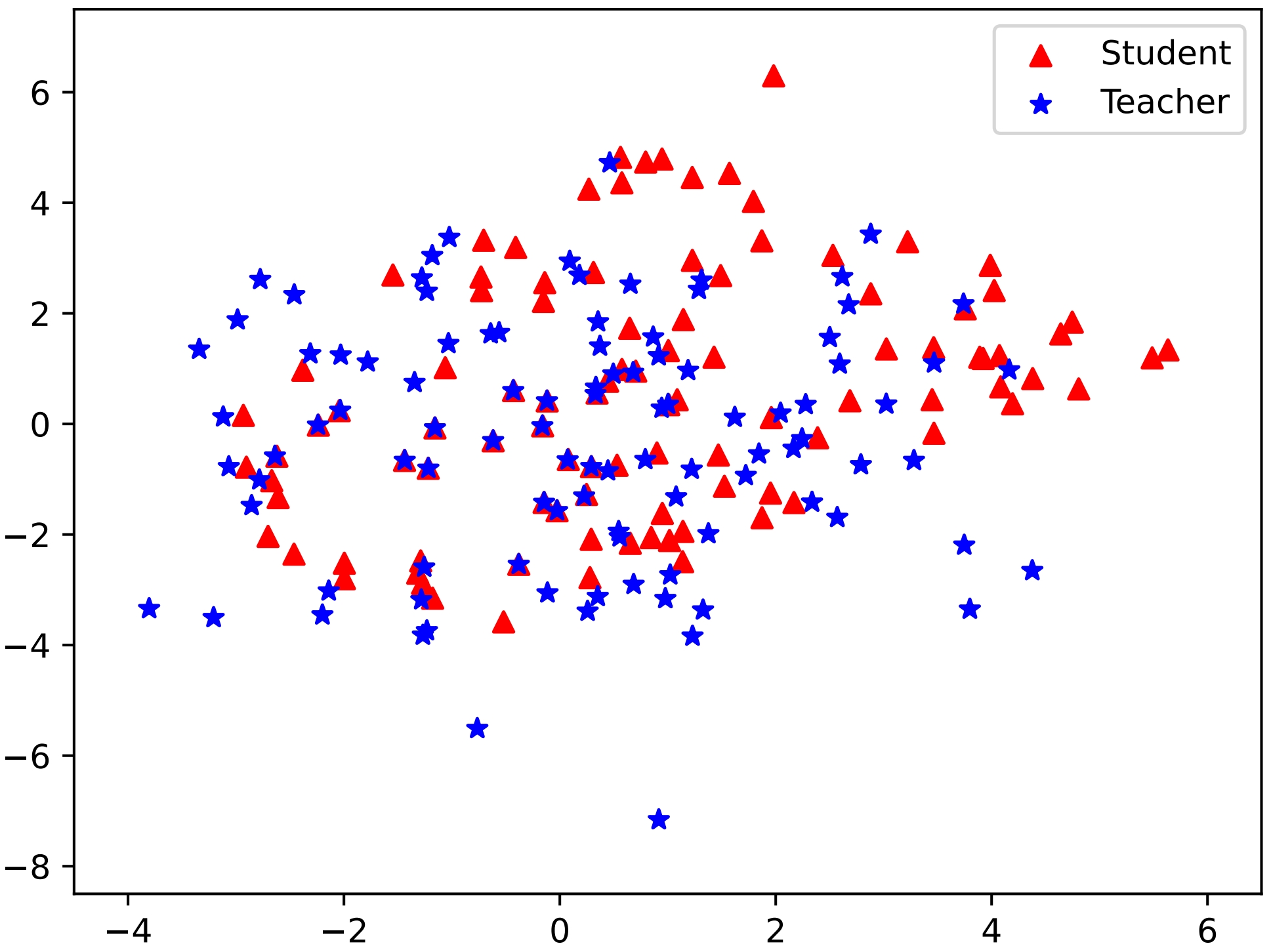
Figure 1: Simulation results with KL and RKL divergence showcasing the effectiveness of unified output spaces in DSKD.
Computational Efficiency
The computational overhead introduced by DSKD is minimal relative to the benefits gained in effectiveness. DSKD's additional projector parameters are negligible, making it feasible for large-scale applications.
Conclusion
The DSKD framework successfully overcomes limitations of traditional KD methodologies, particularly bridging distributional divergences in models with differing vocabularies. With the introduction of projectors that harmonize teacher-student outputs and the effective ETA algorithm, DSKD substantially enhances the distillation process, demonstrating improved performance across diverse tasks. Future work may focus on further optimizing the initialization of projectors and expanding the framework's applicability to real-world, multilingual, or multi-domain settings.