- The paper introduces the d1 framework that combines supervised finetuning with the diffu reinforcement learning algorithm to enhance reasoning in masked diffusion LLMs.
- It employs prompt masking to efficiently estimate log-probabilities and overcome the limitations of sequential token processing.
- Experimental results demonstrate that d1 significantly outperforms baseline models on GSM8K and logical reasoning benchmarks.
Scaling Reasoning in Diffusion LLMs via Reinforcement Learning
This paper introduces the framework "d1," which aims to enhance reasoning capabilities in masked diffusion-based LLMs (dLLMs) through supervised finetuning (SFT) and a novel reinforcement learning (RL) algorithm called "diffu." The framework shows promising results by scaling reasoning abilities in dLLMs, previously less explored compared to autoregressive counterparts.
Background and Motivation
Recent developments in autoregressive LLMs have shown that reinforcement learning can significantly improve reasoning capabilities by allowing models to explore and learn from rewards rather than static datasets. However, existing RL methods such as PPO and GRPO rely on sequential token processing, making them unsuitable for non-autoregressive models like dLLMs. dLLMs generate text through iterative denoising, leveraging bidirectional attention across multiple generation steps. Despite achieving competitive language modeling performance, post-training improvements like RL have remained untapped.
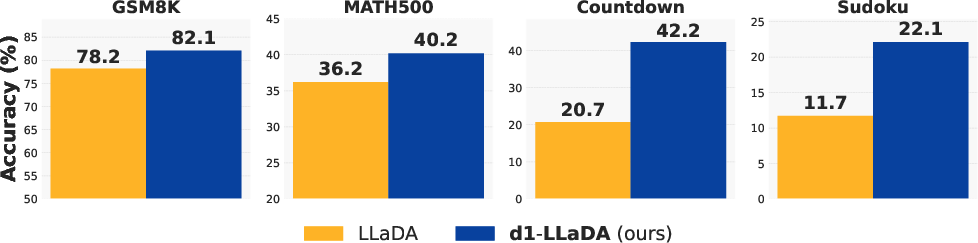
Figure 1: Across four math and logical reasoning tasks, d1-LLaDA, which undergoes SFT followed by our proposed diffu, consistently outperforms the base LLaDA-8B-Instruct model.
Diffu Algorithm for dLLMs
The diffu algorithm extends GRPO for masked diffusion models by efficiently estimating log-probabilities without sequential factorization, a characteristic intrinsic to autoregressive models. Diffu introduces a one-step estimation method using prompt masking, where the gradient of colors in log probabilities arises from different masking patterns, enabling more gradient updates per batch due to the regularization effect.
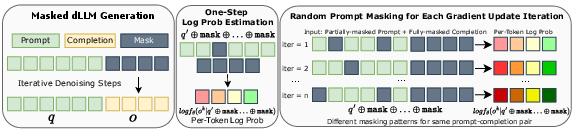
Figure 2: Log Probability Estimation in diffu. A random masking pattern is applied to the prompt during policy gradient updates creating diverse views and reducing the number of necessary online generations.
Training Framework: d1
The framework consists of two consecutive training stages:
- SFT on reasoning traces enhances the model by instilling behavior through curated datasets that demonstrate step-by-step problem-solving processes.
- The diffu algorithm refines the model's reasoning capabilities through RL by leveraging estimated log-probabilities for policy optimization.
d1 achieves higher scores across logical and mathematical reasoning benchmarks compared to post-training using only SFT or diffu.
Experimental Results and Discussion
Experiments demonstrate significant performance improvements using the d1 framework. d1 consistently outperforms both base models and alternative post-training approaches across mathematical reasoning tasks such as GSM8K and logical reasoning tasks including 4x4 Sudoku. Notably, careful analysis shows that diffu enhances the reasoning capabilities beyond training sequence lengths, suggesting generalized strategies rather than overfitting.
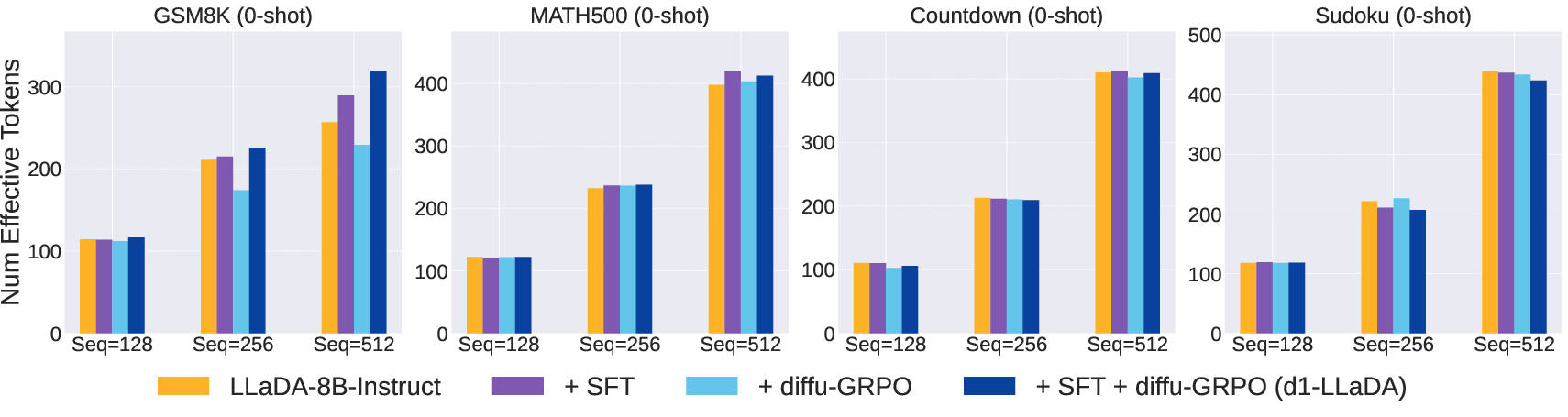
Figure 3: Effective Tokens Usage: Number of effective tokens remains comparable across tasks, indicating robust performance across varying sequence lengths.
Under the same test conditions, d1-LLaDA surpasses other state-of-the-art models in reasoning tasks, achieving superior GSM8K scores.
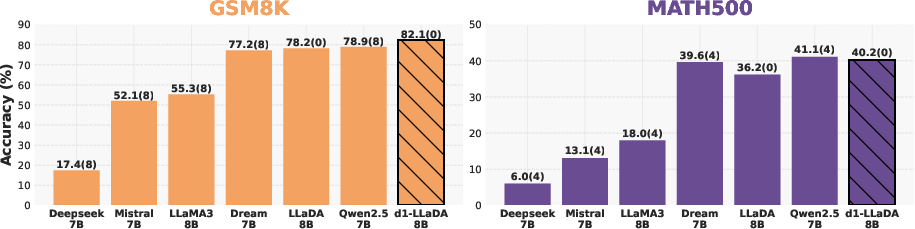
Figure 4: Comparison with state-of-the-art dLLMs and AR LLMs. d1-LLaDA achieves the highest GSM8K score.
The research also highlights the design choices impacting RL in masked dLLMs, emphasizing the advantages of random masking for optimizing policy updates effectively, thus allowing faster convergence and reduced computational costs.
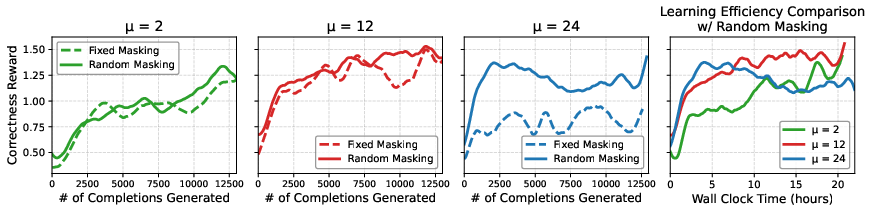
Figure 5: Comparison of fixed vs. random masking across different policy optimization update values (mu). Random masking consistently outperforms fixed masking.
Conclusion
This paper outlines a comprehensive strategy for enhancing reasoning capabilities in diffusion LLMs by integrating SFT and RL through the d1 framework. The insights gained from implementing diffu provide a pathway for efficiently applying RL to non-autoregressive models. Future research avenues may explore decoding strategies to scale generation lengths, optimizing these models even further.
The combination of these techniques collectively promotes better reasoning despite the inherent challenges with non-sequential generation processes in dLLMs.