- The paper demonstrates that LLMs encode knowledge boundaries predominantly in mid to upper layers, enabling effective cross-lingual representation.
- It proposes training-free alignment techniques such as mean-shifting and linear projection to enhance knowledge transfer and reduce hallucinations.
- Multilingual fine-tuning on bilingual question pairs proves effective in refining boundary cognition and improving performance in low-resource languages.
Analyzing LLMs' Knowledge Boundary Cognition Across Languages
The paper investigates how LLMs understand and encode the concept of knowledge boundaries across multiple languages through their internal representations. This study is crucial for mitigating hallucinations when LLMs provide responses beyond their knowledge scope. The paper identifies key properties in the representations of LLMs and proposes methodologies for improving cross-lingual knowledge boundary cognition.
Knowledge Boundary Representation
The authors analyze how LLMs encode known and unknown questions within their layers. Their findings suggest that knowledge boundary awareness is predominantly encoded in the mid to upper layers of LLMs across different languages. This understanding allows us to probe these representations, revealing that there is substantial inter-language transferability, particularly effective in middle layers where language-specific representations converge into a unified knowledge space.

Figure 1: Analyzing LLMs' cognition of knowledge boundaries across different languages by inspecting their representations.
Language Structure and Alignment
A significant revelation is the linear structural encoding of language differences in knowledge representation, which facilitates effective cross-lingual transfer. This motivates training-free alignment methods such as mean-shifting and linear projection, dramatically improving inter-language transferability, thereby reducing risks of hallucination. These techniques nearly match in-distribution accuracy by aligning out-of-distribution language representations with in-distribution subspaces.
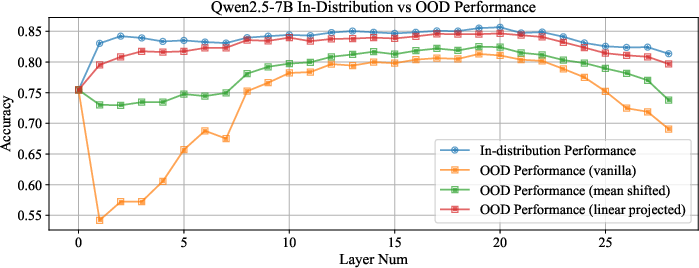
Figure 2: In-distribution and OOD performance of layer-wise probes across different methods.
Multilingual Fine-Tuning Enhancements
Fine-tuning LLMs on bilingual question pairs, especially involving low-resource languages, enhances the generalization of knowledge boundary perception across language domains. This approach leverages existing cross-lingual capabilities in LLMs, refining their boundary recognition ability profoundly after focused training. It shows promise for languages not directly involved in the training pairs, suggesting a latent safety reinforcement mechanism for dominant languages within the model's structures.
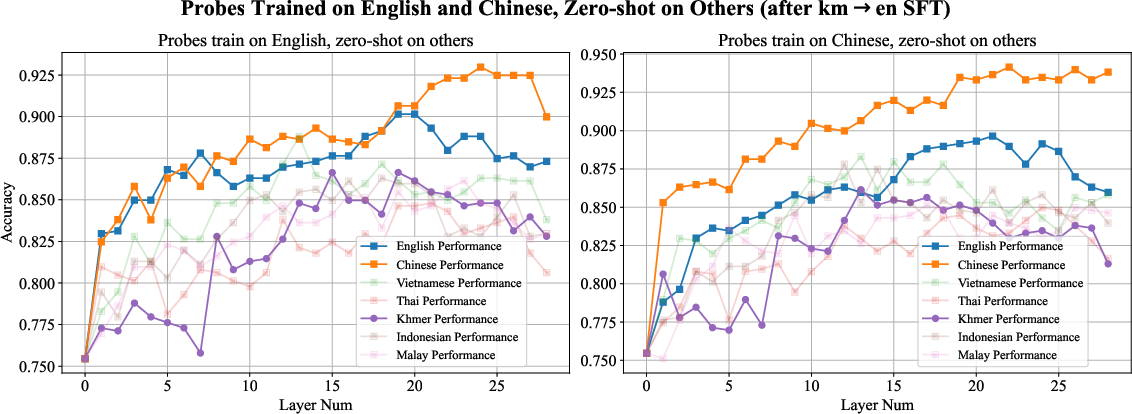
Figure 3: Enhancement in Chinese representations post fine-tuning on Khmer-English translations.
Implications and Future Directions
The implications of these findings are profound for deploying LLMs in multilingual contexts, particularly for ensuring consistent and reliable behavior across varying language resources. The methodologies proposed offer practical pathways for deploying LLMs in low-resource environments, enhancing their capacity to avoid incorrect or hallucinatory outputs.
Going forward, further exploration into the dynamics of LLM internal states during generative processes could uncover additional insights into how knowledge boundary cognition evolves during computational reasoning. These advancements may ultimately refine safety and efficiency in LLM applications globally.
Conclusion
This paper presents foundational insights into the cognition of knowledge boundaries by LLMs across languages. Through advanced probing and fine-tuning techniques, it provides innovative solutions for enhancing cross-lingual knowledge transferability, offering a robust framework for reducing hallucinations in LLMs. The research lays the groundwork for further advancements in aligning LLM capabilities with diverse linguistic settings.