- The paper introduces LUFFY that significantly improves reasoning in reinforcement learning by integrating off-policy guidance with on-policy rollouts.
- The methodology employs regularized importance sampling and policy shaping to maintain high exploration while imitating high-quality reasoning patterns.
- Empirical evaluations on benchmarks like AIME and OlympiadBench show an average performance gain of over +7.0 points compared to traditional zero-RL methods.
Learning to Reason under Off-Policy Guidance
Introduction to Off-Policy Guidance in Reinforcement Learning
The paper "Learning to Reason under Off-Policy Guidance" (2504.14945) introduces a novel framework, LUFFY, that enhances the capabilities of large reasoning models (LRMs) by integrating off-policy reasoning traces into reinforcement learning (RL). This method addresses the limitations of traditional on-policy learning by dynamically balancing imitation and exploration, thus promoting the development of generalizable reasoning skills.
The core challenge addressed by LUFFY lies in overcoming the bottleneck of zero-shot reinforcement learning (zero-RL) approaches that are confined to on-policy rollouts. Traditional on-policy methods focus solely on the model's self-generated outputs, thus limiting the acquisition of enhanced reasoning capabilities. Consequently, there arises a need for incorporating external guidance mechanisms to surpass inherent cognitive barriers.
LUFFY Framework and Methodology
LUFFY operates by amalgamating off-policy traces with on-policy rollouts within the RL framework. The integrated approach not only amplifies imitation of high-quality reasoning patterns but also preserves the model's exploratory capacity. The framework employs regularized importance sampling, which prevents premature convergence to suboptimal solutions by dynamically emphasizing low-probability, yet critical, actions.
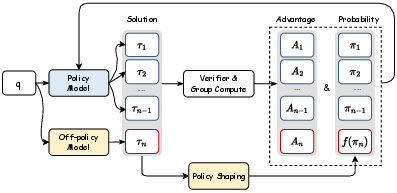
Figure 1: LUFFY integrates off-policy reasoning traces into reinforcement learning by combining them with on-policy rollouts. Policy shaping emphasizes low-probability but crucial actions, enabling a balance between imitation and exploration for more generalizable reasoning.
The implementation of LUFFY involves using policy shaping techniques to maintain entropy and facilitate exploration, which is essential in avoiding the risks of superficial imitation. Mixed-policy advantages are computed to ensure that both on-policy and off-policy rollouts are optimally leveraged, resulting in a robust learning mechanism.
Empirical Evaluation and Results
Extensive empirical evaluations underscore LUFFY's superior performance across multiple benchmarks, including AIME 2024, AMC, and OlympiadBench. LUFFY consistently demonstrates significant improvements over baseline zero-RL methods, evidenced by an average performance gain of over +7.0 points across six competition-level benchmarks.
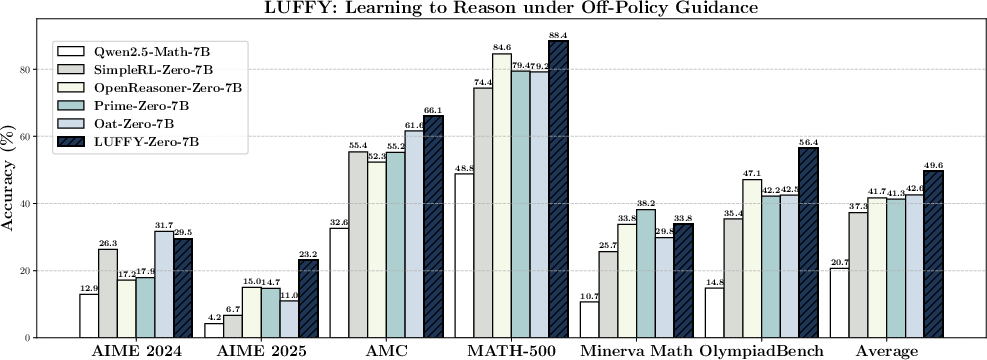
Figure 2: Overall performance across six competition-level benchmarks (AIME 2024, AIME 2025, AMC, MATH-500, Minerva Math, and OlympiadBench). LUFFY achieves an average score of 49.6, delivering a substantial performance gain of over +7.0 points on average compared to existing zero reinforcement learning methods.
LUFFY also shows remarkable generalization capabilities on out-of-distribution tasks, outperforming approaches based on imitation and on-policy RL by over +6.2 points. The results highlight LUFFY's ability to imitate high-quality reasoning patterns while maintaining explorative capabilities, showcasing its potential in addressing complex reasoning challenges.
Training Dynamics and Exploration
The training dynamics reveal that LUFFY maintains a higher level of entropy throughout the RL process compared to purely on-policy methods, thereby sustaining a significant degree of exploration. The introduction of policy shaping through regularized importance sampling plays a pivotal role in maintaining this exploration, as depicted in the entropy dynamics over training iterations.
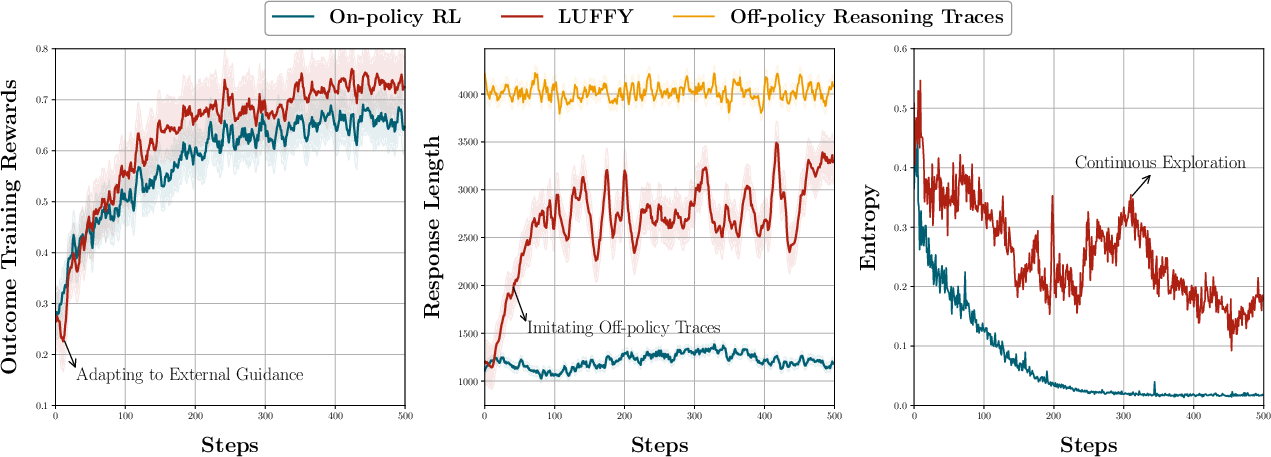
Figure 3: Training dynamics of LUFFY compared with on-policy RL. Left: outcome training rewards; Middle: generation length; Right: generation entropy.
Conclusion
In conclusion, LUFFY represents a significant advancement in integrating off-policy reasoning into RL for enhanced reasoning capabilities. By balancing imitation with exploration, LUFFY surpasses the traditional limitations of on-policy learning in LRMs. Future research may explore the extension of this framework to broader domains and further refine the policy shaping mechanisms to optimize exploration potentials under off-policy guidance.