- The paper demonstrates the effectiveness of generative AI (Claude 3 Opus) in extracting data from diverse research documents, overcoming OCR errors and format inconsistencies.
- The paper highlights the importance of meticulous prompt engineering and controlled temperature settings to improve data extraction accuracy and consistency.
- The paper validates generative AI's robust performance in subjective classification tasks by achieving human-comparable results in categorizing Kickstarter projects.
Generative AI for Research Data Processing: Lessons Learnt From Three Use Cases
Introduction
The paper "Generative AI for Research Data Processing: Lessons Learnt From Three Use Cases" presents an exploratory study on the application of generative AI, specifically Claude 3 Opus, for complex research data processing tasks. It highlights three different use cases where traditional rule-based or ML approaches fall short: information extraction from historical botanical seedlists, natural language understanding in Health Technology Assessment (HTA) documents, and text classification for Kickstarter project categorization.
Use Case Implementation
The first use case involves extracting plant species names from historical seedlists catalogued by botanical gardens. The diversity in format across seedlists makes rule-based extraction challenging. Generative AI was employed due to its ability to interpret unstructured data efficiently.
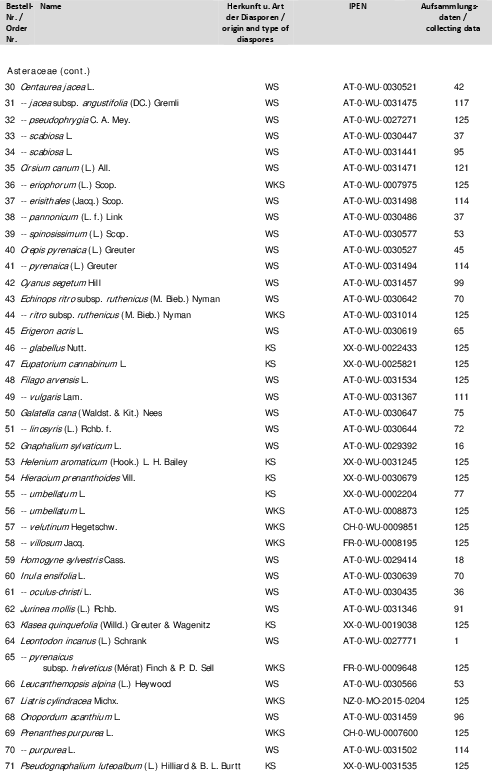

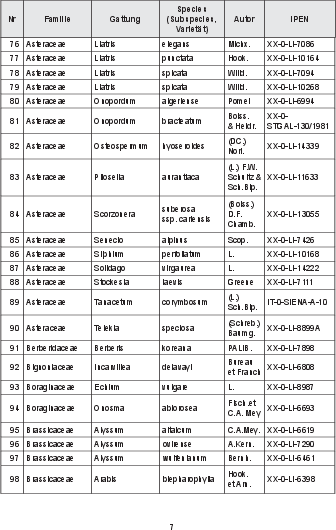
Figure 1: Pages from seedlists in PDF format, showcasing format diversity.
Generative AI effectively extracted species names even amidst OCR errors prevalent in scanned documents. Despite OCR character error rates being below 3%, generative AI demonstrated a capacity to rectify these errors, ensuring high accuracy.
Natural Language Understanding in HTA Documents
The second use case applied generative AI to extract specific data points from HTA documents, which vary in format and language across different EU organizations. Generative AI was chosen for its ability to comprehend and synthesize information from these documents and pose answers to targeted questions about drug assessments, forming structured outputs in JSON format.
Accuracy in data extraction was consistent across multiple runs, with discrepancies primarily arising from non-lexical uniformity due to ambiguous prompts, highlighting the importance of precise prompt engineering.
Text Classification of Kickstarter Projects
The third use case used generative AI to classify Kickstarter projects according to the NAICS code. This task involves interpreting project descriptions to assign an appropriate industry sector code—a process burdened by subjectivity and complexity due to the large number of NAICS codes.
Through interrater reliability testing, generative AI demonstrated comparable performance to human classification, supporting its robustness in subjective classification tasks. It showcased reasonable agreement with human raters, further validating its utility in large-scale classification.
The study identifies key factors influencing the effectiveness of generative AI in data processing:
- Temperature Setting: A zero temperature value optimized for deterministic outputs improved both accuracy and consistency, minimizing generative variability.
- Prompt Engineering: High-quality, clear, and unambiguous prompts were crucial in extracting accurate results, underscoring the significance of prompt design in achieving desired outcomes.
- Input Data Quality: The explicitness of data points in input documents had a direct correlation with the accuracy of generative AI outputs. Generative AI performed best when data was well-defined and required minimal interpretative synthesis.
Implications and Future Work
Generative AI exhibits significant potential in research data processing, especially for tasks with large, heterogeneous datasets not amenable to rule-based methods. Future work should aim at quantitative assessments through traditional metrics like precision and recall, enhancing the understanding of generative AI's capabilities and limitations. Additionally, further exploration into minimizing hallucinatory outputs will advance its adoption in critical, data-sensitive domains.
Conclusion
"Generative AI for Research Data Processing: Lessons Learnt From Three Use Cases" provides a comprehensive analysis of generative AI's applicability to complex data processing tasks across various domains. This exploration underscores its promise as a versatile tool in processing unstructured and complex data, while advocating for rigor in prompt engineering and input data preparation. The study paves the way for future research into optimizing generative AI configurations for even greater reliability and consistency, advancing its role in modern-day research methodologies.