Fine-tune Smarter, Not Harder: Parameter-Efficient Fine-Tuning for Geospatial Foundation Models
Abstract: Earth observation (EO) is crucial for monitoring environmental changes, responding to disasters, and managing natural resources. In this context, foundation models facilitate remote sensing image analysis to retrieve relevant geoinformation accurately and efficiently. However, as these models grow in size, fine-tuning becomes increasingly challenging due to the associated computational resources and costs, limiting their accessibility and scalability. Furthermore, full fine-tuning can lead to forgetting pre-trained features and even degrade model generalization. To address this, Parameter-Efficient Fine-Tuning (PEFT) techniques offer a promising solution. In this paper, we conduct extensive experiments with various foundation model architectures and PEFT techniques to evaluate their effectiveness on five different EO datasets. Our results provide a comprehensive comparison, offering insights into when and how PEFT methods support the adaptation of pre-trained geospatial models. We demonstrate that PEFT techniques match or even exceed full fine-tuning performance and enhance model generalisation to unseen geographic regions, while reducing training time and memory requirements. Additional experiments investigate the effect of architecture choices such as the decoder type or the use of metadata, suggesting UNet decoders and fine-tuning without metadata as the recommended configuration. We have integrated all evaluated foundation models and techniques into the open-source package TerraTorch to support quick, scalable, and cost-effective model adaptation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at smart ways to “fine-tune” big AI models that read satellite images of Earth. These models help with tasks like finding floods, spotting burn scars from wildfires, mapping land cover, and identifying crop types. The goal is to make adapting these models to new tasks faster, cheaper, and more reliable—especially when computers have limited memory.
What were the main goals?
The authors wanted to answer three simple questions:
- Can small, efficient fine-tuning tricks (called PEFT methods) work as well as—or better than—standard fine-tuning on geospatial AI models?
- Do these methods help the models work in new places they’ve never seen before (like a different country)?
- Which “decoder” designs (the part of the model that turns features into pixel-by-pixel maps) work best for these tasks?
How did they do the study?
Key ideas in plain words
- Foundation models: Think of these as very smart “general-purpose” brains trained on lots of satellite images. They learn useful patterns about Earth that can be reused for many tasks.
- Fine-tuning: Like teaching the brain a new skill. Normally, you adjust many parts of the brain (millions of parameters), which can be slow and expensive.
- Parameter-Efficient Fine-Tuning (PEFT): Instead of changing the whole brain, you only tweak a few small parts or add tiny “plugins.” It’s faster, uses less memory, and can still perform great.
The paper tests three PEFT methods:
- LoRA: Adds small “shortcut” layers that lightly steer the model’s attention. Imagine placing a small dial on a big machine to nudge it instead of rebuilding it.
- VPT (Visual Prompt Tuning): Adds special tokens (like hints) to the model’s input, guiding it without changing the main parts.
- ViT Adapter: A small side network that helps the main model better handle detailed, pixel-level tasks.
They tried these on several geospatial foundation models (trained on satellite images), including:
- Prithvi 2.0 (a large, modern model)
- Prithvi 1.0 (an earlier version)
- Clay (another strong model)
- DeCUR (a different style using ResNet)
They tested on five datasets covering different tasks:
- Flood water detection (Sen1Floods11)
- Burn scar mapping after wildfires (Burn Scars)
- Land cover mapping across Europe (reBEN 7k)
- Cashew plantation mapping in Benin (m-Cashew)
- Crop type mapping in South Africa (SA Crop Type)
For each setup, they compared:
- Full fine-tuning (updating almost everything)
- PEFT methods (updating only small parts)
- Different decoders (linear, FCN, UperNet, UNet), which turn features into useful maps
- Performance on places seen in training vs. brand-new regions (a “geographic hold-out set”)
They measured results using mIoU, a score that shows how well the predicted map overlaps with the true map. Higher is better.
What did they find, and why does it matter?
Here are the most important results:
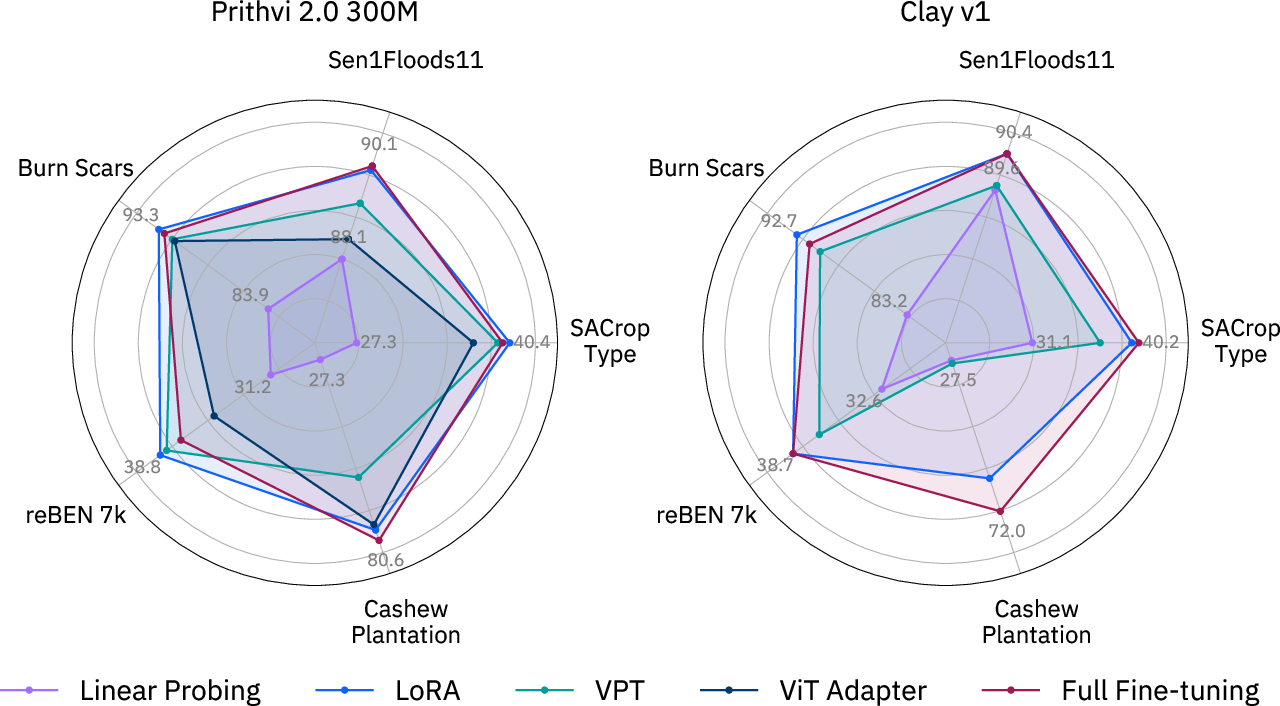
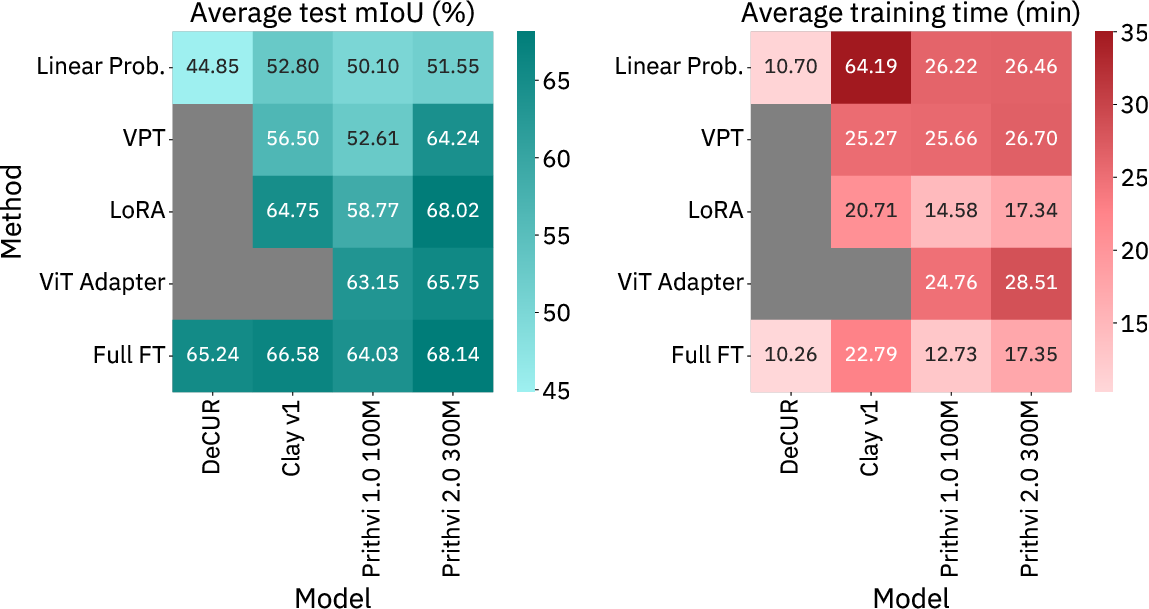
- LoRA often matches or beats full fine-tuning, especially on the big Prithvi 2.0 model. It uses only about 1–2% extra parameters and saves memory, making training more accessible on common GPUs.
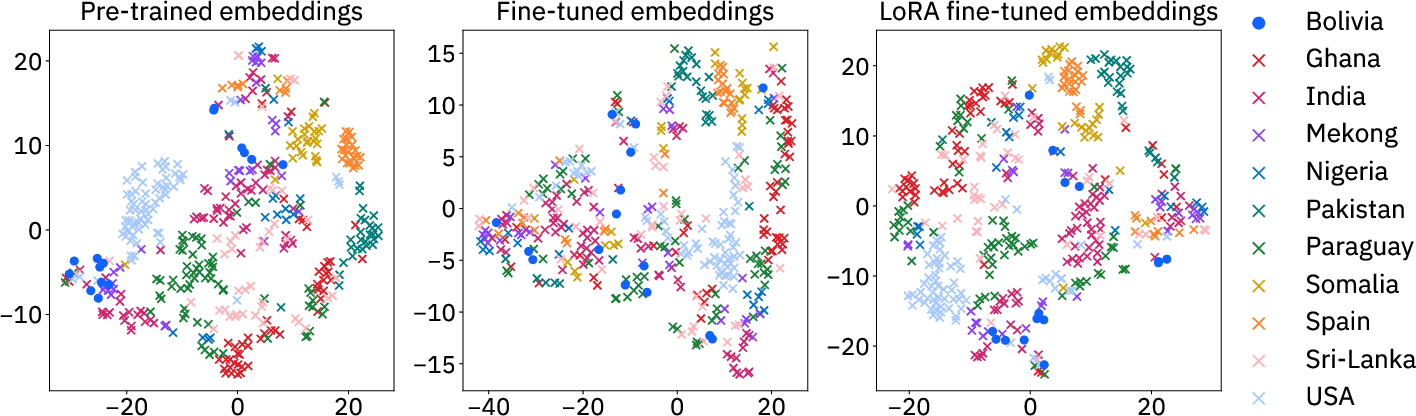
- Generalization to new regions improved with LoRA for Prithvi 2.0. In simple terms: models fine-tuned with LoRA tended to work better on places they hadn’t seen before.
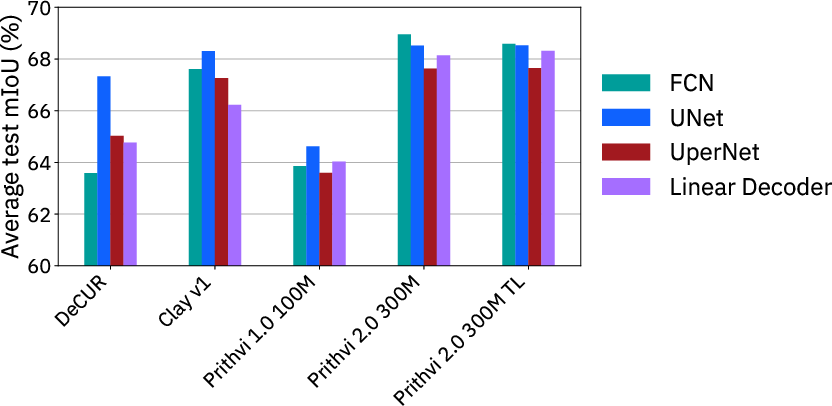
- UNet is the most reliable decoder choice. It consistently produced strong scores and cleaner, smoother maps than simpler decoders (which can look patchy).
- Full fine-tuning can sometimes “forget” useful pre-trained knowledge and hurt generalization. PEFT (especially LoRA) helps avoid this.
- Metadata (extra info like location or time) wasn’t necessary for getting good fine-tuning results in their tests.
- Bigger, better-pretrained models (like Prithvi 2.0) generally performed best across tasks.
These results are important because they show you don’t need huge computing resources to get top performance. That opens the door for more teams—like local governments, NGOs, or schools—to use and adapt powerful geospatial AI.
What does this mean for the future?
- Faster, cheaper adaptation: With PEFT—especially LoRA—organizations can quickly tailor large Earth observation models to new tasks (like a sudden flood or wildfire) without needing expensive hardware.
- Better maps, faster decisions: Strong decoders like UNet produce cleaner maps, which helps responders and planners trust the outputs when acting in the real world.
- Wider access through open tools: The authors put all their models and methods into an open-source toolkit called TerraTorch. This makes it easier for others to use these techniques right away.
- Ongoing challenge: Working well in totally new regions is still hard. PEFT helps, but there’s room to improve. Future work can test more models, more places, and more tasks to build even better generalization.
In short: Fine-tune smarter, not harder. By adjusting just a little (with PEFT), you can get great results, save time and memory, and make powerful Earth-monitoring tools usable by more people.
Collections
Sign up for free to add this paper to one or more collections.