- The paper introduces Softpick, a rectified softmax alternative that eliminates attention sink and massive activations by decoupling normalization from strict probabilistic constraints.
- The paper demonstrates that Softpick produces genuinely sparse attention maps and significantly improves quantization robustness, especially at low-bit precisions.
- The paper reveals that while Softpick matches softmax in medium-scale models, its performance at larger scales and long-context scenarios indicates a need for further tuning.
Softpick: Eliminating Attention Sink and Massive Activations with Rectified Softmax
Introduction and Motivation
Transformer architectures rely on the softmax function to normalize attention scores, which yields dense, sum-to-one attention distributions. However, recent analyses have illuminated two pathological behaviors intrinsically linked to softmax-based attention: attention sink—where heads disproportionately attend to semantically weak (often initial) tokens—and massive activations—rare but extreme hidden state outliers that degrade quantization robustness and low-precision training. "Softpick: No Attention Sink, No Massive Activations with Rectified Softmax" (2504.20966) targets both issues by proposing a simple, parameter-free rectified alternative to softmax, maintaining most of softmax's Jacobian structure but decoupling normalization from the strict probabilistic constraints.
Softpick is defined as:
Softpick(x)i=∑j=1N∣exj−1∣+ϵReLU(exi−1)
where ϵ is a small constant for safety, and the formulation is numerically stabilized by shifting logits with their max as in softmax implementations. The function introduces several key deviations:
- Rectified Numerator: The ReLU allows sparse, exactly-zero attention scores for negative-logit positions (irrelevant tokens), in contrast to softmax's dense (positive, nonzero) scores.
- Absolute-Value Denominator: This preserves nonzero gradient flow even for "off" positions and prevents vanishing derivatives for negative logits.
- Non-sum-to-one Output: The normalization is no longer strictly probabilistic, eliminating the pressure that induces attention sink.
This formulation enables sparsity, richer head specialization, and removes the enforced coupling between attended and non-attended tokens' scores.
Empirical Analysis: Training, Benchmarks, and Activation Statistics
Convergence and Training Dynamics
Both 340M and 1.8B parameter transformer models were trained from scratch using softmax and softpick for direct comparison. Training losses and gradient norms for the 340M case are nearly identical, indicating that softpick largely preserves softmax's favorable training geometry and optimizer compatibility.

Figure 1: Training loss and gradient norm during training of 340M models.
Notably, while gradient magnitudes for softpick are initially higher, they plateau smoothly and do not induce instability when using standard gradient clipping.
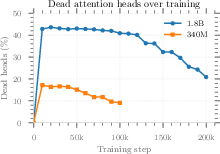
On general language modeling and reasoning tasks (ARC-e, Lambada, PIQA, SciQ, Wikitext-2), softpick and softmax achieve near-equal performance at 340M. At 1.8B, softpick underperforms across most metrics, suggesting nontrivial scaling or hyperparameter phenomena that inhibit effective capacity at higher scale (see Section: Scalability).
Quantization Robustness
Strong numerical claim: Softpick enables dramatically more robust quantization, especially at 2–4 bits, across post-training quantization methods (BNB, GPTQ, HQQ).
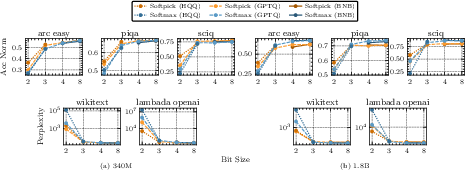
Figure 2: Quantization results of softmax vs. softpick across model scales (2, 3, 4, & 8-bit precision).
For 340M models, softpick-quantized variants outperform softmax by up to 6 points in accuracy and avoid catastrophic loss of function at aggressive bit reductions. The improvement is less pronounced but still present at larger scales and lower bit depths, despite softpick's lower starting accuracy at 1.8B.
Activation Distribution and Attention Sink Metrics
Softpick yields genuinely sparse attention maps, with >99% zeros in the 340M model and >95% in 1.8B—orders of magnitude increase vs. softmax, which only returns zeros via numerical underflow.
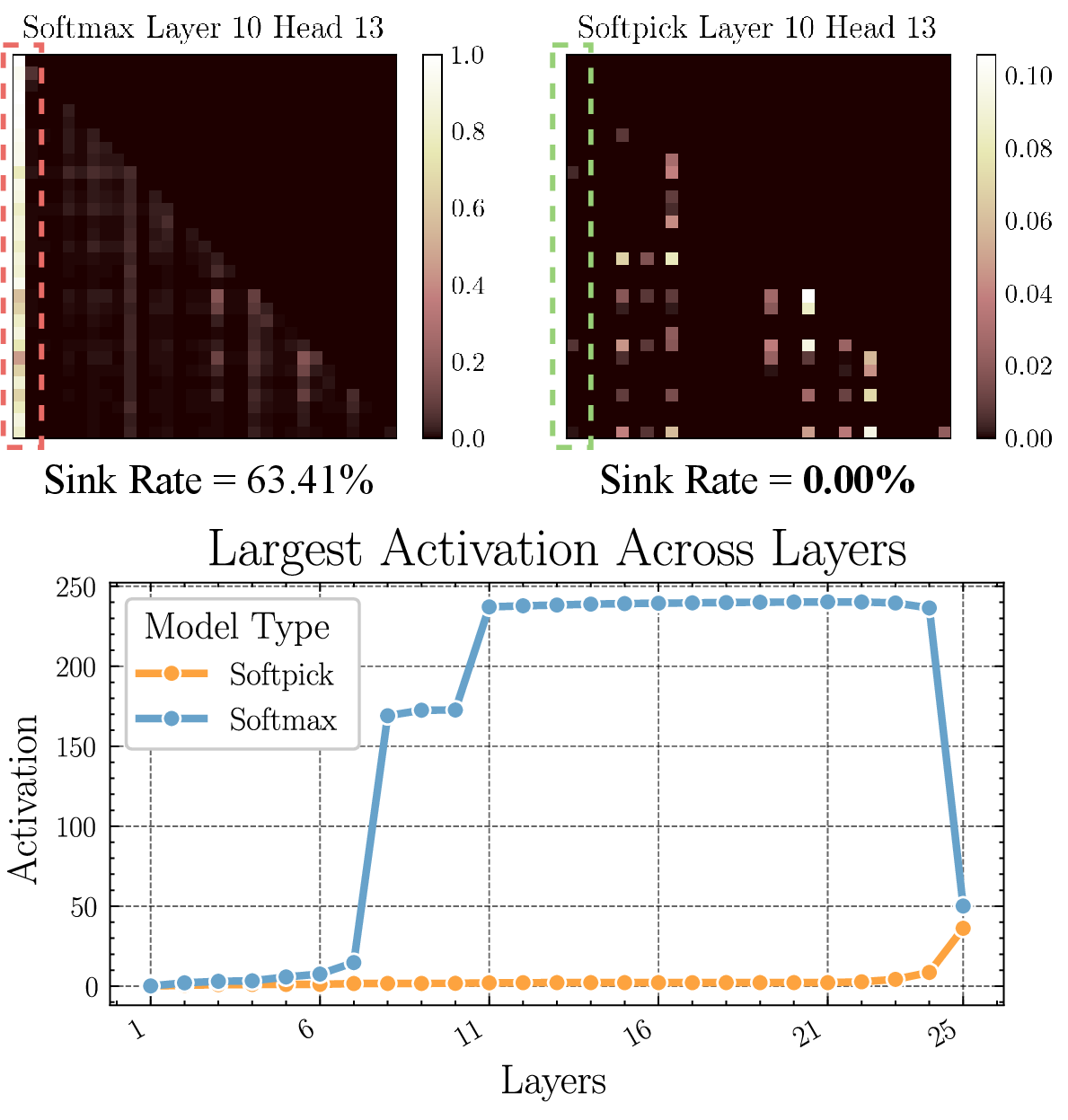
Figure 3: (Top) Comparison between the attention maps when using softmax vs softpick and overall sink rate of the 340M models. (Bottom) Largest hidden state activation per layer of the 340M models.
Critically, sink rates (proportion of heads assigning large scores to the BOS token) fall from >60% (softmax) to exactly zero with softpick, eliminating one of the most persistent attention artifacts. Activation kurtosis in hidden states falls by 100x, and maximum hidden activation values are reduced by an order of magnitude.
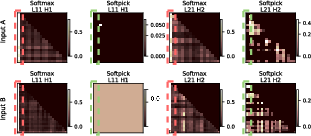
Figure 4: Attention maps of softmax and softpick 340M models on 2 different input texts. Two heads are visualized: Head 1 of Layer 11 and Head 2 of Layer 21.
Softpick attention heads are either sharply selective to relevant position patterns or completely dormant, enabling more interpretable and prunable head behavior.
Theoretical Implications and Head Specialization
The softpick Jacobian retains the desirable training properties of softmax for positive-scoring positions, but its rectification and non-conservation of normalization permit heads to output null (zero) attention—with persistent gradient flow enabling dead heads to recover if needed. This mechanism aligns with new lines of research into active-dormant head specialization and pruning.
Softpick's compatibility with single-pass FlashAttention kernels further ensures its utility in high-efficiency large-scale environments.
Scalability and Limitations
Despite its merits at moderate scale, two limitations arise:
Practical Implications and Future Research Directions
By eliminating activation outliers and enforcing sparsity at the attention level, softpick obviates the need for complex outlier-aware quantization and enables more aggressive, efficient hardware-friendly low-precision training. The sparsity acts as a lever for optimizing attention computations—potentially accelerating inference via sparse matrix multiplies and unlocking more assertive head/row pruning strategies.
Interpretability is also enhanced as legible, zero-sparse attention maps replace blurry, sink-dominated ones, facilitating model analysis and potentially improving safety audits. The softpick paradigm generalizes to vision and multimodal transformers, as massive activation artifacts are a cross-domain phenomenon.
Conclusion
Softpick provides a simple, parameter-free mechanism to eliminate two central softmax-related pathologies: attention sink and massive activations. While performance matches softmax in medium-scale settings and improves quantization robustness, scaling and long-context efficacy require further investigation. The promising properties of softpick—sparsity, interpretability, prunability, and quantization-friendliness—suggest rich opportunities for future architectural and theoretical advances in transformer-based models.