- The paper introduces Synergy-CLIP, which extends CLIP by integrating visual, textual, and audio data for robust multi-modal learning.
- It leverages the novel VGG-sound+ dataset to achieve balanced modality representation, enhancing zero-shot classification and Missing Modality Reconstruction.
- Experimental results demonstrate superior reconstruction accuracy and downstream performance, underscoring its potential in comprehensive multi-modal AI applications.
"Synergy-CLIP: Extending CLIP with Multi-modal Integration for Robust Representation Learning" (2504.21375)
Abstract
"Synergy-CLIP" proposes a novel multi-modal framework extending the contrastive language-image pre-training (CLIP) to integrate visual, textual, and audio modalities. By aligning and capturing latent information across these modalities equally, Synergy-CLIP aims to advance robust multi-modal representation learning. The study introduces the VGG-sound+ dataset, crafted to optimize tri-modal learning by offering balanced visual, textual, and audio data representation. Synergy-CLIP demonstrates enhanced performance on tasks such as zero-shot classification and introduces the Missing Modality Reconstruction (MMR) task, illustrating its capacity to process incomplete data. The research provides substantial groundwork for further exploration in multi-modal learning and AI.
Introduction
Recent advancements in artificial intelligence have underscored the pivotal role of multi-modal learning, harnessing diverse data modalities like vision, text, and audio to tackle complex problems. Traditional approaches have largely fixated on bimodal interactions, notably image-text pairs, leaving tri-modal or higher-level integration underexplored due to dataset construction challenges. Synergy-CLIP addresses this gap by extending CLIP to accommodate additional modalities, thus fostering richer multi-modal representation learning.
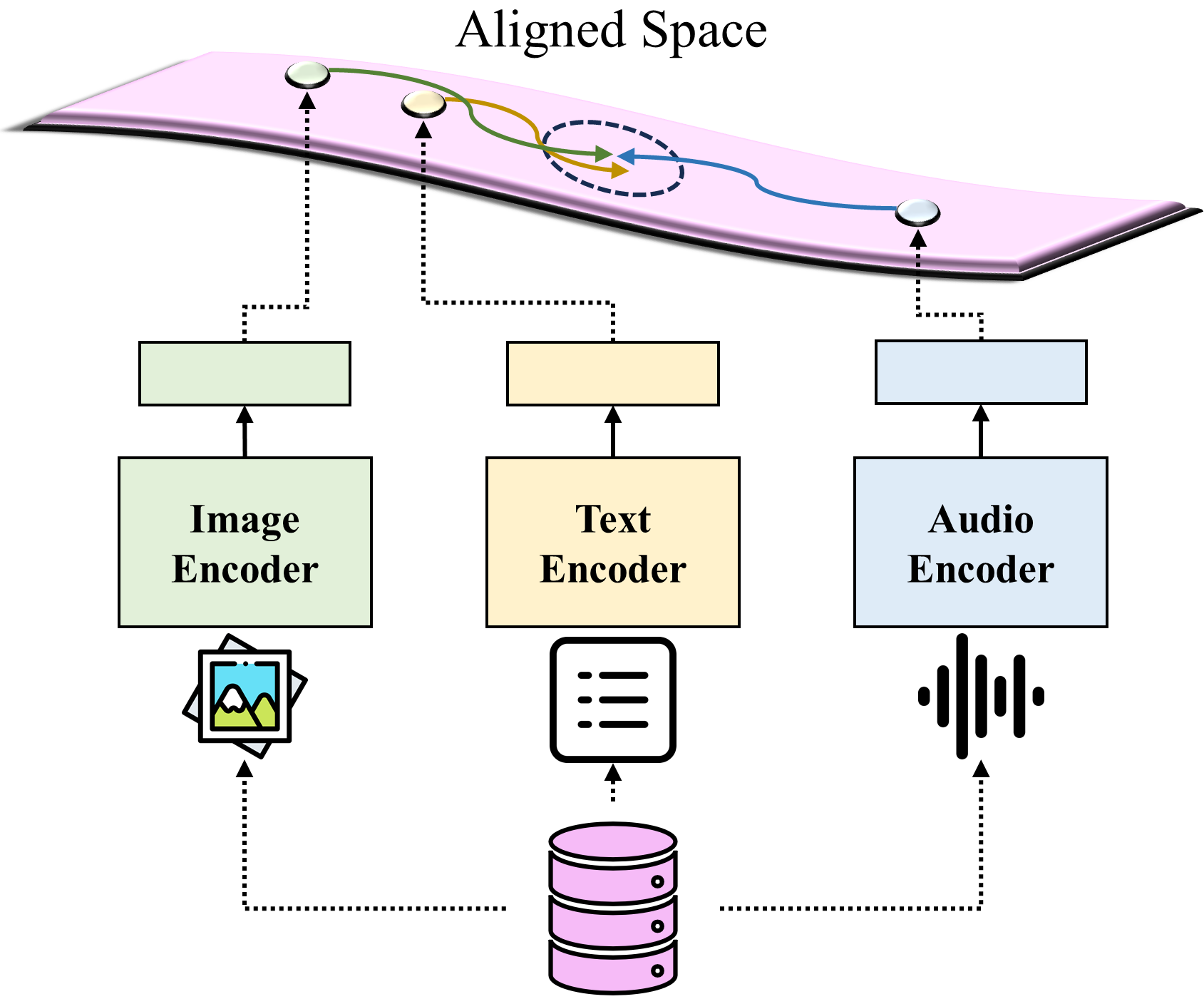
Figure 1: Mapping to aligned space for cross-modality. The aligned space acts as a convergence point for correlating different modal inputs and leveraging them for further multi-modal processing.
The proposed framework capitalizes on a novel dataset, VGG-sound+, designed to balance tri-modal interactions. Synergy-CLIP not only excels in standard tasks but also introduces the MMR task, which reconstructs missing data modalities. This approach lays the foundation for sophisticated multi-modal AI systems that emulate human cognitive capabilities.
Synergy-CLIP Framework
Synergy-CLIP integrates a tri-modal dataset, VGG-sound+, to equally scale visual, textual, and audio data through pre-training. This dataset facilitates the alignment of learned representations, enabling the model to capture interactions among the modalities effectively, fostering a holistic approach to multi-modal integration.
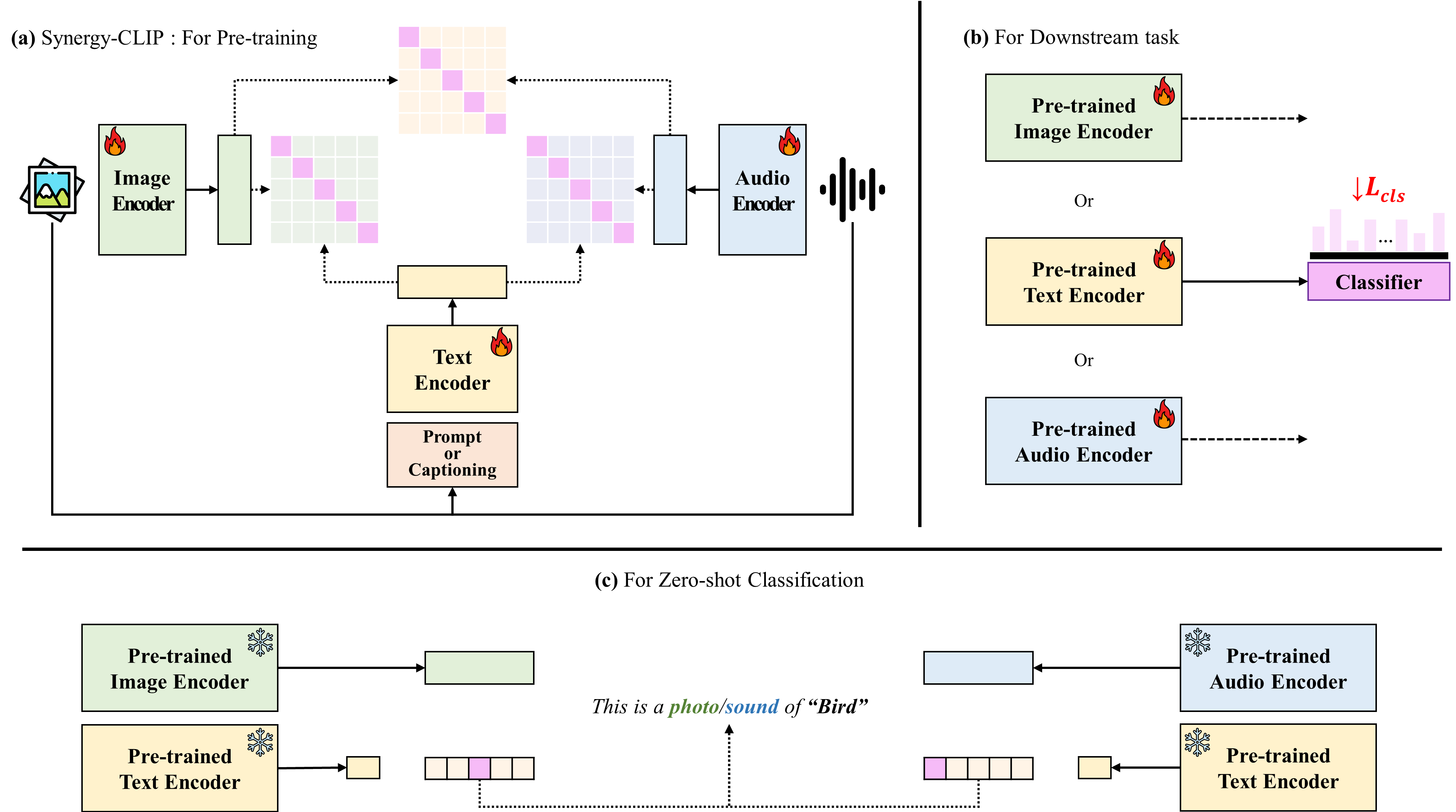
Figure 2: Illustration of Synergy-CLIP framework. (a) Pre-training of Synergy-CLIP involves inputs from three modalities: image, text, and audio. During pre-training, representations extracted by each modality-specific encoder are aligned, utilizing contrastive loss to facilitate this alignment. The pre-trained encoders of Synergy-CLIP are subsequently fine-tuned for modality-specific downstream tasks (b) as well as zero-shot classification (c), enabling the framework to adaptively leverage aligned representations across various AI tasks.
VGG-Sound+ Dataset
VGG-sound+ is constructed to supply equal tri-modal representation, overcoming inherent scaling challenges due to dataset biases or modality imbalance. This dataset is pivotal for performing advanced tasks like zero-shot classification, validating Synergy-CLIP’s representational prowess across varying modalities, highlighting its adaptability in AI applications.
Missing Modality Reconstruction Task
Synergy-CLIP introduces MMR, a task that reconstructs a missing modality by leveraging available data, echoing human-like sensory processing. The model employs a transformer-based encoder-decoder framework tailored for image, text, and audio modalities, reconstructing sensory data when incomplete.
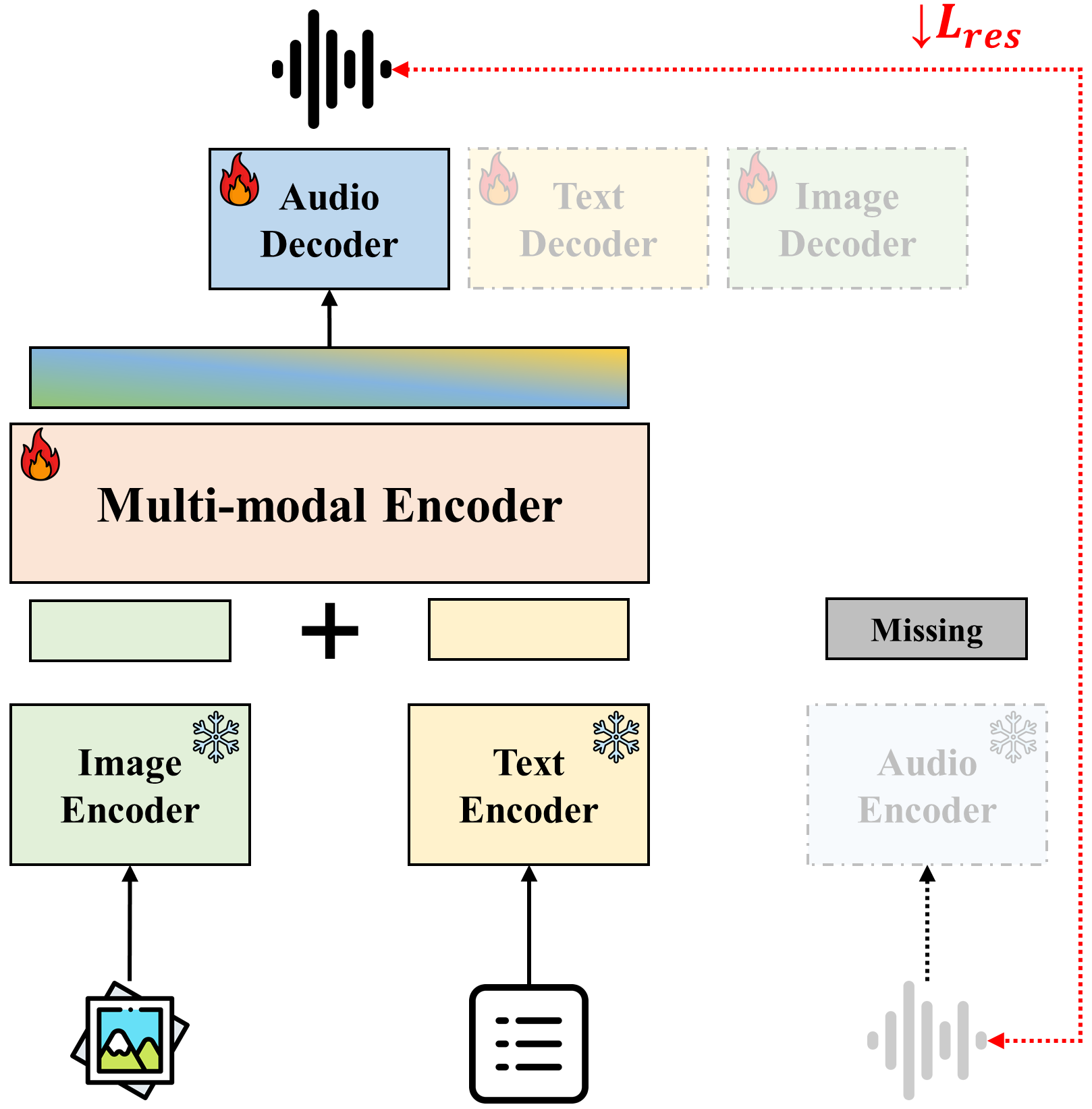
Figure 3: Framework for the Missing Modality Reconstruction (MMR) task, this figure illustrates the use of a multi-modal encoder and a missing modality decoder to reconstruct the audio modality using representations extracted by Synergy-CLIP.
Modality Reconstruction and Evaluation
Through comprehensive evaluations, Synergy-CLIP achieves significant improvements in reconstruction accuracy, specifically in visual representation recovery, offering profound implications for handling missing or incomplete data in practical applications, enhancing model robustness and utility.
Experimental Results
Synergy-CLIP exhibits superior performance in zero-shot classification and standard downstream tasks (e.g., text, vision, and audio), validating the effectiveness of its tri-modal integration. These results affirm the enhanced synergy among modalities fostered by the balanced dataset and advanced framework design.
Figure 4: A qualitative example of the MMR task. In this evaluation, the text reconstruction scenario has been excluded (as it is a token classification). The figure illustrates the reconstruction results of the large caption model, which exhibits the best performance as per quantitative evaluations.
Conclusion
Synergy-CLIP represents a significant advancement in multi-modal AI, achieving balanced integration of visual, textual, and audio modalities. Its frameworks effectively address tri-modal representation learning and demonstrate robust performance in task-specific applications, shaping a foundation for emulating comprehensive human-like sensory capabilities.
Future research may explore augmenting Synergy-CLIP with additional modalities to further refine inter-modal synergy and expand its applicability across diverse domains, paving the way for breakthroughs in areas such as adaptive learning, healthcare, and digital interaction systems.