- The paper presents a Structured Text Representation that captures both spatial and temporal video dynamics to improve animated ad generation.
- The VAKER pipeline employs a three-stage process with LoRA-adapted LLMs for precise layout control and clear text integration in video ads.
- Quantitative metrics, such as Fréchet Motion Distance, validate VAKER's superior performance in motion quality, layout clarity, and reduced failure rates.
Generating Animated Layouts as Structured Text Representations
Introduction
The paper "Generating Animated Layouts as Structured Text Representations" (2505.00975) introduces an innovative approach to text-to-video advertisement generation, termed Animated Layout Generation. Despite advances in text-to-video models, generating precise, controlled animated graphics in video ads poses significant challenges, particularly due to issues with text readability and precise animation control. This research aims to address these issues by introducing Structured Text Representation, a hierarchical approach that leverages LLMs to create dynamic and visually coherent video advertisements.
Structured Text Representation
The core innovation of this work is the Structured Text (ST) Representation, which captures both spatial and temporal dynamics of video layouts. By encoding video elements as hierarchical text sequences, the ST Representation effectively integrates with LLMs. This text-based approach not only ensures the clarity and spatial accuracy of on-screen text but also facilitates the precise control over animations required in complex video advertisements.
The ST Representation encodes a video as a 4-tuple consisting of Banner, Foreground, Background, and Animation components, each described by structured forms such as JSON, enabling systematic organization and transformation of visual data into text sequences.
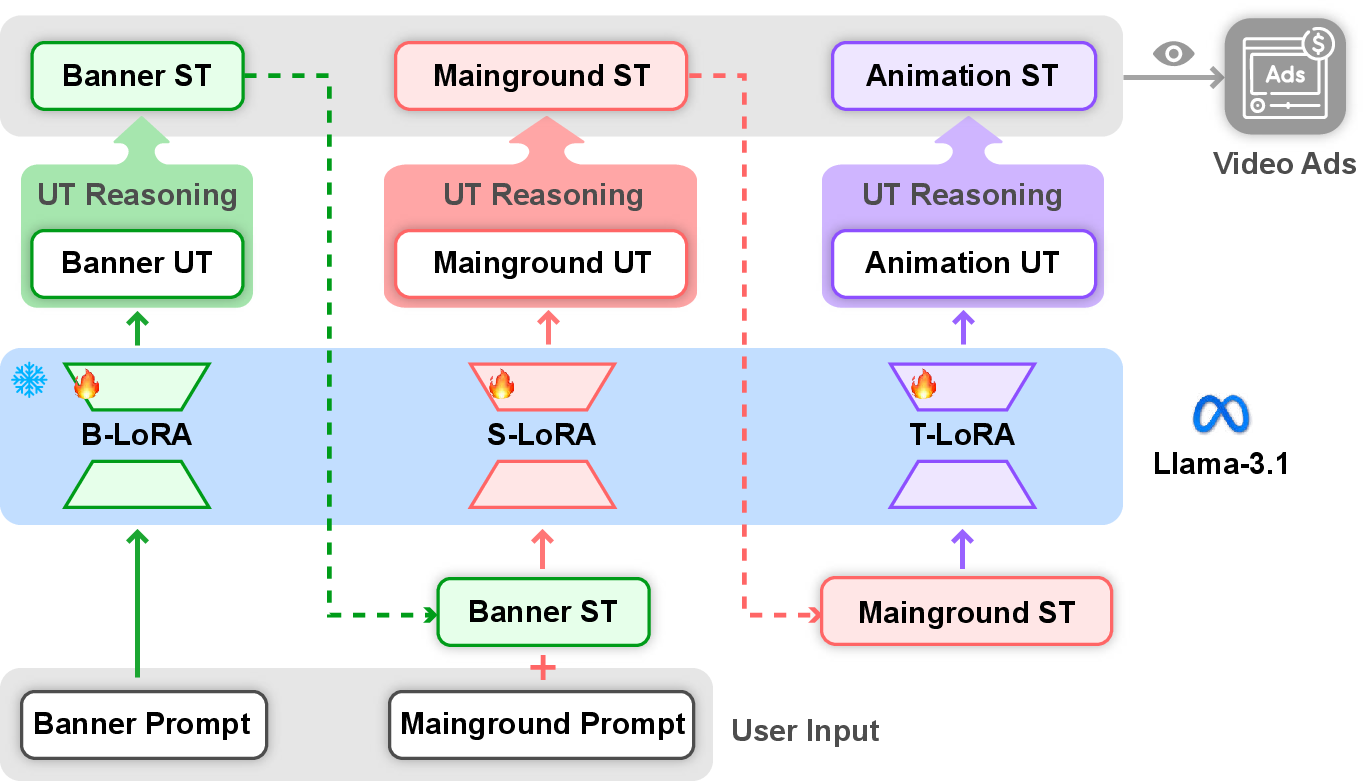
Figure 1: Overview of VAKER. VAKER takes text input from users to generate video advertisements using Structured Text Representations.
VAKER: Video Ad maKER
VAKER, the proposed video ad generation pipeline, operationalizes the ST Representation through a three-stage process: Banner, Mainground, and Animation. Each stage employs LoRA-adapted LLMs to interpret and transform user prompts into structured specifications for video ads. The Banner stage determines the spatial layout, Mainground integrates text and visual elements, and the Animation stage defines the dynamic trajectories within the ad.
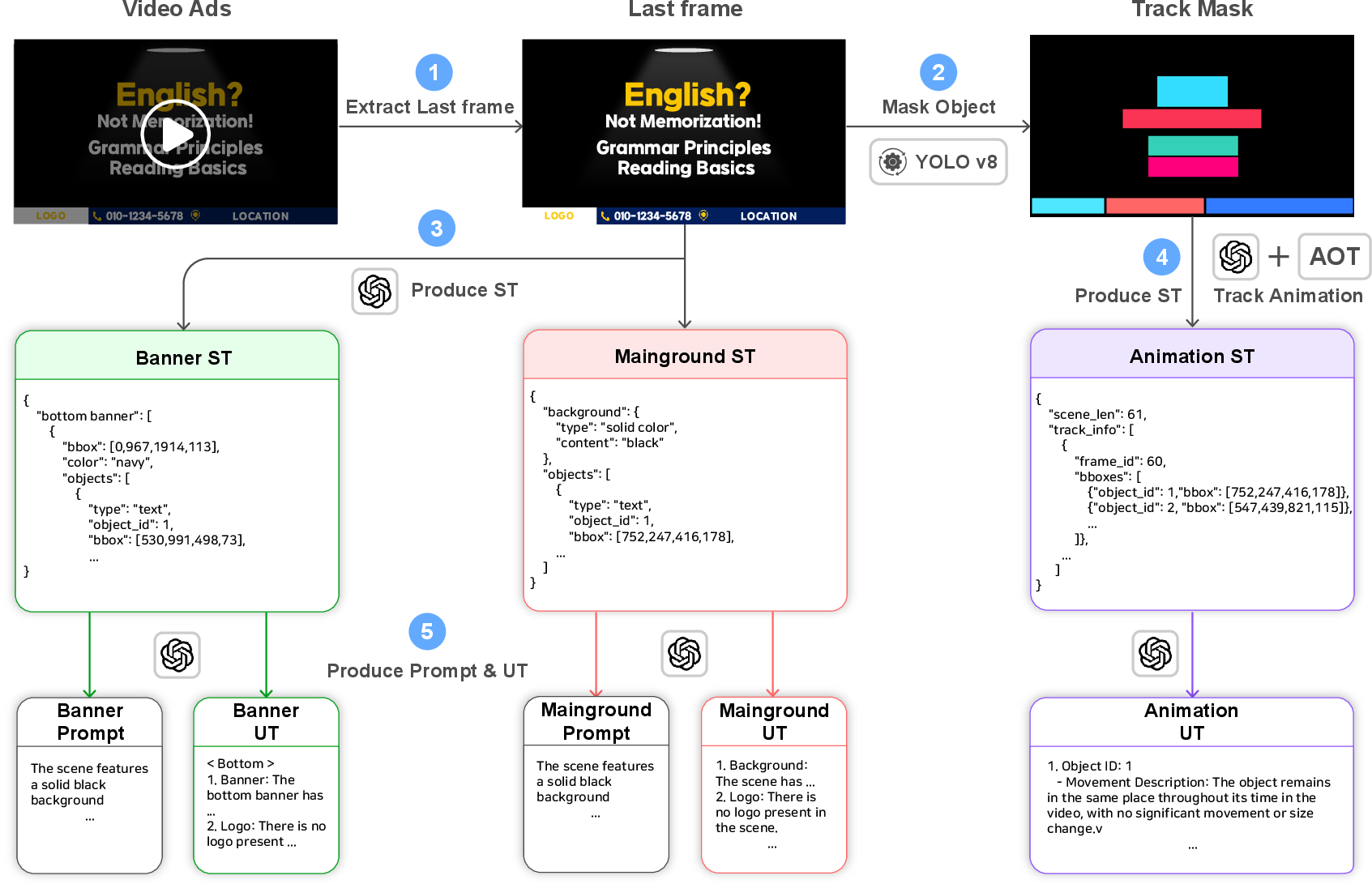
Figure 2: Video Advertisement Dataset Construction Pipeline. This automated pipeline generates training data for VAKER by converting video ads to Structured Text and Unstructured Text Reasonings.
Qualitative and Quantitative Evaluation
The research showcases VAKER's capabilities through qualitative assessments, demonstrating its ability to produce diverse animations with precise text integration (Figure 3). Comparisons with diffusion models highlight VAKER's superior performance in rendering clear, readable text (Figure 4), while its effectiveness in generating structured dynamic layouts is evidenced against graphic layout generation models (Figure 5).
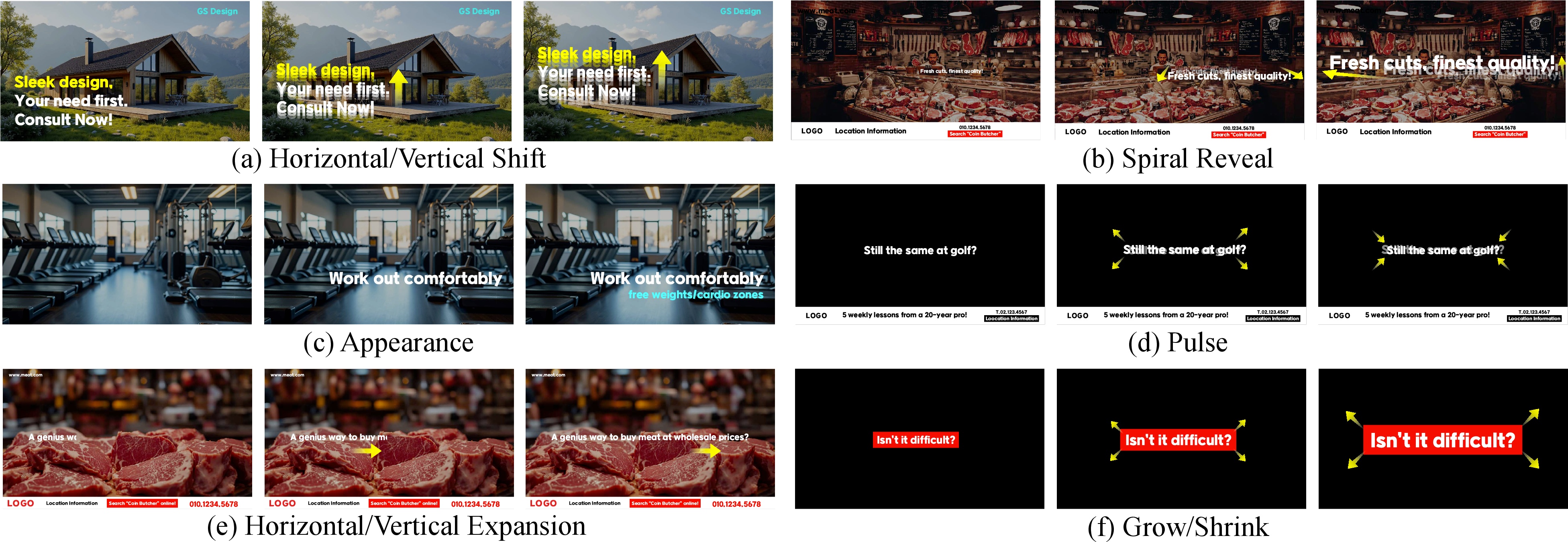
Figure 3: Qualitative examples of animations generated by VAKER, illustrating its diverse animation capabilities.
Quantitative analysis, using metrics like Fréchet Motion Distance (FMD), reveals VAKER's proficiency in generating realistic motion and adhering to layout prompts. It consistently outperforms baselines in motion quality, layout clarity, and lower failure rates in generating invalid layouts (Table 1).
Implications and Future Work
The research introduces a novel framework that extends beyond traditional design into dynamic video content, promising enhanced video advertisement creation with greater control over visual intricacies. Future investigations could explore more sophisticated animation patterns and improve data conversion fidelity, further broadening the scope of automated content creation in multimedia applications.
Conclusion
The paper presents a significant contribution to the field of automated video advertisement generation by introducing ST Representations and the VAKER pipeline. This approach not only enhances the control over dynamic graphical elements but also aligns closely with existing LLM capabilities, setting the stage for future advancements in text-to-video synthesis technologies. Through its innovative design and robust performance, this research stands as a testament to the potential of structured text-based approaches in overcoming longstanding challenges in video advertisement generation.