- The paper introduces CityNavAgent, which integrates open-vocabulary perception, hierarchical semantic planning, and a global memory module for effective aerial vision-and-language navigation.
- The hierarchical planning module decomposes instructions into landmark-, object-, and motion-level sub-goals, reducing planning complexity in continuous urban 3D spaces.
- Experimental results demonstrate significant performance gains over prior methods, with ablation studies confirming the essential roles of semantic mapping and memory graph modules.
CityNavAgent: Hierarchical Semantic Planning and Global Memory for Aerial Vision-and-Language Navigation
Introduction and Motivation
CityNavAgent addresses the aerial vision-and-language navigation (VLN) problem, where an embodied agent (e.g., a drone) must interpret natural language instructions and navigate complex urban environments in continuous 3D space. Unlike ground-level VLN, aerial VLN presents unique challenges: the absence of predefined navigation graphs, exponentially expanding action spaces for long-horizon planning, and highly variable semantic density in urban scenes. Existing methods, primarily designed for indoor or ground-level navigation, are insufficient for these settings due to their reliance on discrete topological graphs and limited semantic reasoning capabilities.
System Architecture
CityNavAgent is composed of three principal modules: an open-vocabulary perception module, a hierarchical semantic planning module (HSPM), and a global memory module. The open-vocabulary perception module leverages LLMs and vision foundation models to extract instruction-relevant objects and build a semantic point cloud of the environment. HSPM decomposes navigation instructions into hierarchical sub-goals (landmark-level, object-level, and motion-level), reducing planning complexity and enabling progressive goal achievement. The global memory module stores historical trajectories as a topological graph, facilitating efficient motion planning toward previously visited targets.
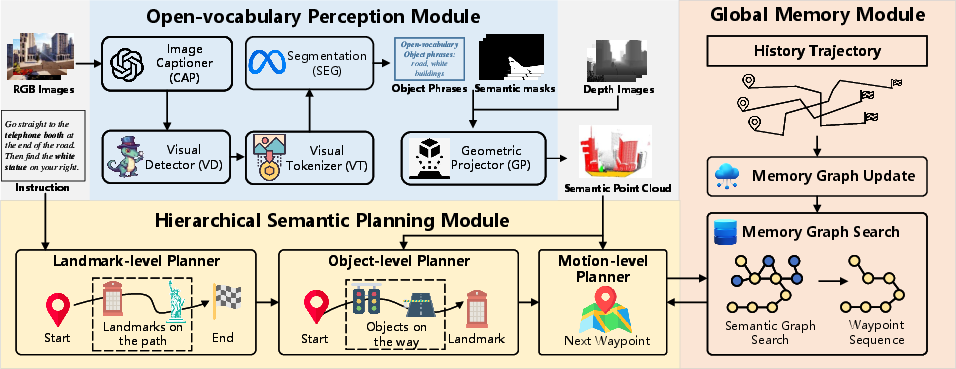
Figure 1: CityNavAgent consists of three key modules: open-vocabulary perception, hierarchical semantic planning, and global memory for trajectory storage and reuse.
Open-Vocabulary Perception
The perception module utilizes panoramic RGB-D observations. Scene semantics are extracted via an LLM-based captioner (e.g., GPT-4V) and grounded using a visual detector (GroundingDINO). Semantic masks are generated for detected objects, which are then projected into 3D space using camera intrinsics and agent pose, resulting in a local semantic point cloud. This representation enables robust cross-modal grounding and spatial reasoning, critical for urban environments with high object variety and dynamic semantic density.
Hierarchical Semantic Planning
HSPM operates at three levels:
- Landmark-level: LLM parses instructions to extract an ordered sequence of landmark phrases, serving as high-level sub-goals.
- Object-level: For each sub-goal, the LLM reasons about the most relevant visible object regions (OROI) in the current panorama, leveraging commonsense knowledge to bridge gaps when landmarks are not directly observable.
- Motion-level: The agent computes waypoints by averaging the coordinates of semantic point cloud points corresponding to the selected OROI, then decomposes the path into executable low-level actions.
This hierarchical decomposition narrows the action space and improves alignment with instructions, mitigating error accumulation in long-horizon planning.
Global Memory Module
The global memory module constructs a 3D topological graph from historical successful trajectories. Nodes store both waypoint coordinates and panoramic observations; edges are weighted by spatial distance. The memory graph is incrementally updated and merged with new trajectories, with connectivity established via proximity thresholds. During navigation, when the agent reaches a node in the memory graph, it leverages graph search (Dijkstra-based, augmented with LLM-based semantic similarity scoring) to efficiently plan paths traversing the remaining sub-goals.
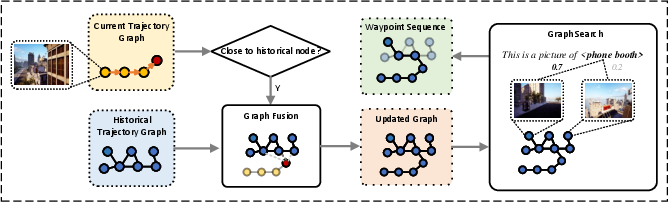
Figure 2: The memory module fuses current and historical trajectory graphs, searching for paths with maximal semantic similarity to instruction landmarks.
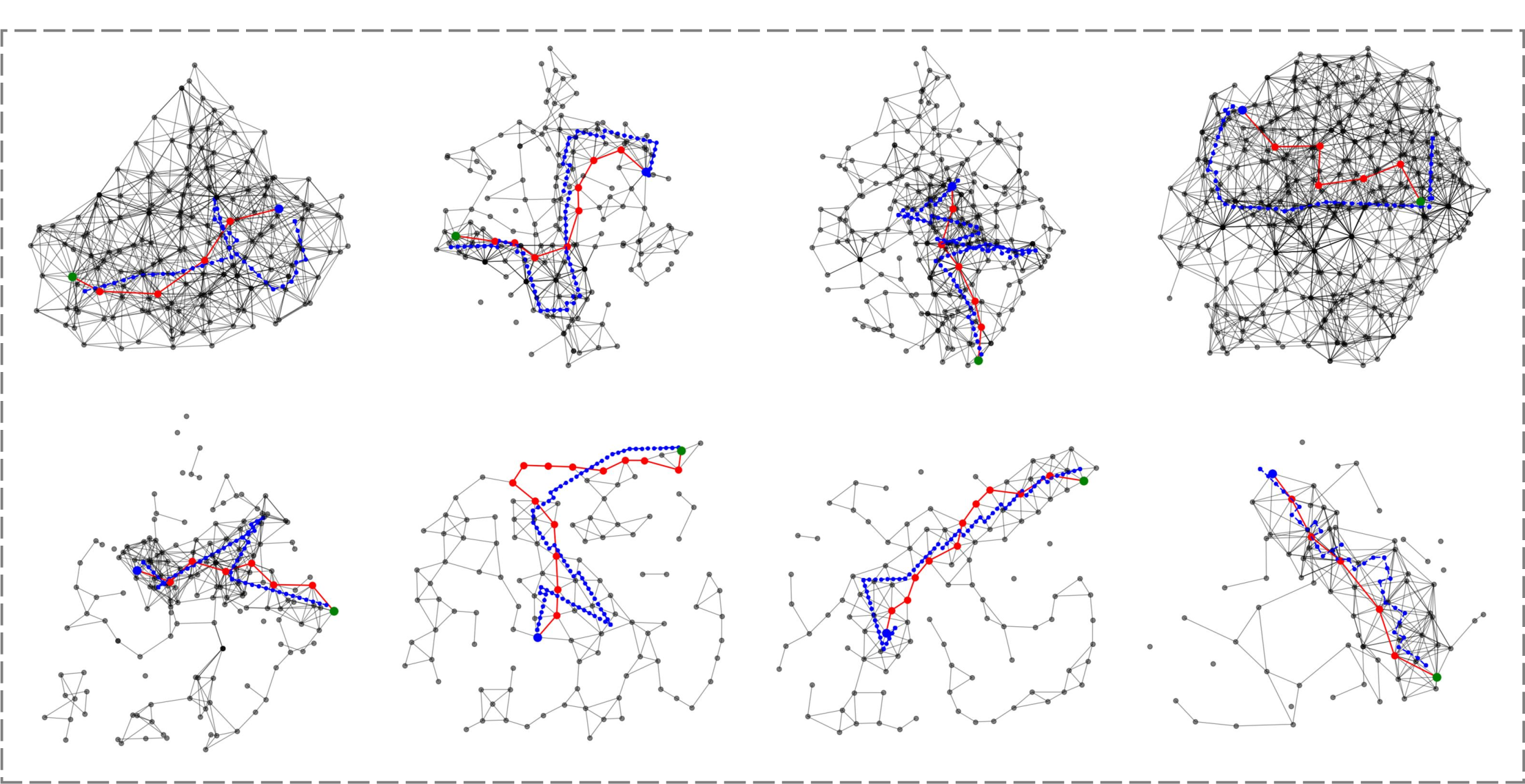
Figure 3: Memory graphs in different scenes; node disconnections reflect long distances between historical trajectories.
Experimental Results
CityNavAgent is evaluated on AirVLN-S and a fine-grained AirVLN-Enriched benchmark, both simulating urban environments with diverse objects and long navigation paths. Metrics include Success Rate (SR), Oracle Success Rate (OSR), Navigation Error (NE), SPL, and SDTW.
Qualitative Analysis
CityNavAgent demonstrates superior instruction-following and path efficiency. The hierarchical planning enables the agent to reason about invisible landmarks via semantic associations (e.g., inferring the location of an obelisk by exploring areas near trees in a park). The memory graph prevents the agent from blind exploration and dead ends, especially in long-range tasks.

Figure 5: Navigation process comparison; CityNavAgent's reasoning process aligns landmarks and semantic objects, outperforming VELMA and LM-Nav.
Failure cases are categorized as instruction ambiguity, perception failure, and reasoning errors. In AirVLN-S, ambiguous instructions dominate failures, while in AirVLN-Enriched, perception failures are more prevalent due to challenging outdoor object detection.

Figure 6: Failure cases; green boxes indicate referred landmarks, red boxes highlight misreferenced landmarks due to ambiguity, perception, or reasoning errors.
Implementation Considerations
- Computational Requirements: The system requires panoramic RGB-D sensing, LLM inference (preferably GPT-4V), and vision foundation models (GroundingDINO, Segment Anything). Memory graph construction and search scale with the number of historical trajectories but are efficiently pruned via spherical subgraph extraction and non-maximum suppression.
- Deployment: While validated in simulation, real-world deployment necessitates robust low-level motion control, self-pose estimation, and latency management. The absence of a backtracking mechanism is a limitation; future work should integrate path recovery strategies.
- Scalability: The modular design allows for incremental expansion of the memory graph and adaptation to new environments. Semantic point cloud construction is parallelizable across panoramic views.
Theoretical and Practical Implications
CityNavAgent demonstrates that hierarchical semantic planning, combined with global memory, is effective for long-horizon navigation in continuous, unstructured environments. The integration of LLMs for instruction parsing and commonsense reasoning bridges the gap between high-level language and low-level action planning. The memory graph approach offers a scalable solution for leveraging historical experience, reducing exploration overhead and improving robustness.
The results suggest that future embodied AI systems should incorporate hierarchical reasoning, open-vocabulary perception, and memory-based planning to handle real-world complexity. The reliance on foundation models and LLMs underscores the importance of multimodal pretraining and prompt engineering for embodied tasks.
Conclusion
CityNavAgent sets a new benchmark for aerial VLN in urban environments by combining open-vocabulary perception, hierarchical semantic planning, and global memory. The system achieves strong numerical improvements over prior methods, with ablation studies confirming the necessity of each module. While simulation results are promising, real-world deployment will require addressing low-level control and path recovery. The architectural principles established here—hierarchical decomposition, semantic grounding, and memory-based planning—are likely to inform future research in embodied navigation and multimodal AI.