- The paper presents a unified hierarchical retrieval framework that balances context granularity and efficiency for multi-hop QA.
- It employs top-down document compression and bottom-up adaptive slice merging to enhance precision and recall across benchmarks.
- Experimental evaluations show significant gains in F1 scores and reduced latency compared to existing retrieval systems.
Multi-Scale Adaptive Context RAG: Hierarchical Retrieval for Long-Context Multi-Hop QA
Overview of the MacRAG Framework
The "MacRAG: Compress, Slice, and Scale-up for Multi-Scale Adaptive Context RAG" (2505.06569) paper addresses limitations in long-context retrieval-augmented generation (RAG) for LLMs, particularly the precision-coverage-computation trade-offs inherent in multi-hop QA over large corpora. The authors propose MacRAG, a hierarchical retrieval system that constructs effective query-adaptive long contexts by combining top-down offline document indexing—via compression and multi-scale chunking—and bottom-up adaptive retrieval with controlled neighbor propagation and merging.
MacRAG operates in two main phases: a hierarchical index construction phase, where documents are chunked, compressed, and sliced before embedding, and a query-time adaptive retrieval phase, which begins with fine-grained slice retrieval and scales up context by merging relevant neighboring chunks and expanding up the hierarchy. This design aims to simultaneously maximize retrieval precision and context coverage while maintaining tractable context length and low latency.
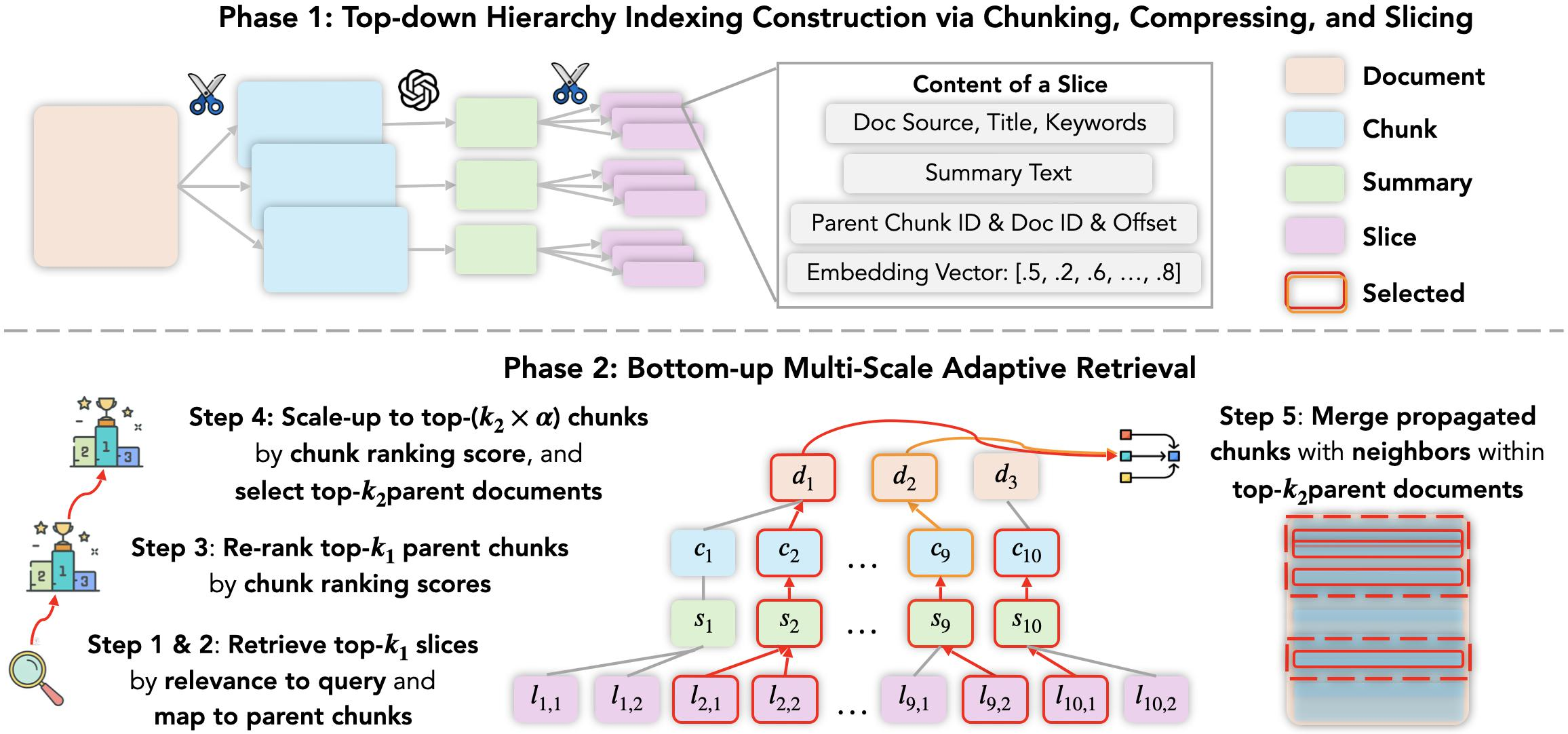
Figure 1: Overview of MacRAG showing both hierarchical document indexing and bottom-up multi-scale adaptive retrieval over the document-chunk-summary-slice hierarchy.
Long-context LLMs such as GPT-4o, Gemini-1.5-pro, and Llama 3 can process hundreds of thousands of tokens and theoretically ingest entire documents. Still, practical issues like the "Lost in the Middle" phenomenon and context window limitations severely impact recall and reasoning for information buried in extended texts. Prior RAG enhancements—abstractive/extractive summarization (RECOMP, LLMLingua), hierarchical retrieval (RAPTOR, SIRERAG, HippoRAG, GraphRAG), and multi-step QA chains—either focus on post-retrieval compression, induce heavy computational overhead, or fragment continuity.
MacRAG differs from existing proposals by introducing a unified system for structure-preserving hierarchical indexing and query-time adaptive retrieval that systematically balances granularity and coverage, integrates multi-view (summary-level and chunk-level) evidence, and facilitates efficient neighbor expansion.
Hierarchical Indexing and Adaptive Retrieval
Top-Down Document Indexing
Documents are chunked with partial overlaps (typically 200–500 tokens per chunk), compressed into summaries via LLM-based abstractive summarization, then further sliced into fine-grained, partially overlapping units (50–200 tokens). Slices, summaries, and optionally original chunks are embedded and stored in a vector DB with complete metadata (document/chunk/slice offsets). This multi-scale index enables rapid cross-granularity retrieval and maintains document structure for efficient mapping during expansion.
Bottom-Up Multi-Scale Adaptive Retrieval
At inference, MacRAG begins with fine-level slice retrieval based on query similarity, maps slices to parent chunks, reranks using cross-encoder relevance scoring, and scales up chunk candidates via the α parameter—incorporating both borderline and highly relevant segments before mapping to corresponding source documents. Neighbor propagation merges h-hop neighboring chunks, reducing fragmentation and preserving essential evidence continuity for multi-hop reasoning.
This process adaptively leverages context expansion based on query complexity—expanding broader neighborhoods for ambiguous/multi-hop queries and maintaining precision for focused queries. Context size is bounded via (k2×α) candidates and hop counts, ensuring scalability.
Experimental Results
MacRAG is evaluated on HotpotQA, 2WikimultihopQA, and Musique (LongBench expansions)—datasets specifically designed to challenge multi-hop reasoning and retrieval in long contexts. Comparative analysis uses Llama-3.1-8B, Gemini-1.5-pro, and GPT-4o, alongside baselines inclusive of RAPTOR and LongRAG in both single/multi-step QA settings.
Key findings:
- F1-Score and Multi-Metric Gains: MacRAG surpasses LongRAG and RAPTOR across F1, Precision, Recall, and Exact Match metrics. For example, on HotpotQA (with GPT-4o, multi-step generation), MacRAG achieves 68.52 vs. LongRAG's 66.20 F1 (+2.32 absolute, +3.5% rel.), and on Musique, delivers +6.26 F1 over LongRAG (+14.3% rel.).
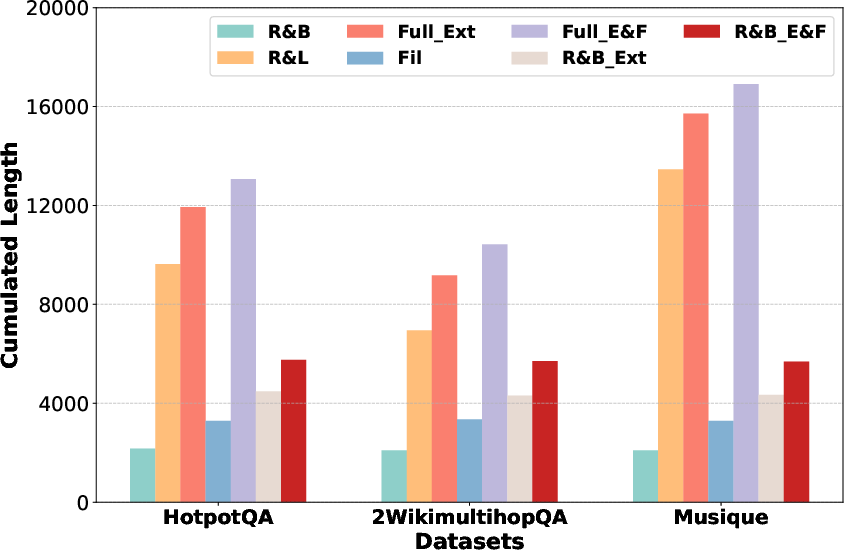
- Stable Performance Across Generation Modes: Gains are upheld over seven distinct single/multi-step variants (retrieval-base, full extraction, filtering, chunk/document expansion), as illustrated below.
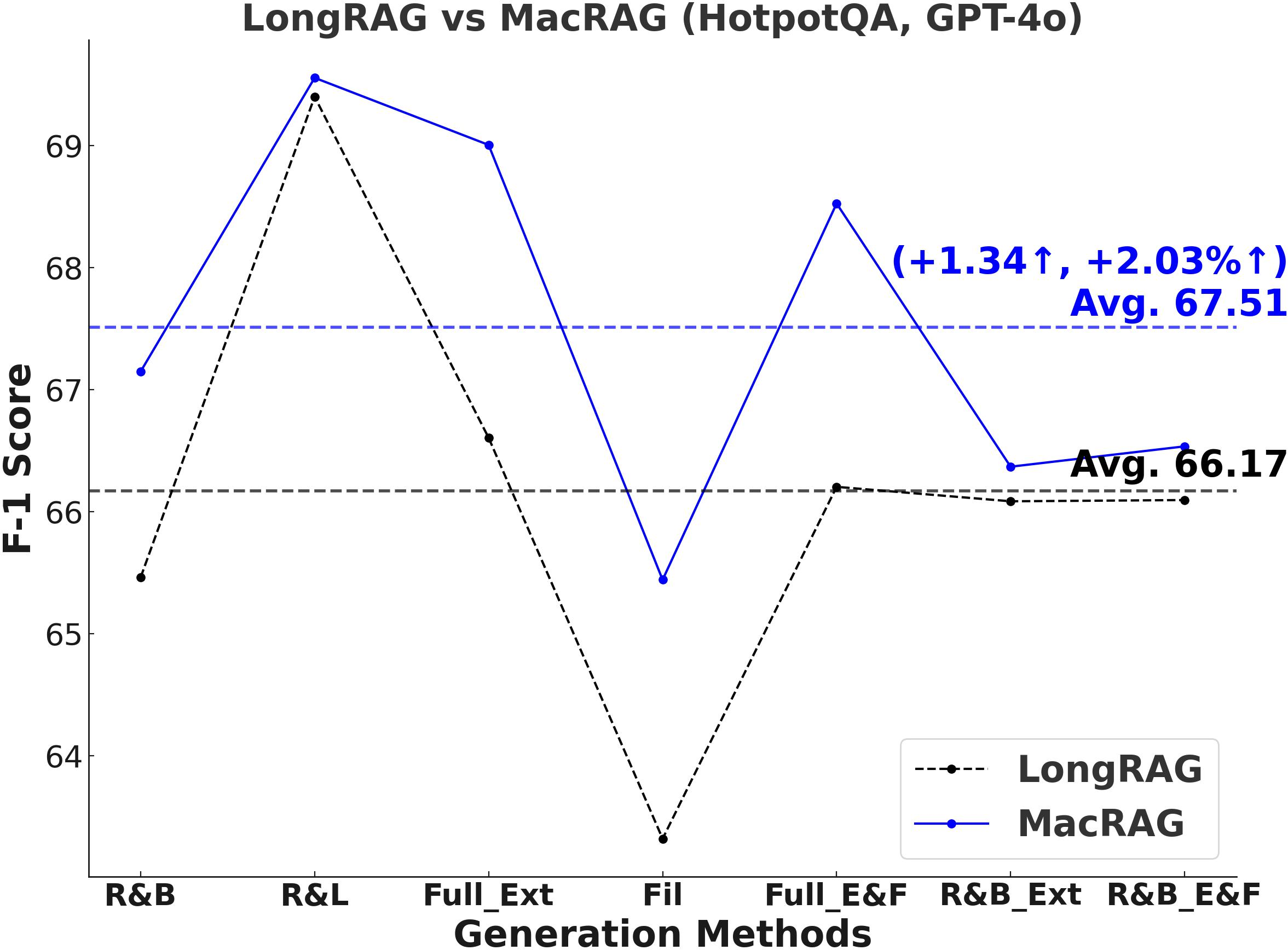
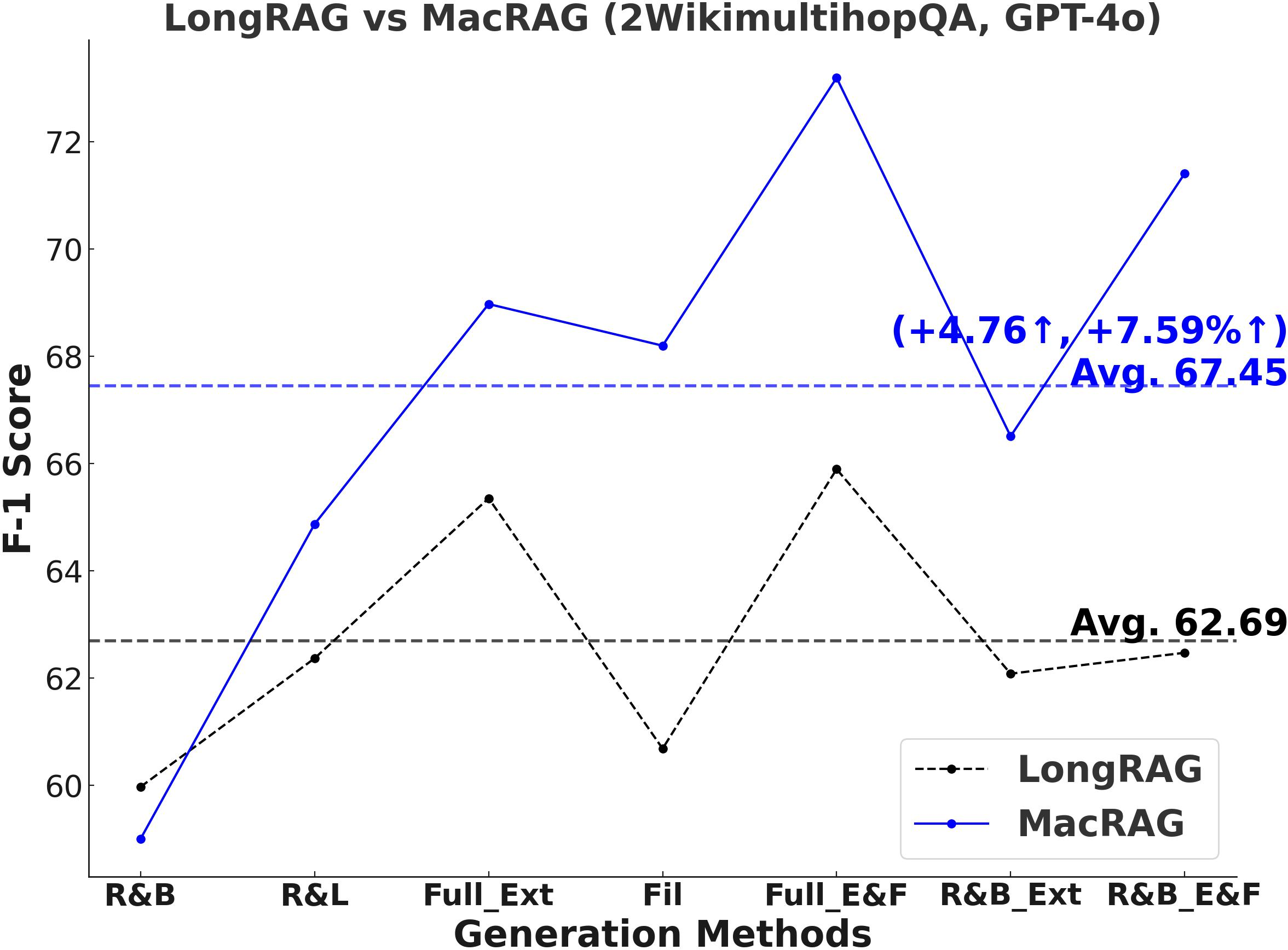
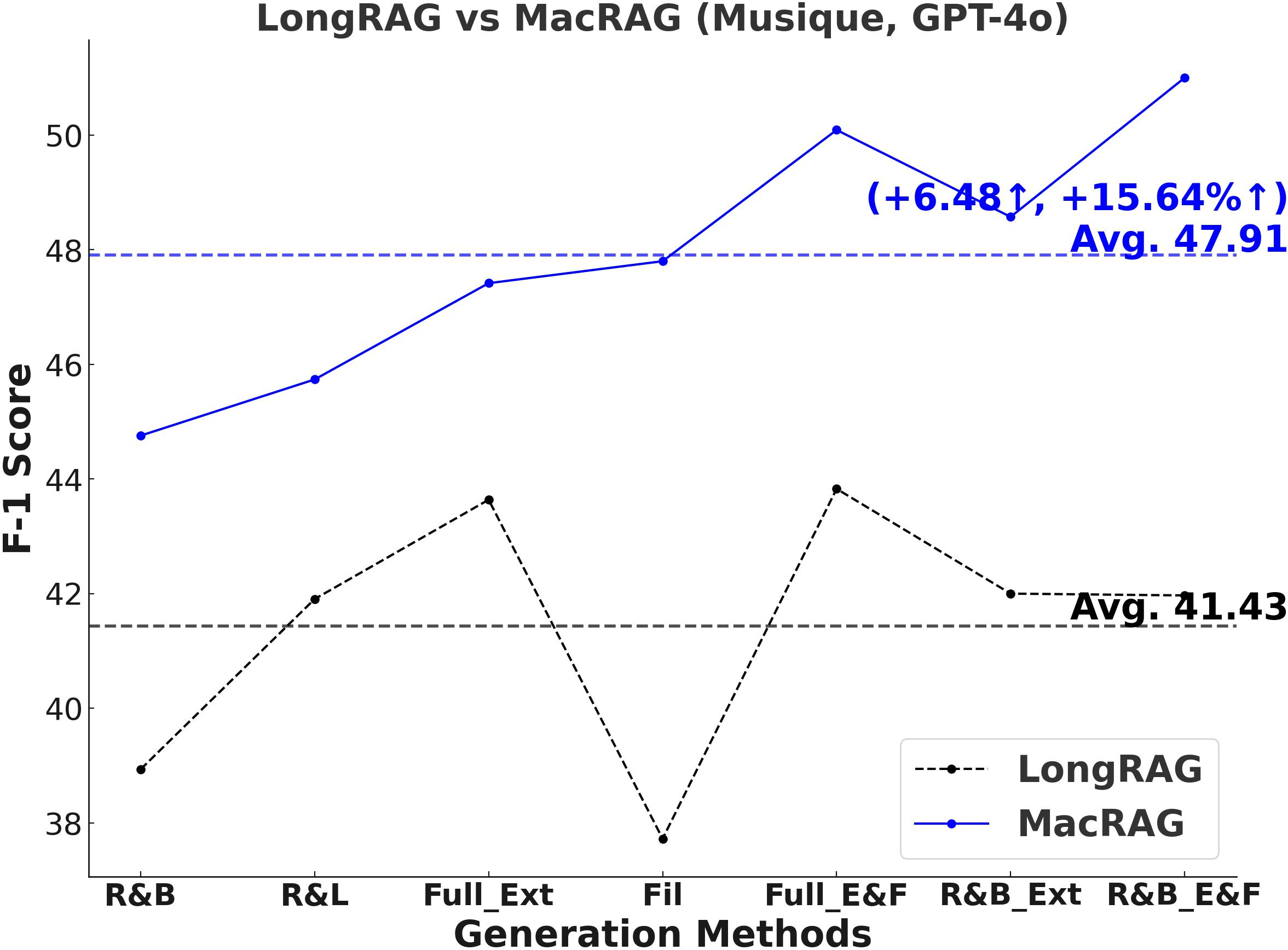
Figure 2: Comparative F1-scores on three datasets for LongRAG vs. MacRAG over seven generation modes with GPT-4o.
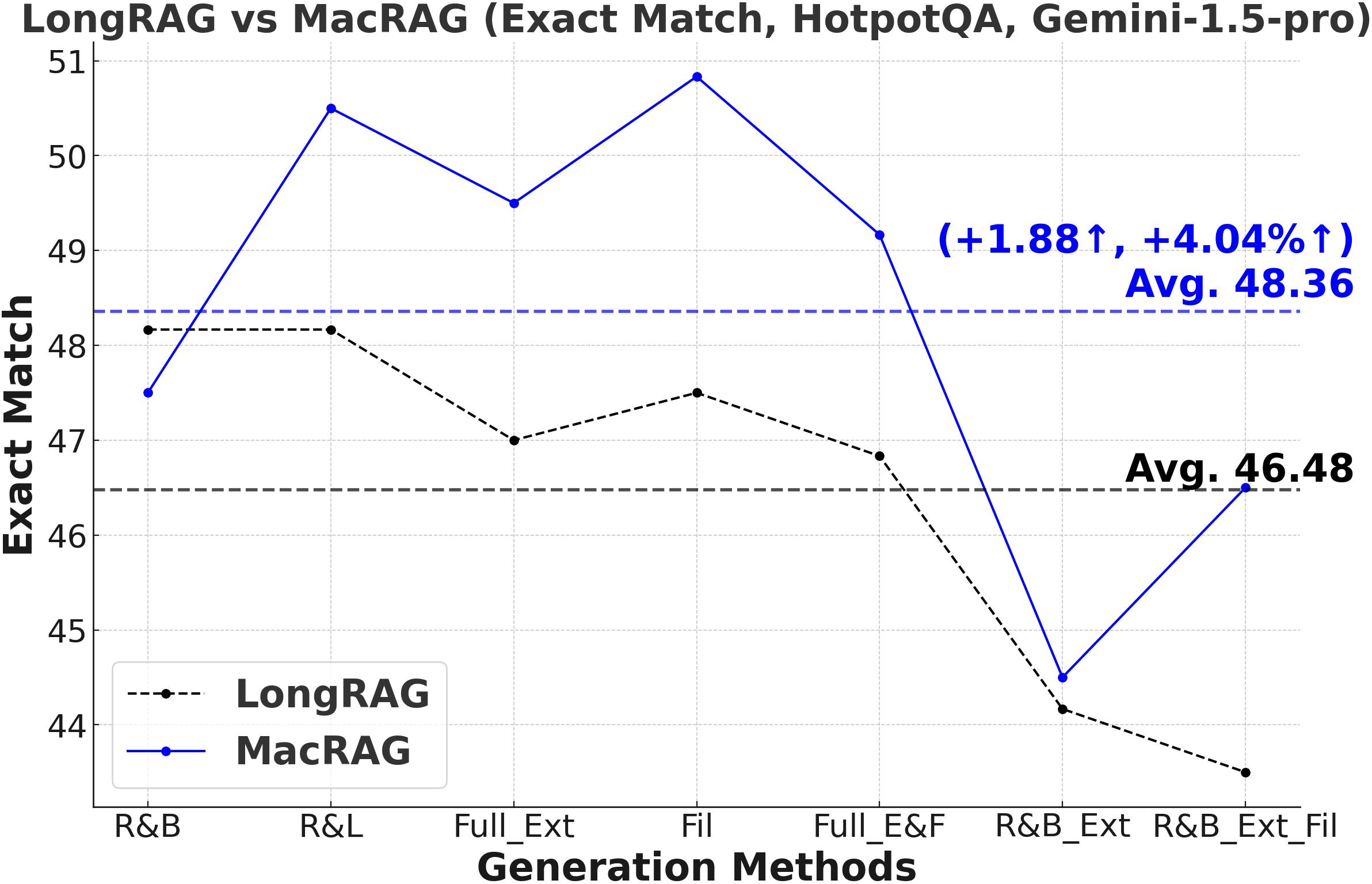
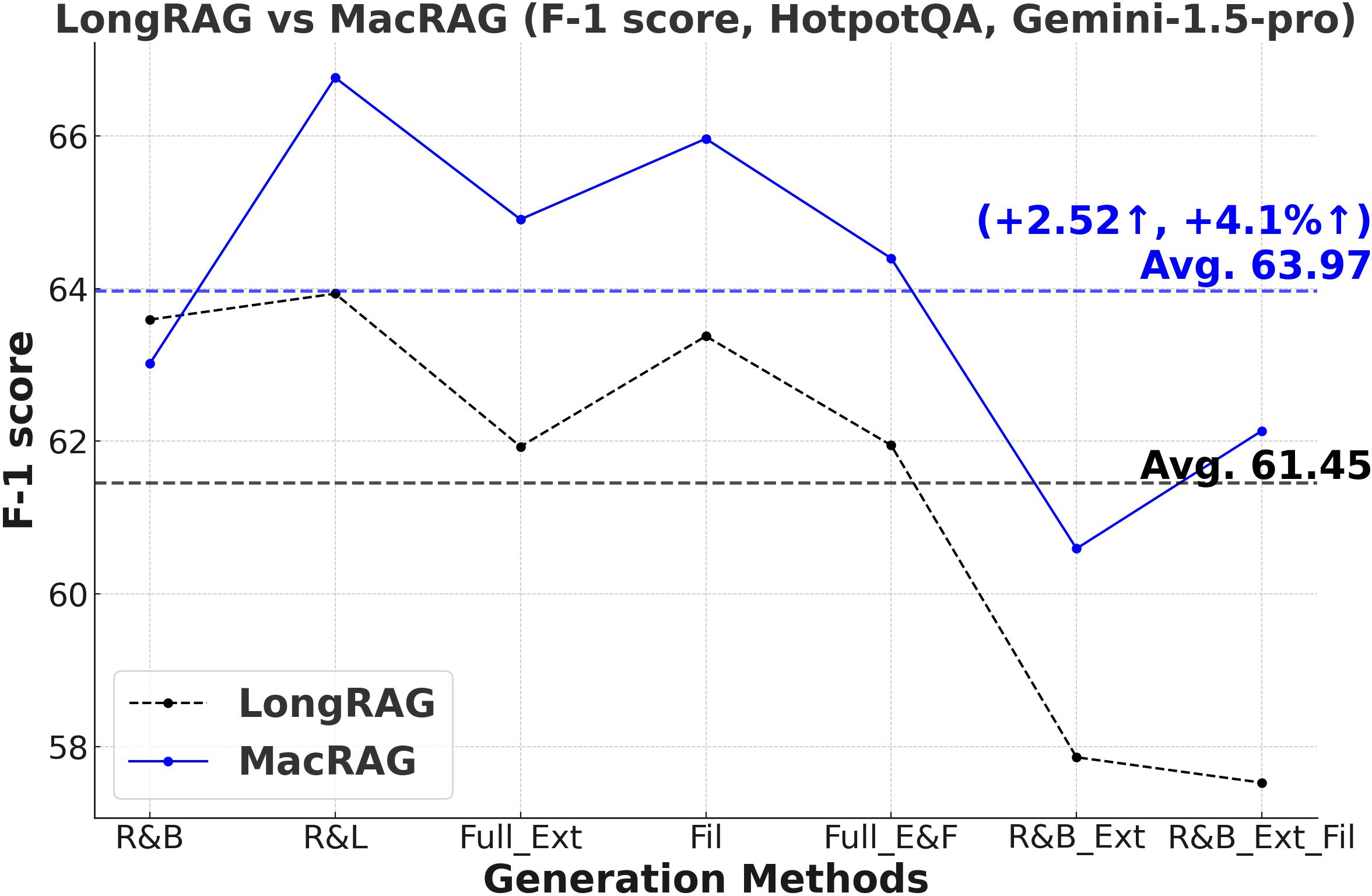
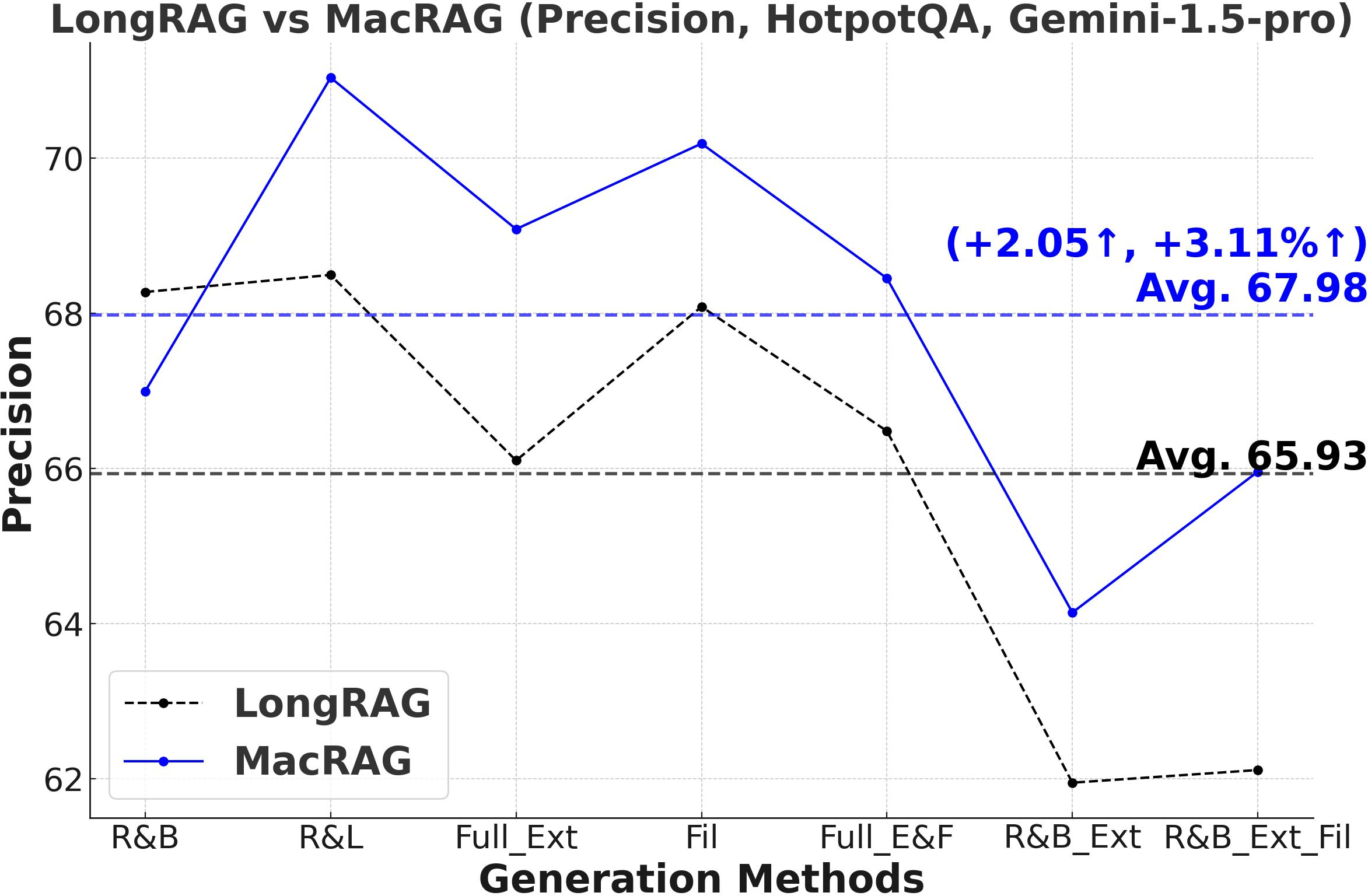
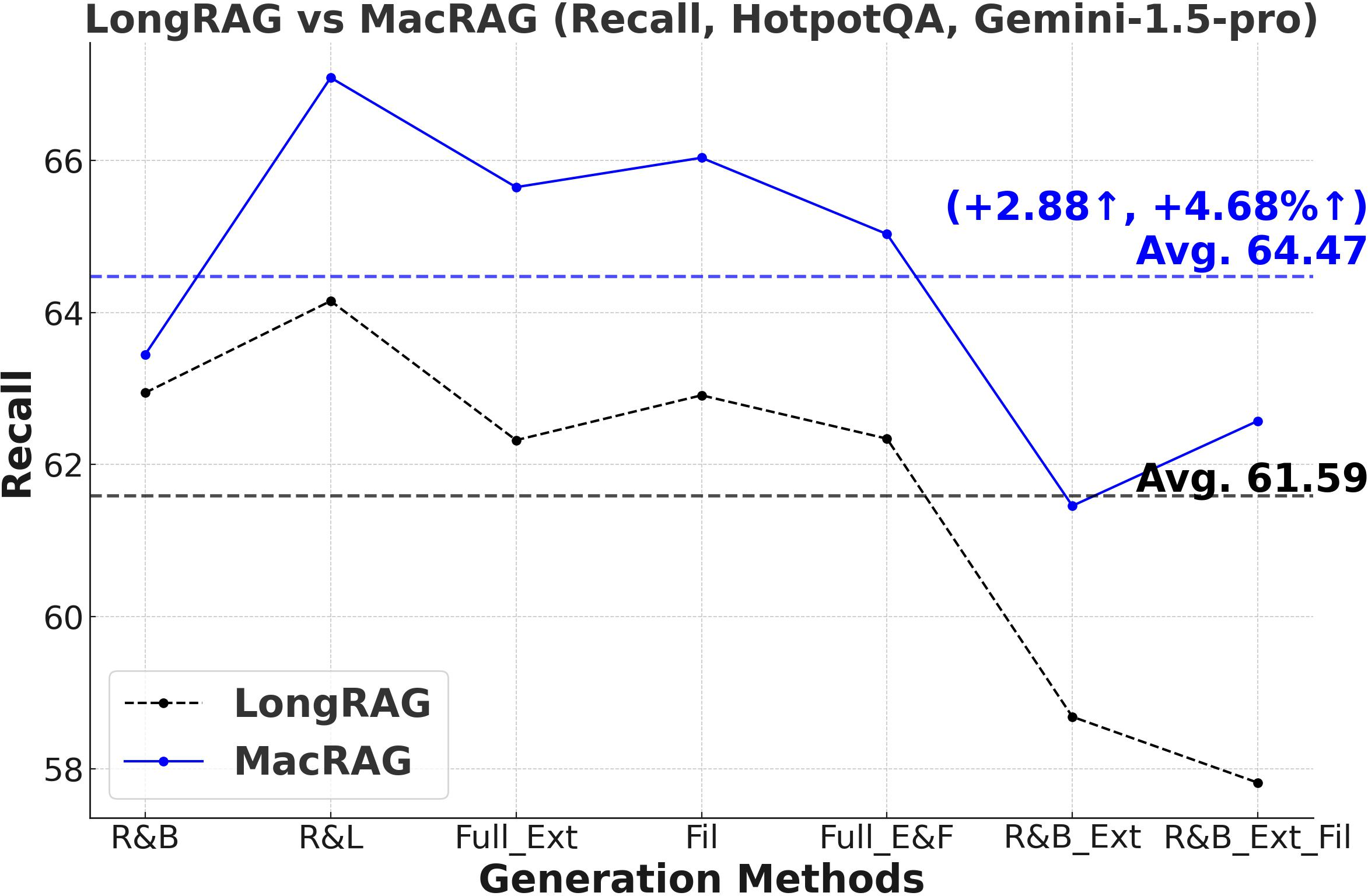
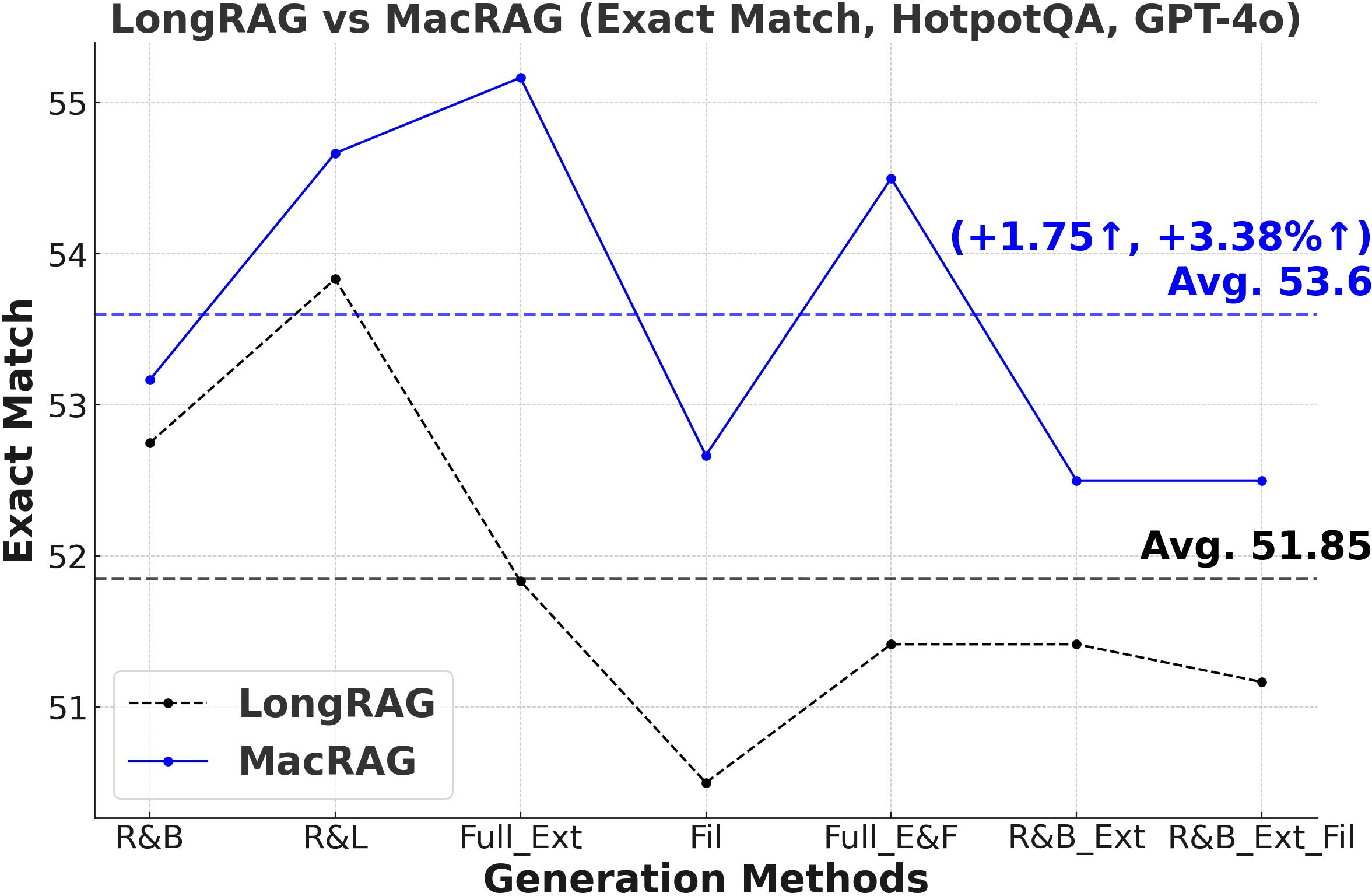
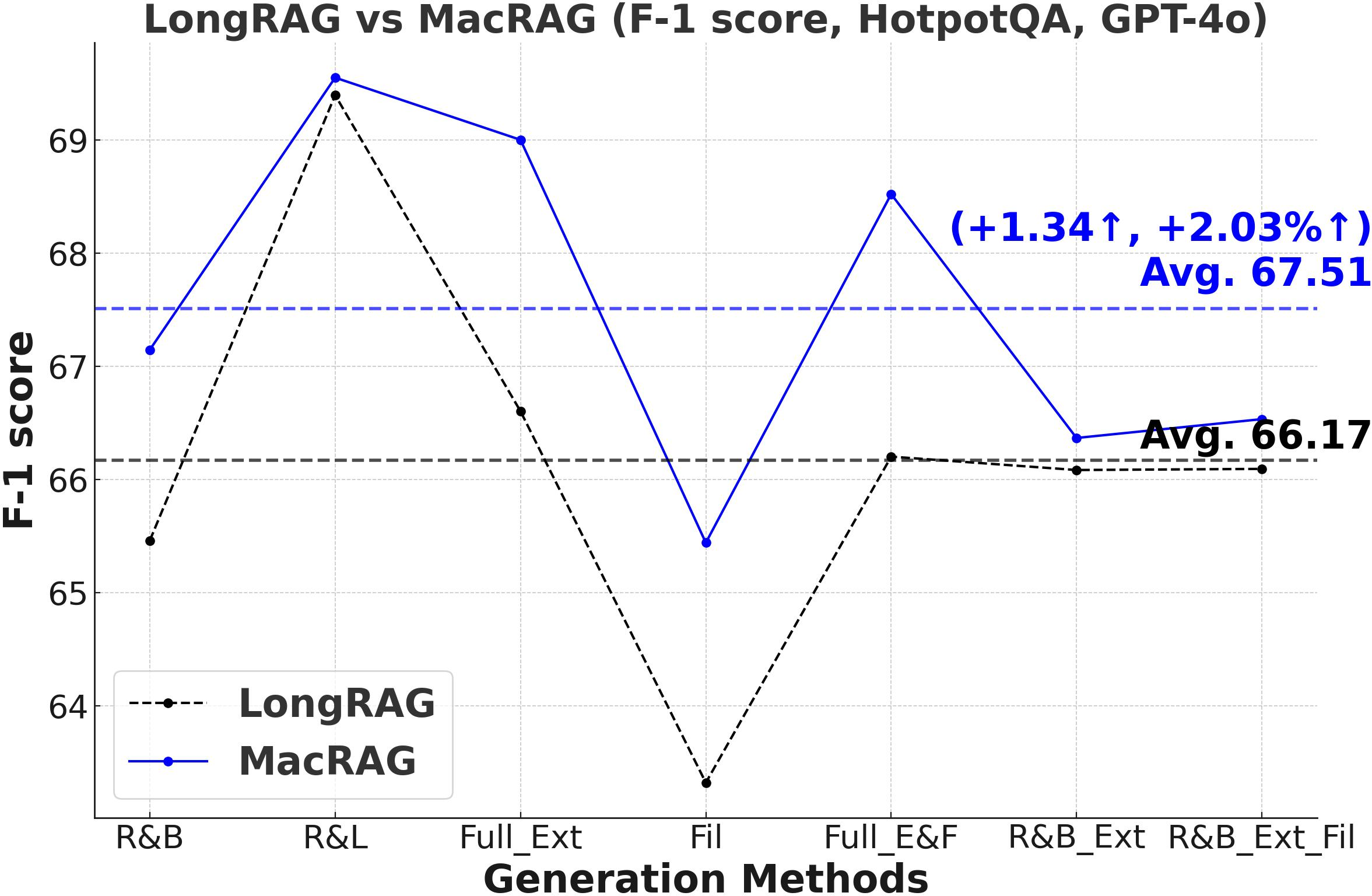
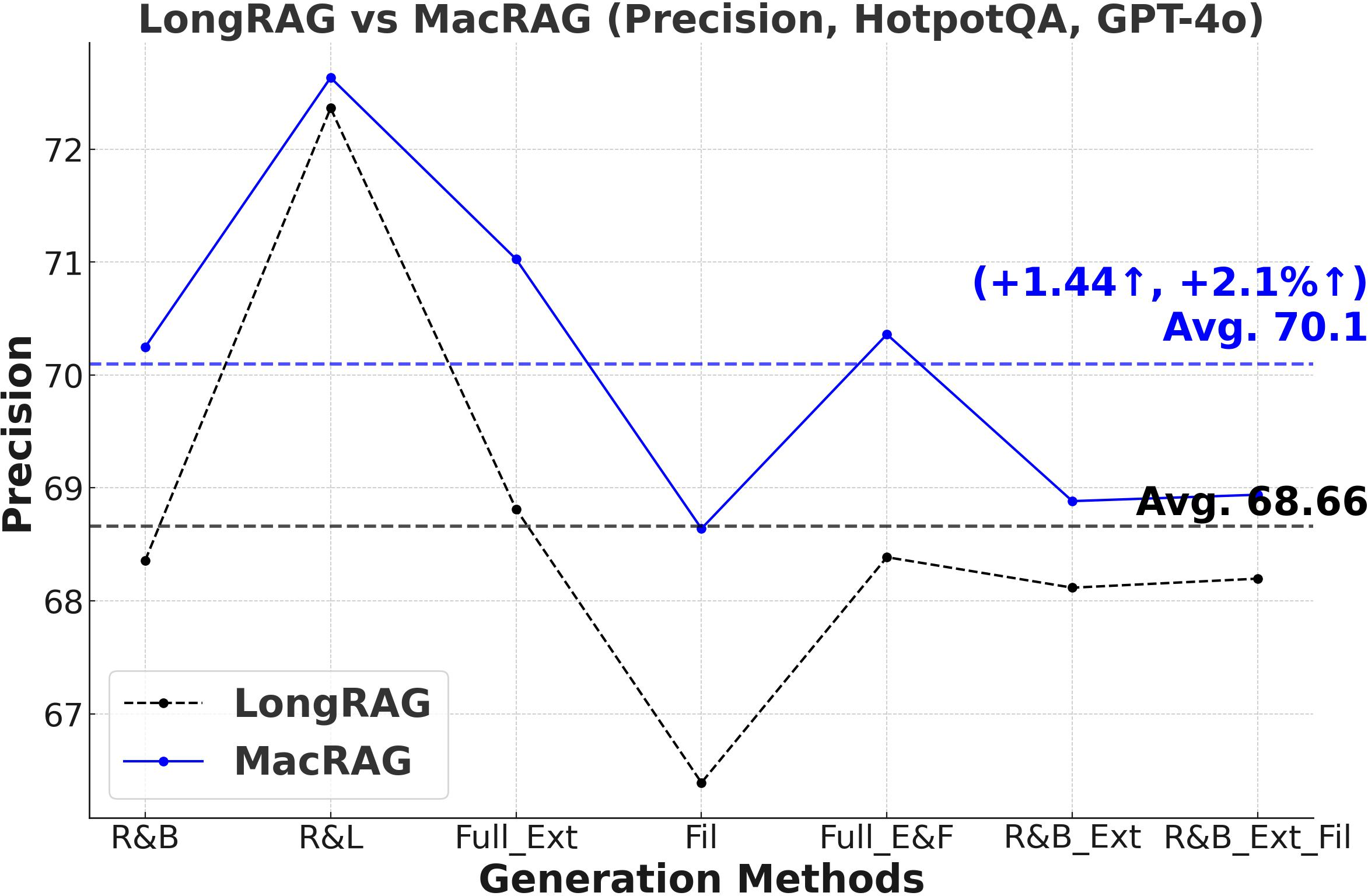
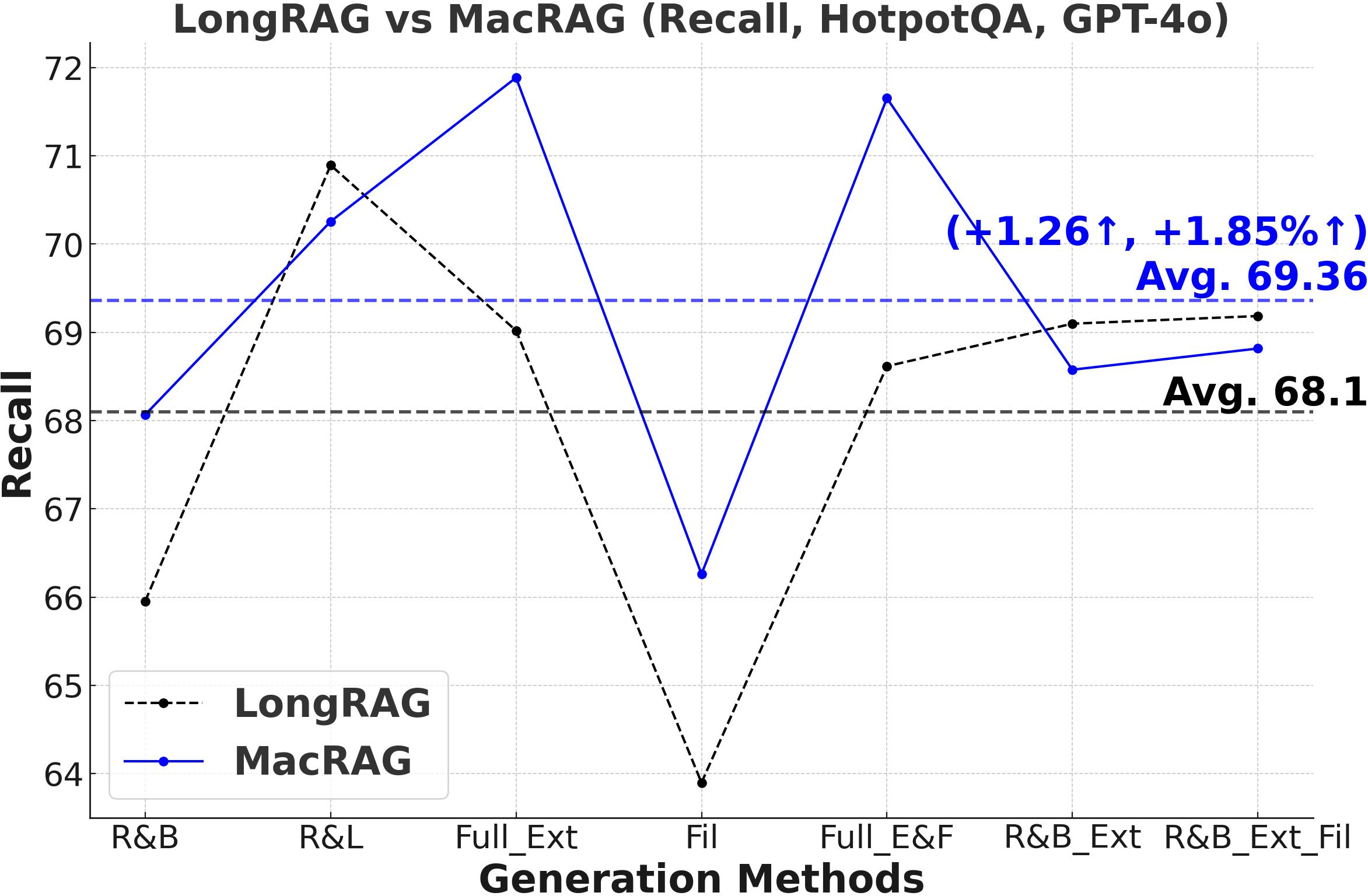
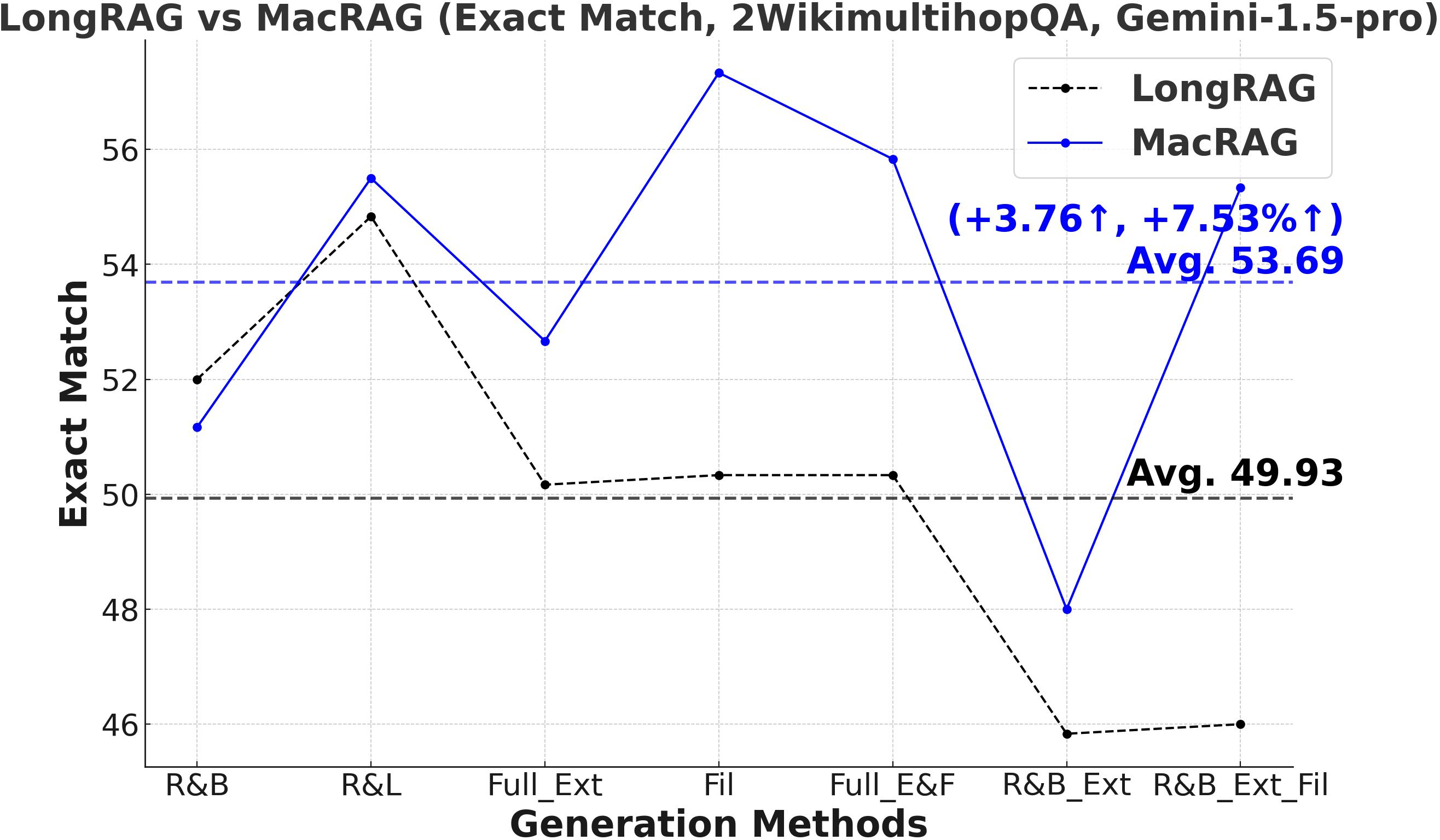
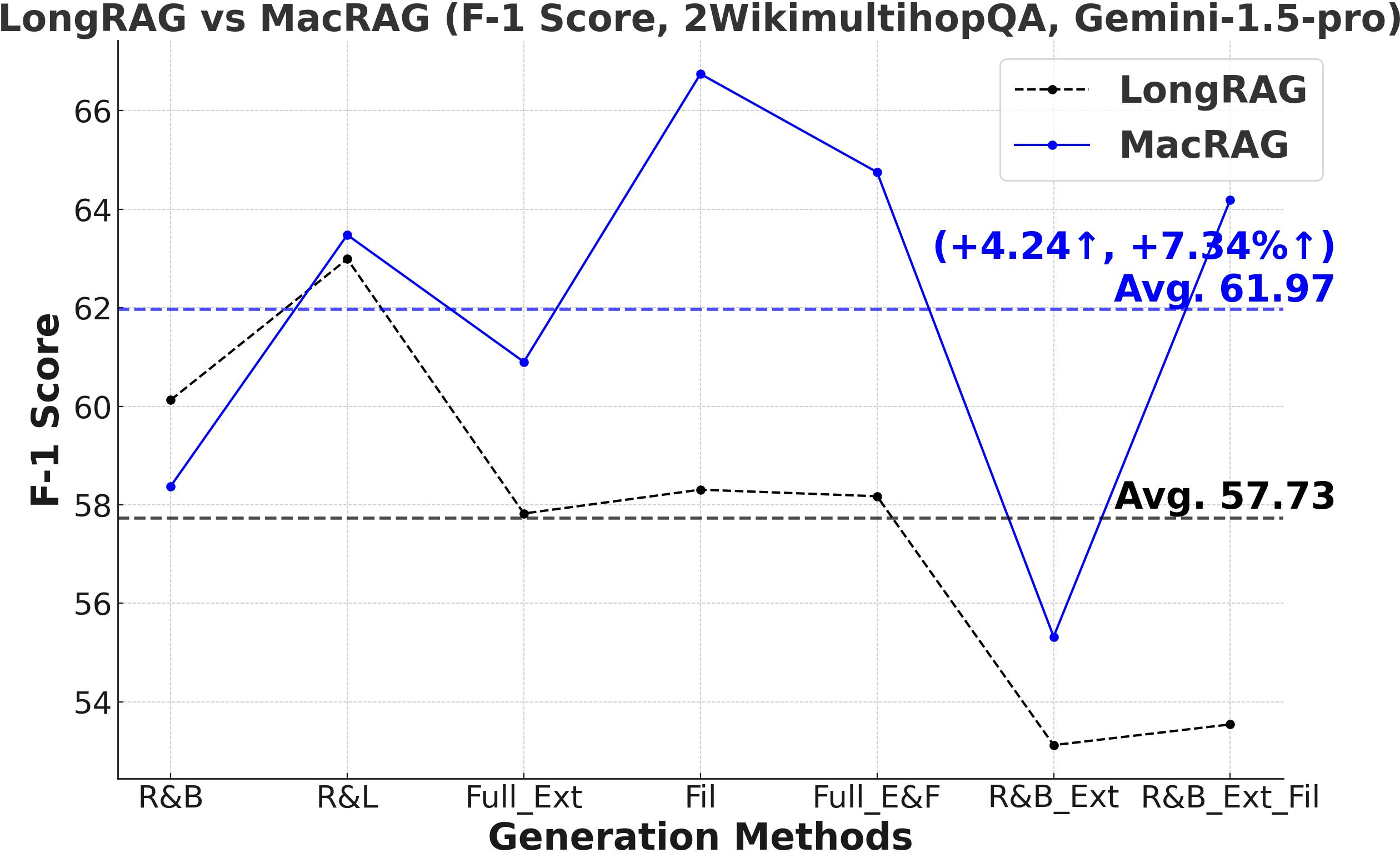
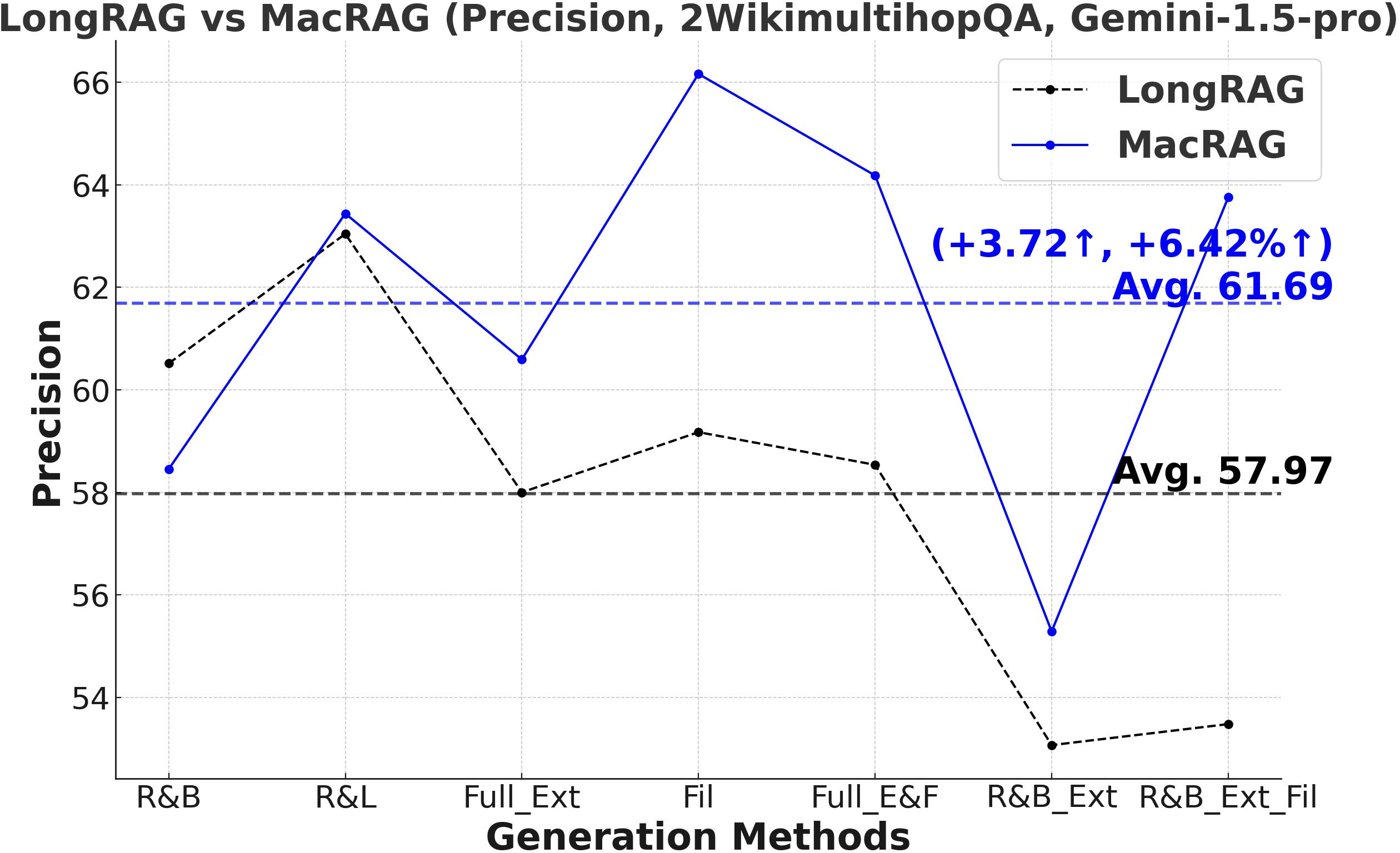
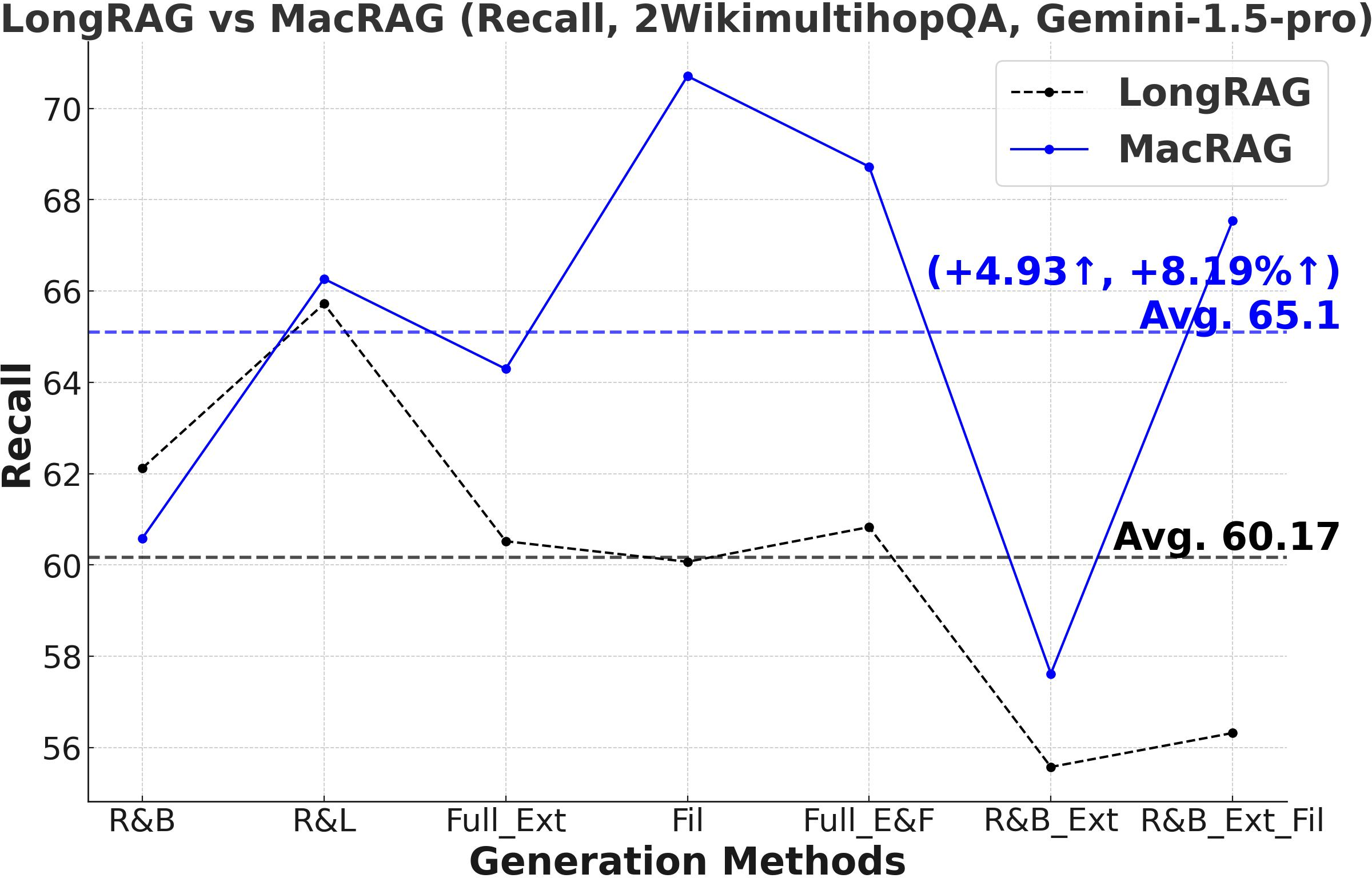
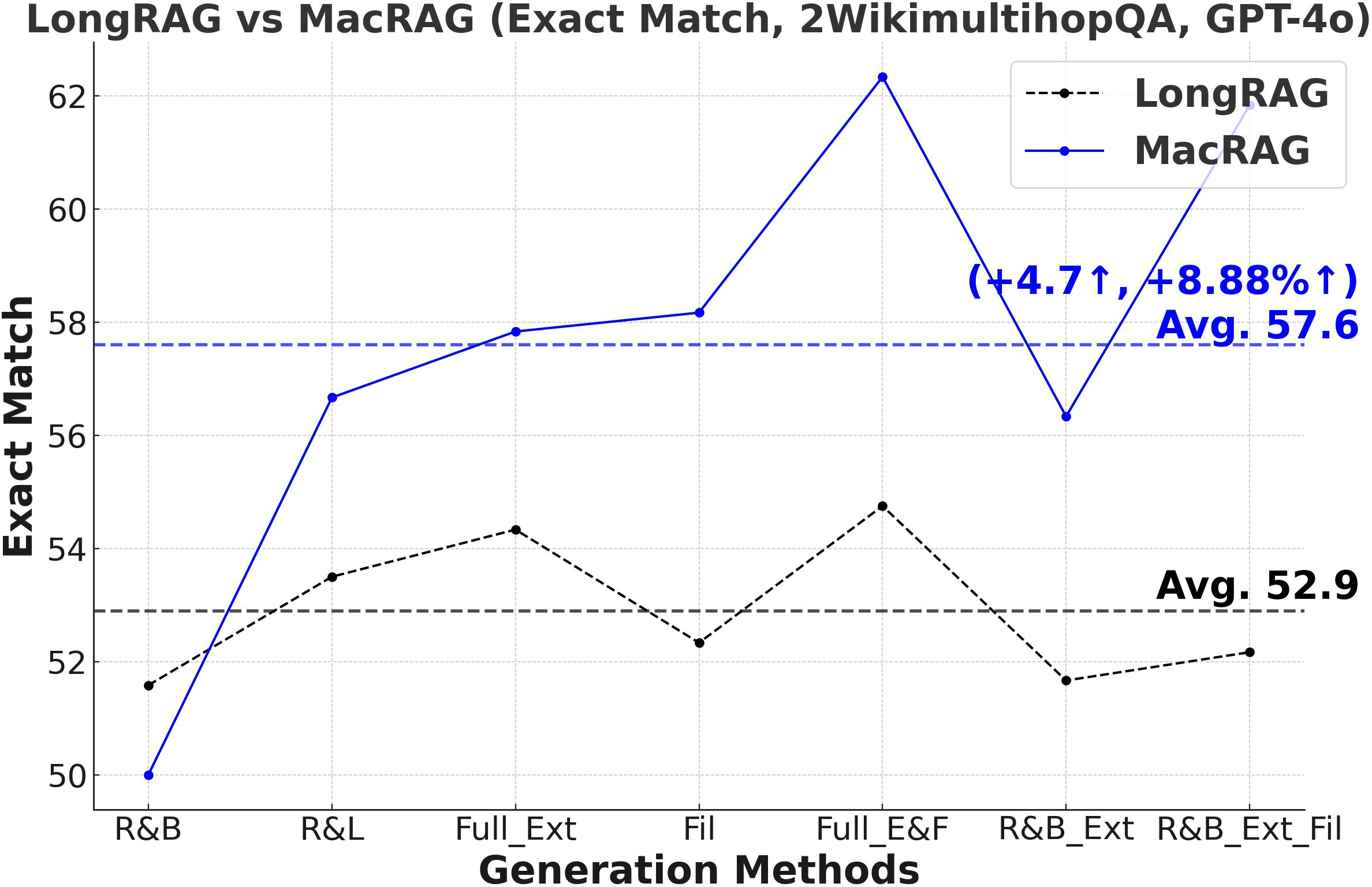
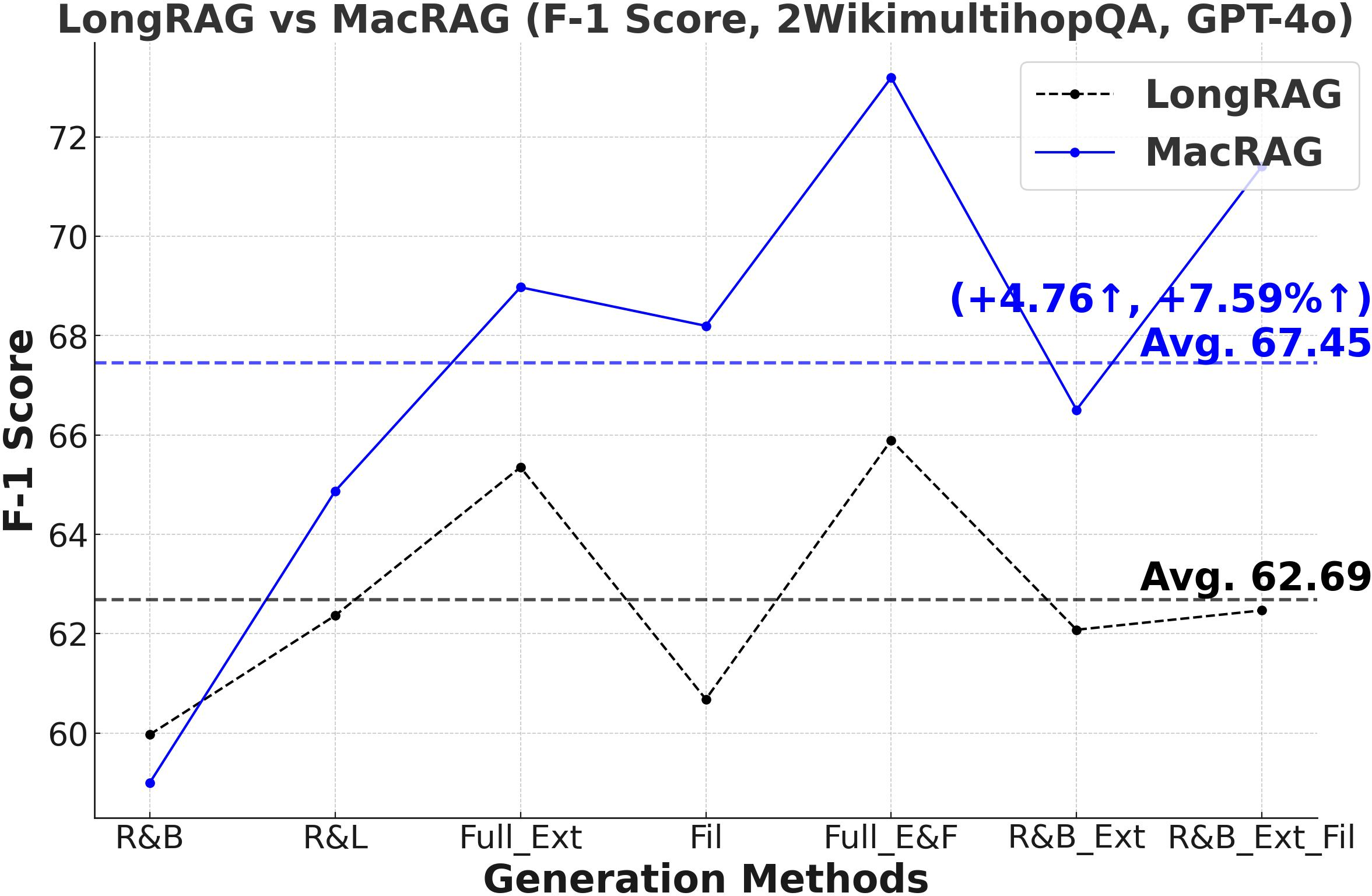
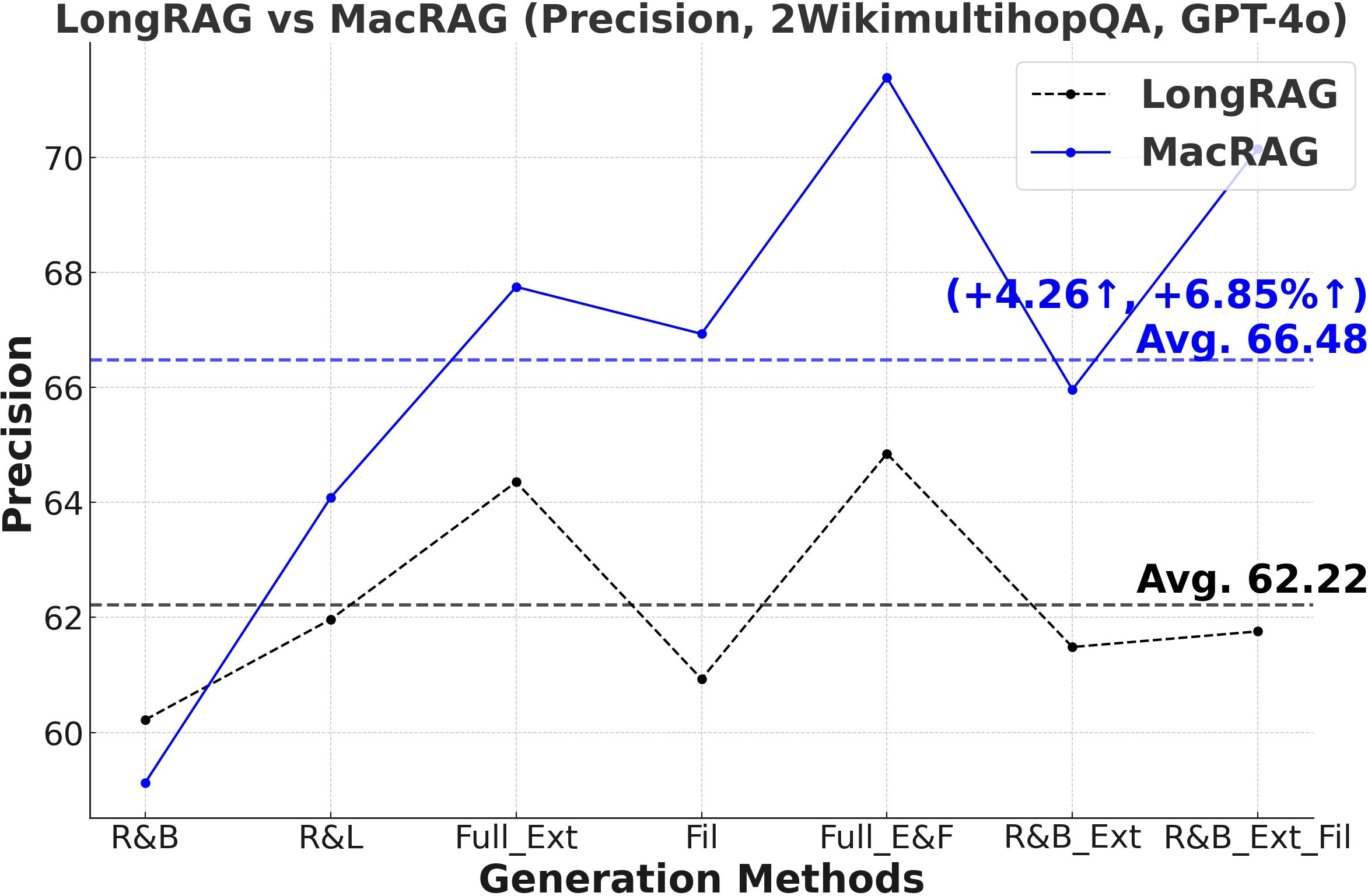
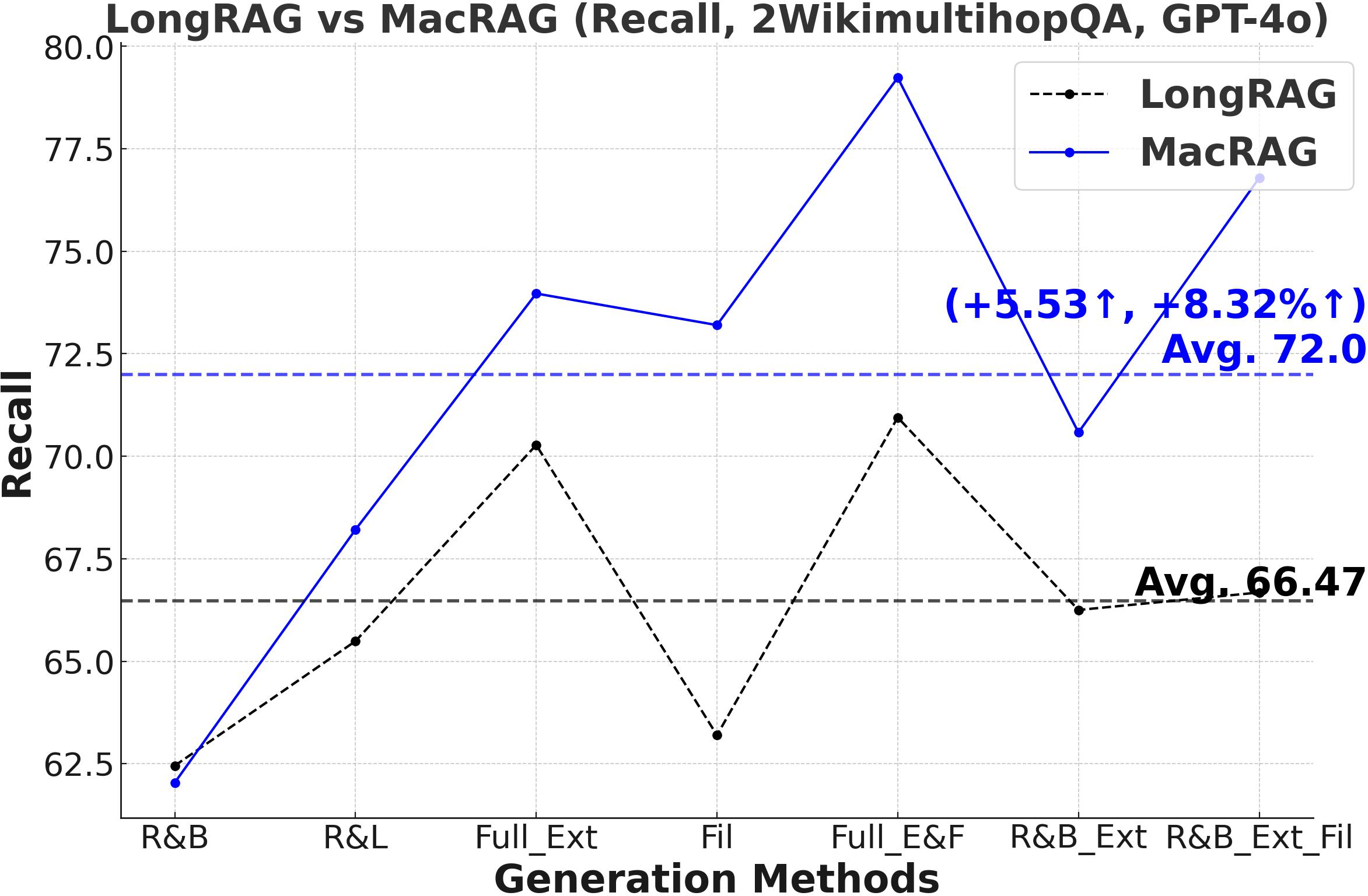
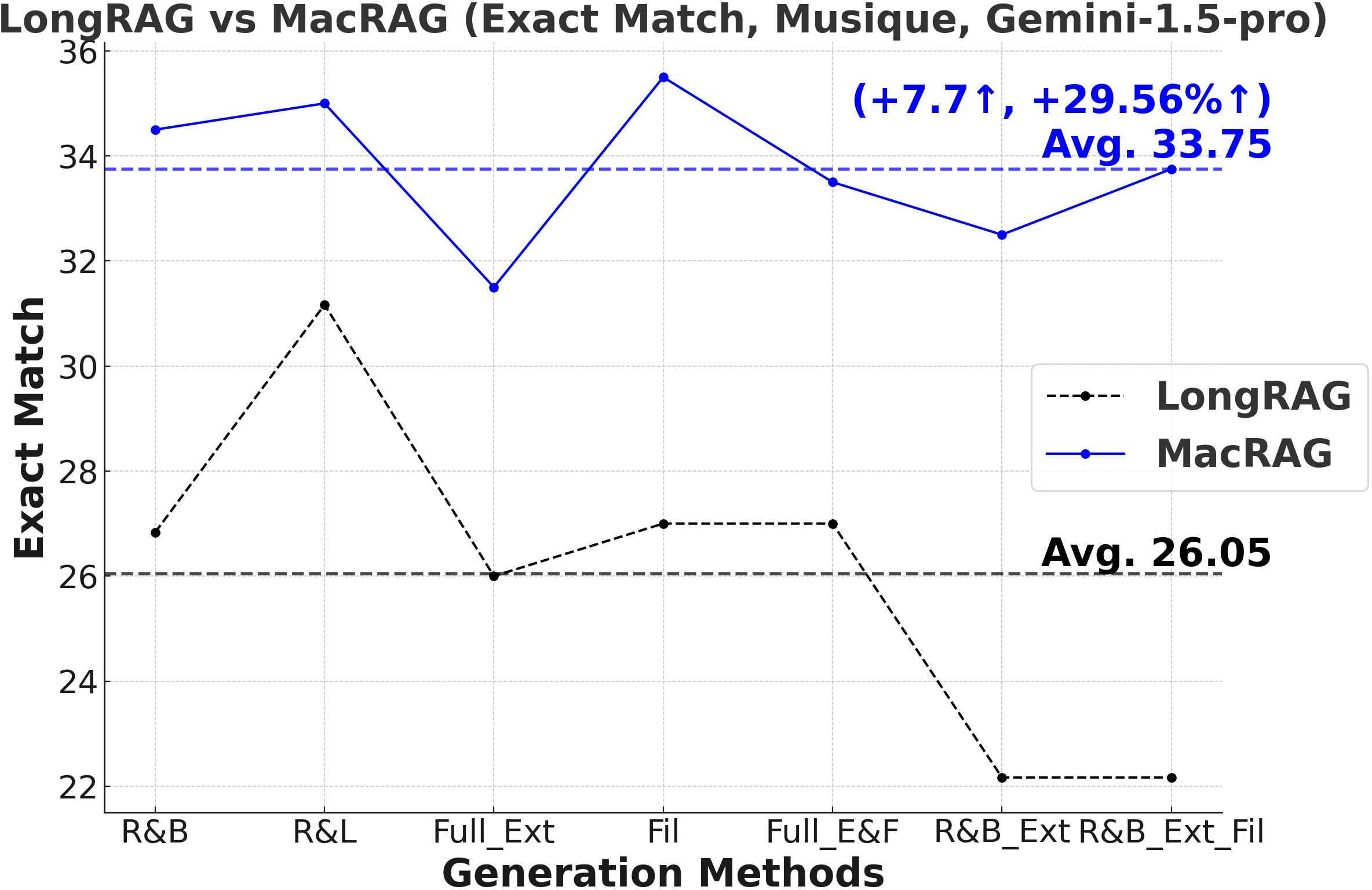
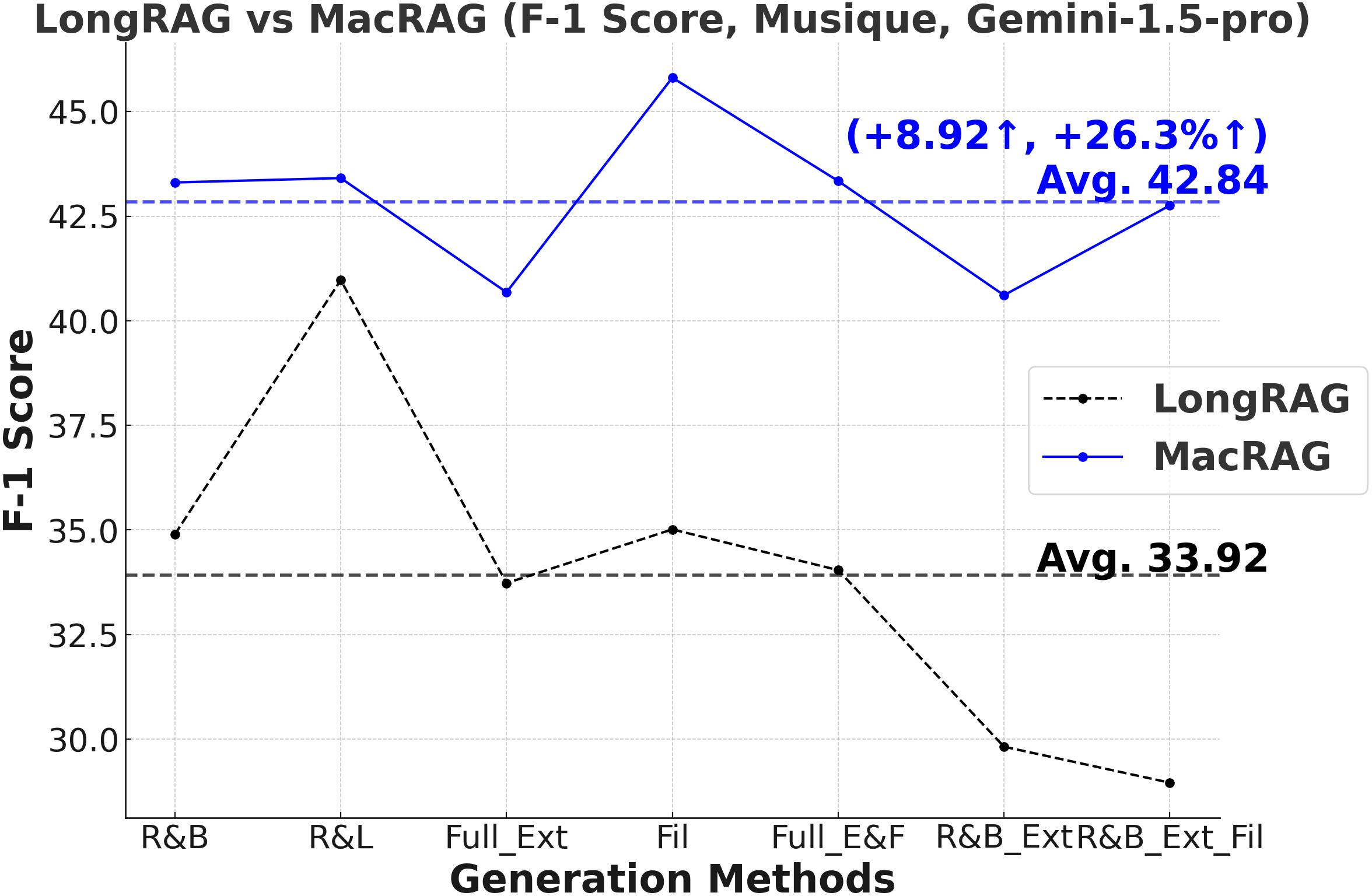
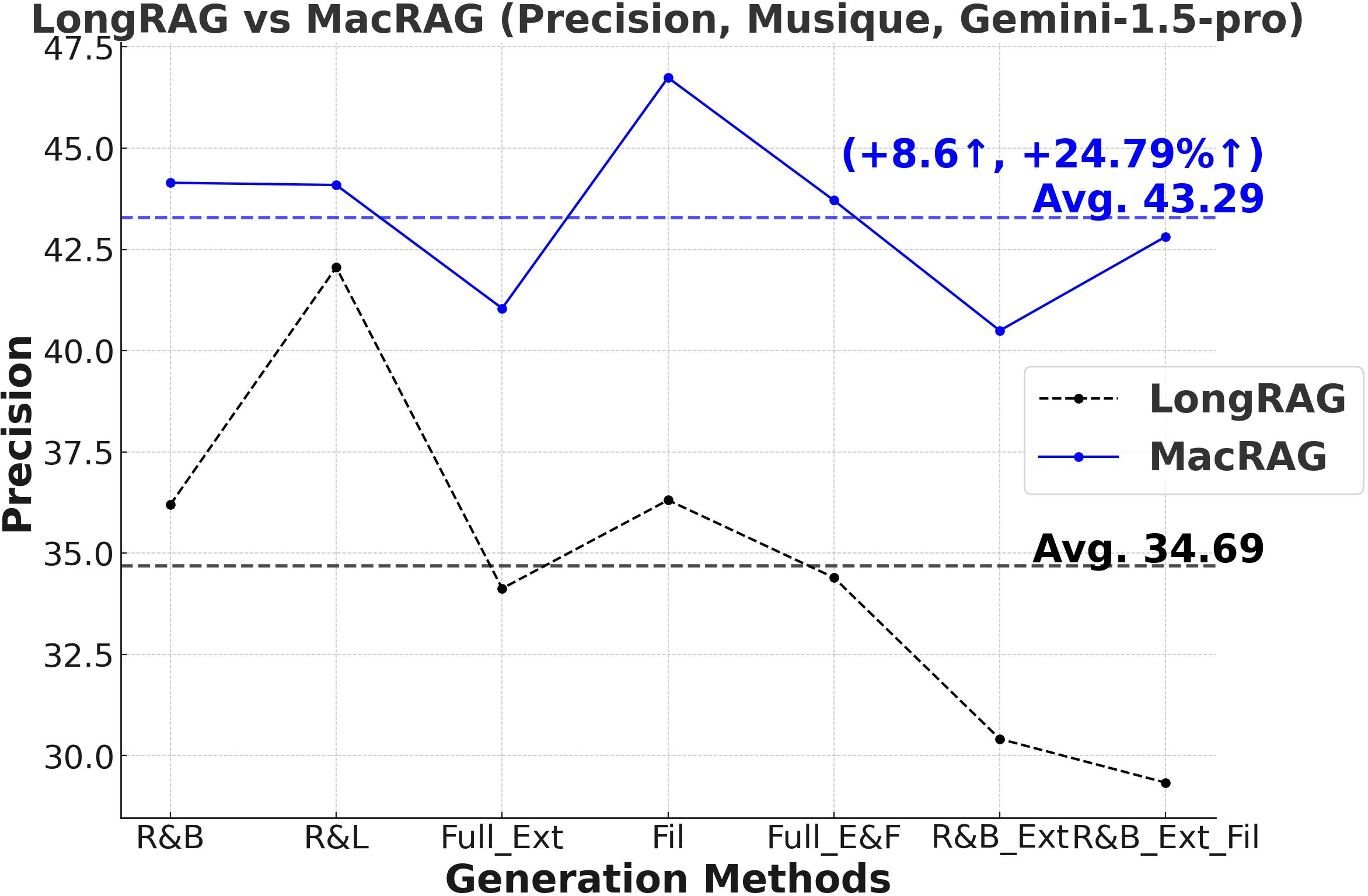
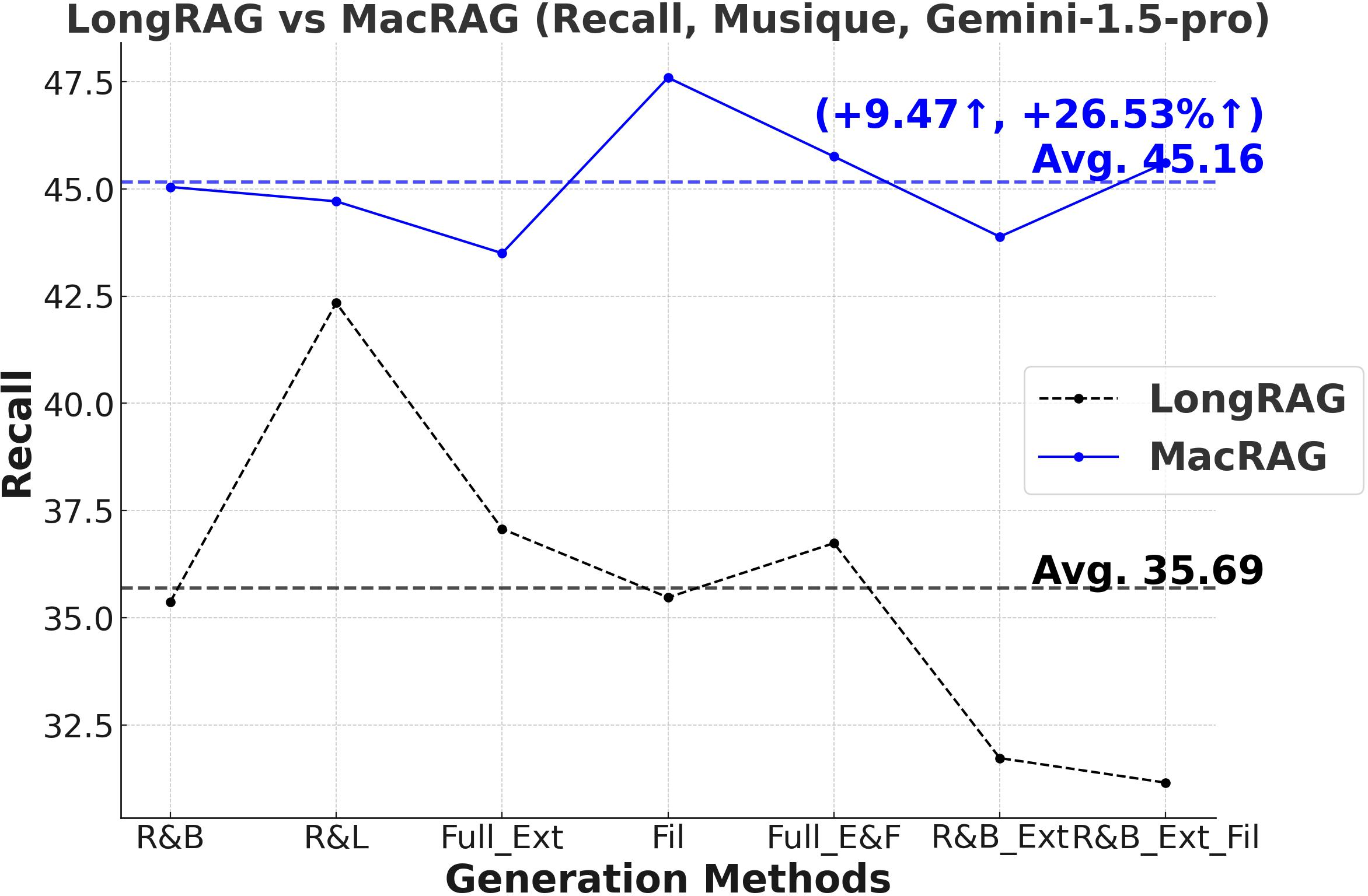
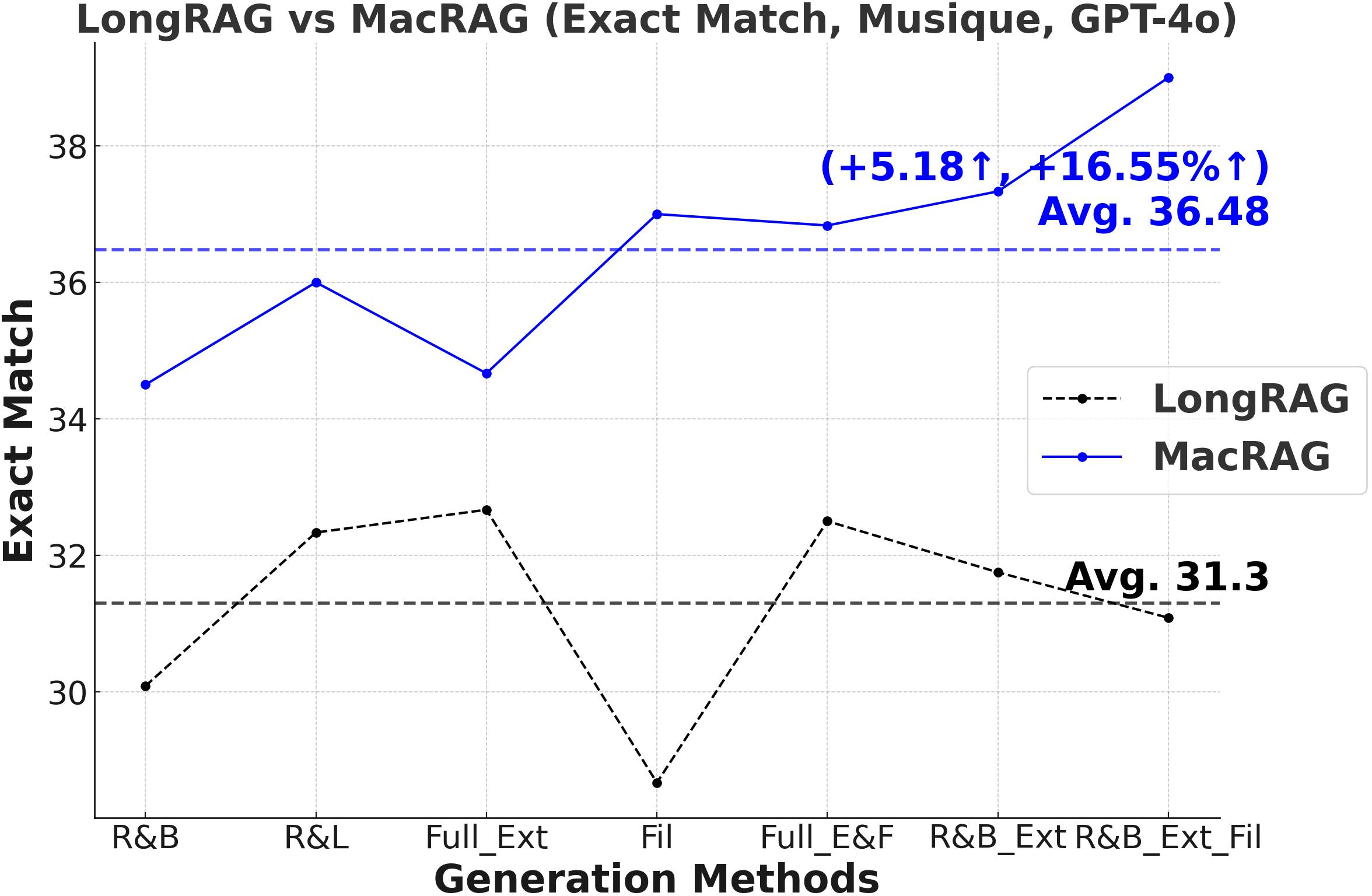
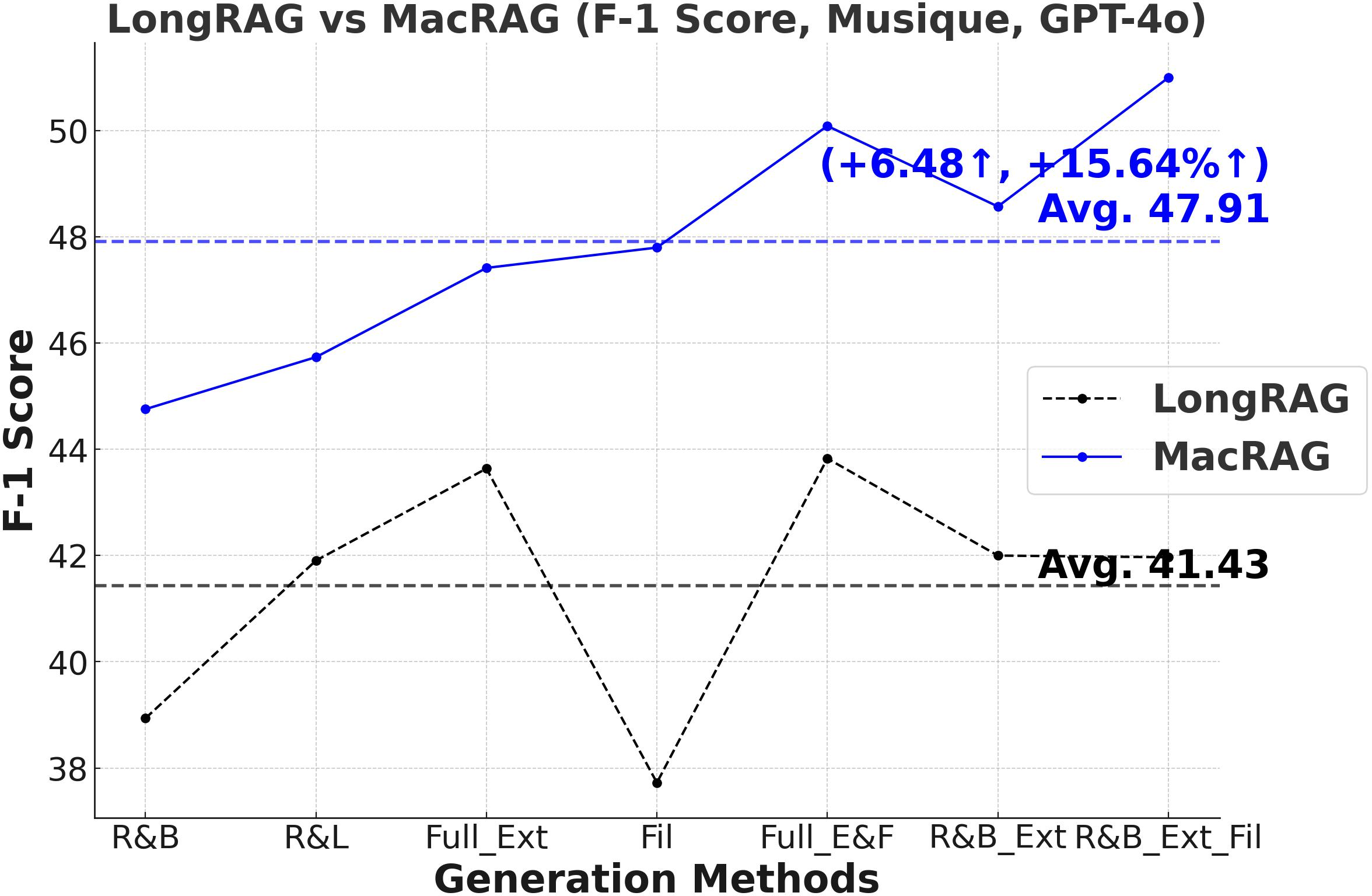
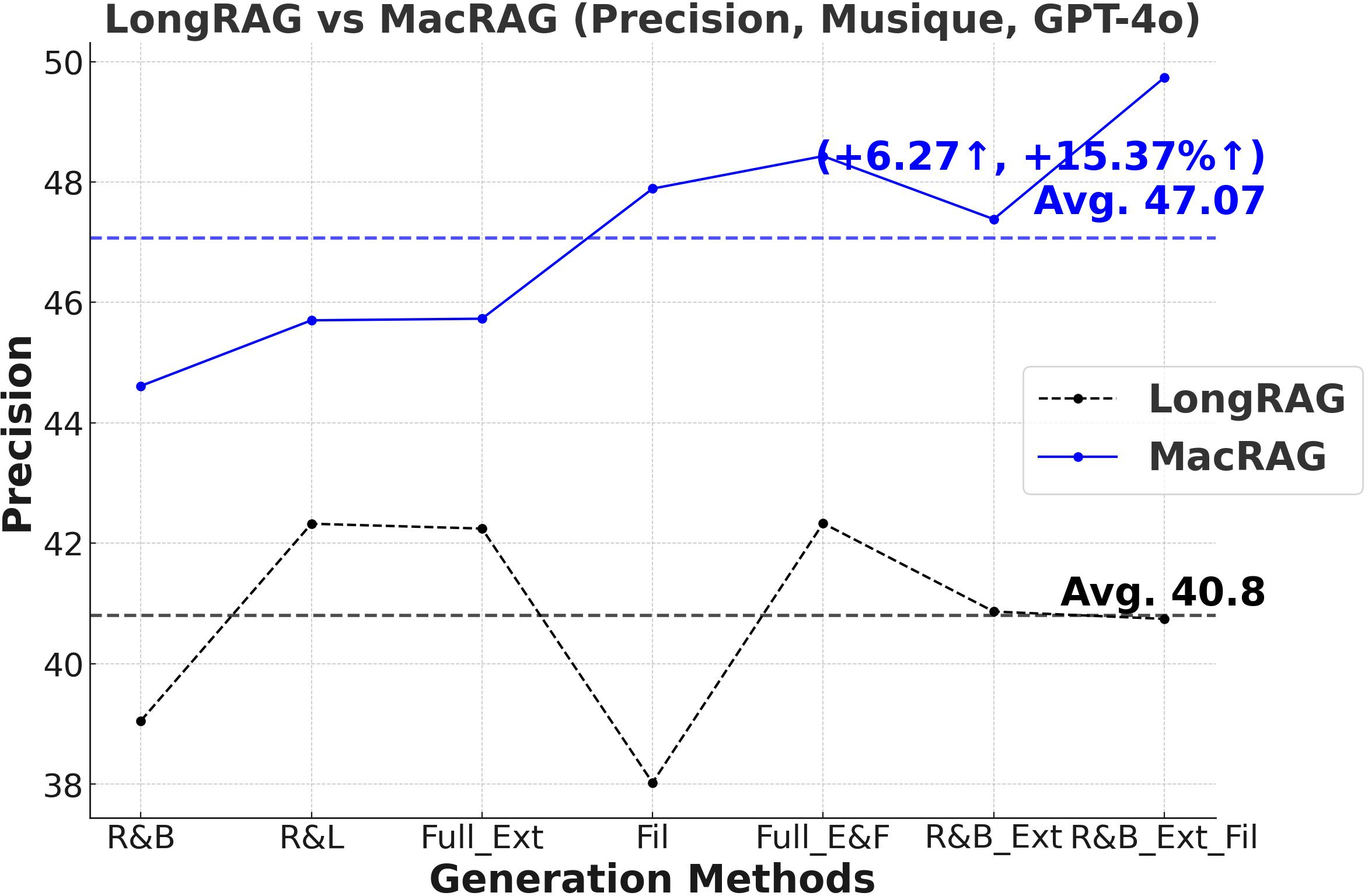
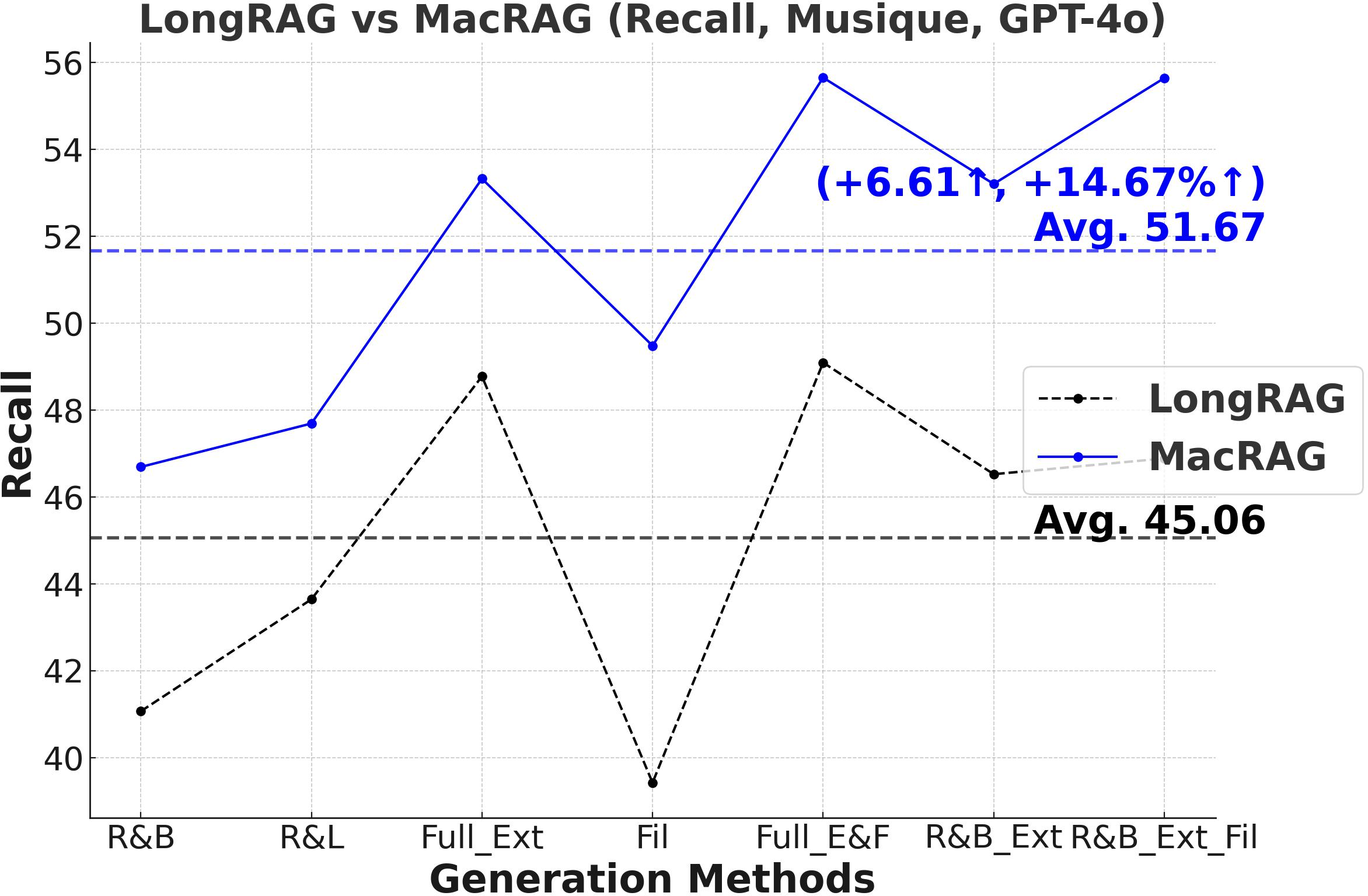
Figure 3: Comprehensive metric trends (Exact Match, F1, Precision, Recall) for MacRAG and LongRAG on HotpotQA, 2WikimultihopQA, and Musique with two LLMs.
- Ablation: Hierarchical Expansion and Scaling Robustness: Ablation studies demonstrate that removing adaptive neighbor merging or scaling-up components yields a drop of up to 5–6 F1 points, substantiating these as critical mechanisms for bridging scattered evidence. Scaling factor α is robust across datasets, effectively balancing input length and recall.
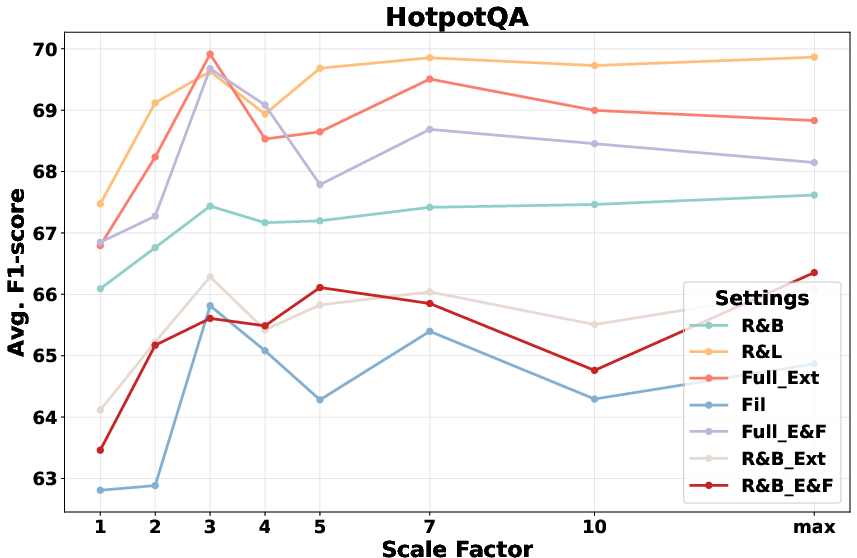
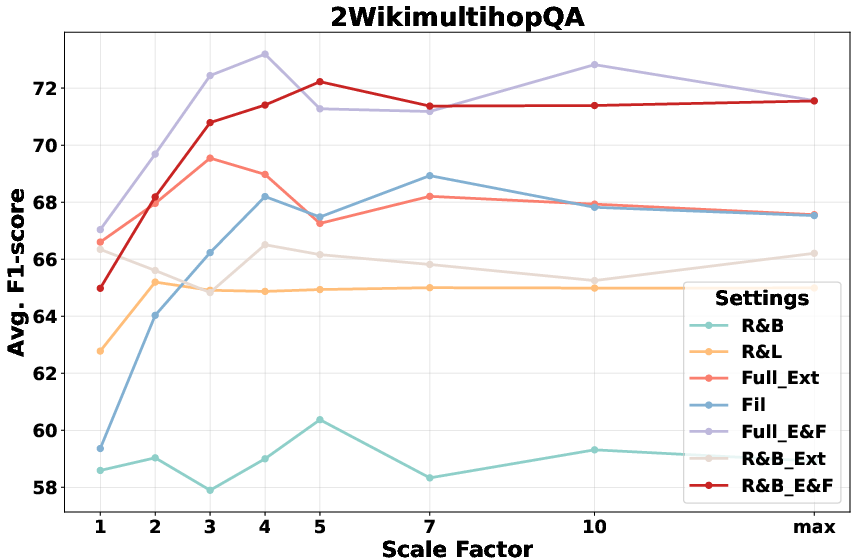
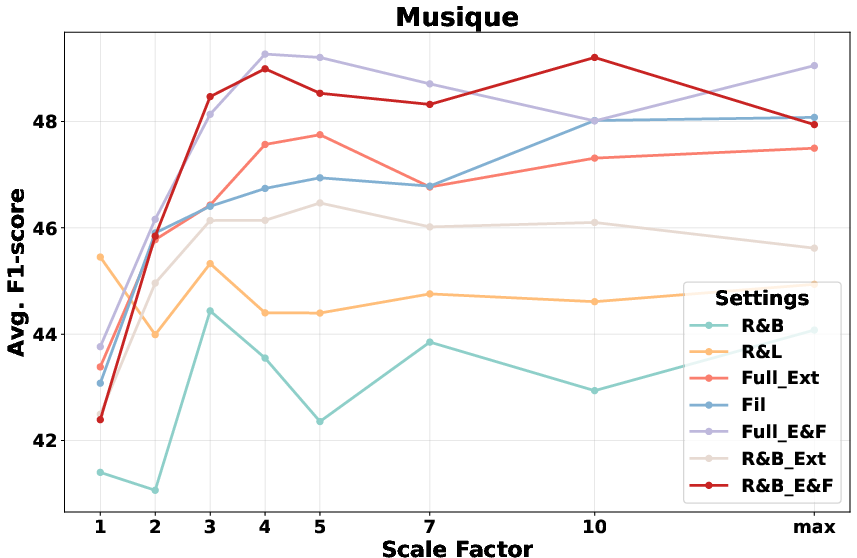
Figure 4: Performance trends for increasing scale factors (α) confirming robust improvements as more borderline candidates are added for context expansion.
Practical and Theoretical Implications
MacRAG's hierarchical index preserves content structure, enables modular neighbor expansion, and maintains efficiency for massive corpora and enterprise-scale applications requiring dynamic knowledge base updates and personalized long-context reasoning. Its multi-scale adaptive pipeline further facilitates integration with iterative/agentic QA pipelines (e.g., chain-of-retrieval, multi-agent systems), and demonstrates strong performance even with advanced LLMs, indicating future-proof scalability as model context windows continue to expand.
The controlled context construction can mitigate known LLM failures ("Lost in the Middle", hallucination bias, information fragmentation), and the modular design invites extensions—e.g., graph-based reranking, knowledge-guided neighbor expansion, agentic context selection in lifelong QA systems.
Conclusion
The MacRAG framework introduces a principled hierarchical retrieval architecture that adaptively constructs effective long contexts for RAG over large document corpora. Empirical evaluations confirm superior precision and recall with strong efficiency, robust gains across diverse settings and LLMs, and demonstrable adaptability for advanced multi-hop reasoning. MacRAG establishes itself as an efficient, scalable, and flexible retrieval foundation for future-generation RAG and agentic QA infrastructures.