- The paper addresses the Prefix Dominance Trap in LRMs by proposing a method for self-correction through peer interactions.
- It introduces the LeaP framework, which integrates periodic cross-path summarization using clustered, dispersed, and hybrid routing strategies.
- Experimental results on benchmarks like AIME and GPQA demonstrate that LeaP significantly improves reasoning performance and token efficiency.
Learning from Peers in Reasoning Models
Introduction and Motivation
The paper "Learning from Peers in Reasoning Models" addresses a notable limitation in Large Reasoning Models (LRMs): their inadequate recovery ability from initial reasoning errors, termed the "Prefix Dominance Trap." This phenomenon occurs when LRMs start with a poor beginning, significantly degrading their subsequent reasoning paths. The authors identify that peer interaction, inspired by psychological findings, could effectively enhance self-correction capabilities in reasoning models without disrupting correct outputs. The proposed method, Learning from Peers (LeaP), introduces a novel mechanism allowing LRMs to share and incorporate peer insights during inference, thus targeting improvements in the model's reasoning proficiency.
Methodology: LeaP Framework
The LeaP framework facilitates cross-path interaction among LRMs through a two-stage process integrated into reasoning paths. At regular intervals, each reasoning path summarizes its conclusions and shares them via a routing mechanism, enabling other paths to leverage diverse insights. The routing mechanism is designed with multiple strategies—clustered, dispersed, and hybrid—to select the most relevant peer summaries for refining the reasoning paths.
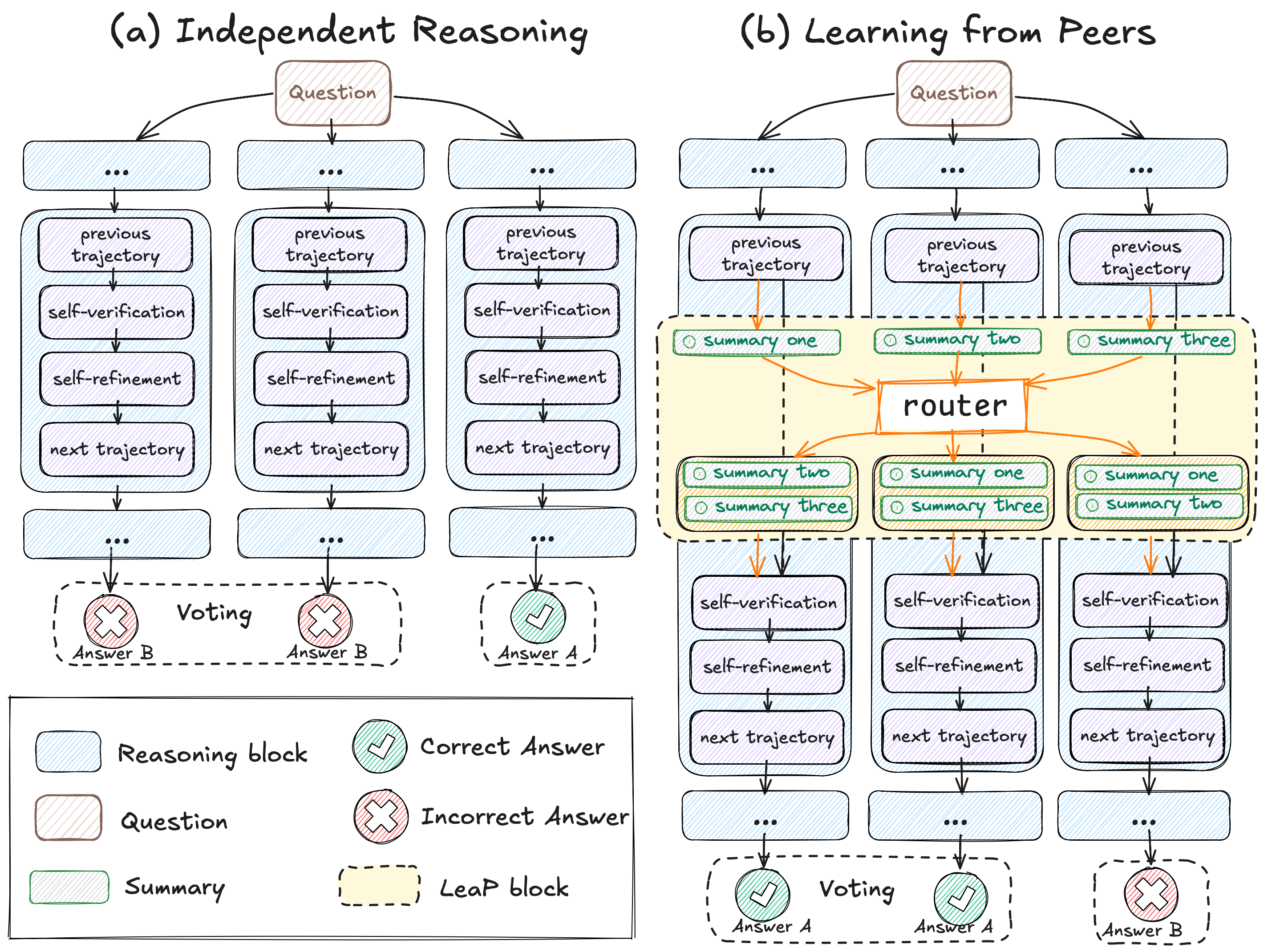
Figure 1: The illustration of (a) Independent Reasoning and (b) the proposed method Learning from Peers (LeaP). In independent reasoning, multiple paths are generated independently in parallel. In contrast, LeaP inserts a LeaP block into reasoning path, encouraging the model to learn from peers.
Results and Analysis
Experiments conducted across various benchmarks—AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond—demonstrate substantial performance improvements with LeaP. Notably, QwQ-32B with LeaP shows a remarkable gain, surpassing advanced models like DeepSeek-R1-Distill-Qwen-14B in certain tasks. The fine-tuned LeaP-T model series further reinforces these improvements, indicating refined self-verification initiated through peer insights.
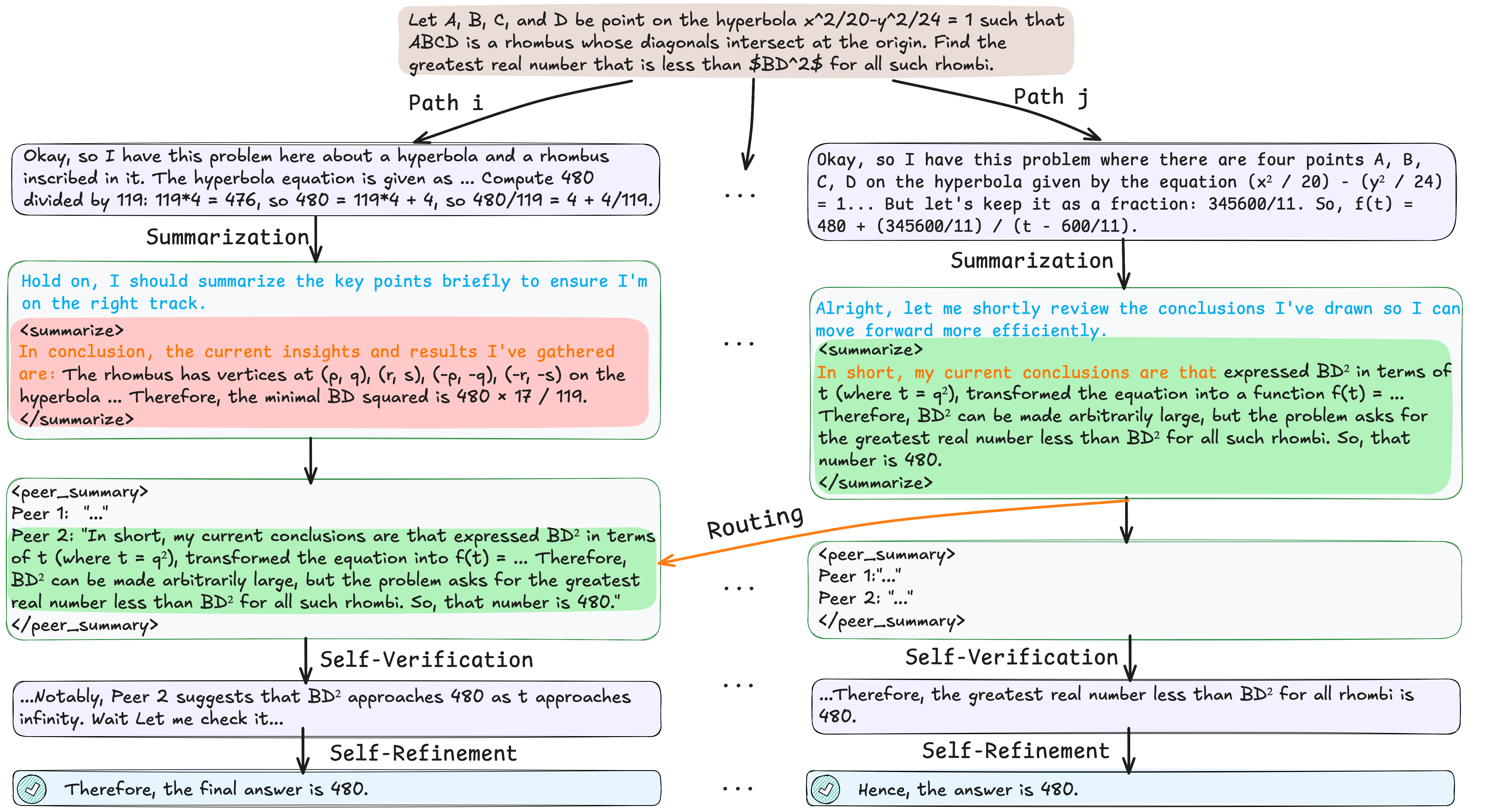
Figure 2: An example of how LeaP enables communication between path i and j.
By systematically evaluating various aspects of LeaP's implementation—such as communication granularity, traffic, and position—the paper identifies optimal configurations that maximize reasoning accuracy while maintaining token efficiency. Additionally, LeaP's robustness remains evident across different difficulty levels, demonstrating its capability to aid the models in solving complex tasks.
Implications and Future Directions
The introduction of peer learning in LRMs through LeaP has practical implications for enhancing model accuracy and efficiency during inference. Not only does this approach alleviate the Prefix Dominance Trap, but it also lays foundational work for broader applications in collaborative problem-solving within AI domains. Future directions include extending peer learning frameworks to reinforcement learning settings and leveraging specialized expertise across diverse domains to further amplify the reasoning capabilities of LRMs.
Conclusion
The "Learning from Peers in Reasoning Models" paper effectively addresses key limitations in LRMs by incorporating peer-based interaction, thereby enhancing their self-correction capabilities significantly. Through extensive analyses and experiments, the research validates the effectiveness of LeaP and illustrates promising future directions for improving reasoning models across various AI applications. This work emphasizes the potential of collaborative reasoning in advancing AI towards more reliable and human-aligned systems.
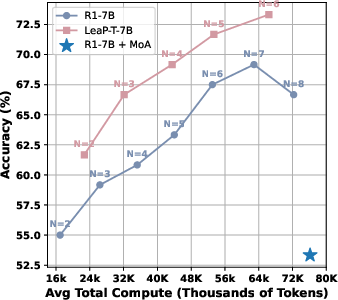
Figure 3: Accuracy vs. Total tokens on AIME 2024.