- The paper presents a taxonomy of LLM integration mechanisms—prompting, training adaptation, and modality fusion—that overcome traditional recommender system challenges.
- It details key prompting strategies (hard, soft, hybrid, and control logic) to enable adaptive, efficient multi-task recommendations.
- The survey highlights empirical advances in semantic reasoning, cross-modal alignment, and LLM-based evaluation, driving future research directions.
LLMs in Multimodal Recommender Systems: A Comprehensive Survey
Introduction and Motivation
The paper "A Survey on LLMs in Multimodal Recommender Systems" (2505.09777) offers an exhaustive review of how LLMs—including models like GPT-3, PaLM, LLAMA—are reshaping the landscape of Multimodal Recommender Systems (MRS). MRS are characterized by the integration of heterogeneous data types such as text, images, structured data, and behavioral logs to enhance personalized recommendation pipelines. Traditional approaches, notably collaborative filtering and modality-specific neural encoders, are often hindered by common issues—cold-start, data sparsity, and modality misalignment. The increasing prevalence and flexibility of LLMs enables semantic reasoning, in-context learning, and adaptive input handling, promising significant improvements in these domains.
Unlike prior surveys focused mainly on encoder architectures or loss-based fusion, this work introduces a taxonomy centered around LLM-specific integration mechanisms: prompting, training strategies, and data adaptation. This survey prioritizes novel LLM-driven paradigms and includes methods from related recommendation branches such as sequential and knowledge-aware recommendation, thus broadening the scope and applicability.
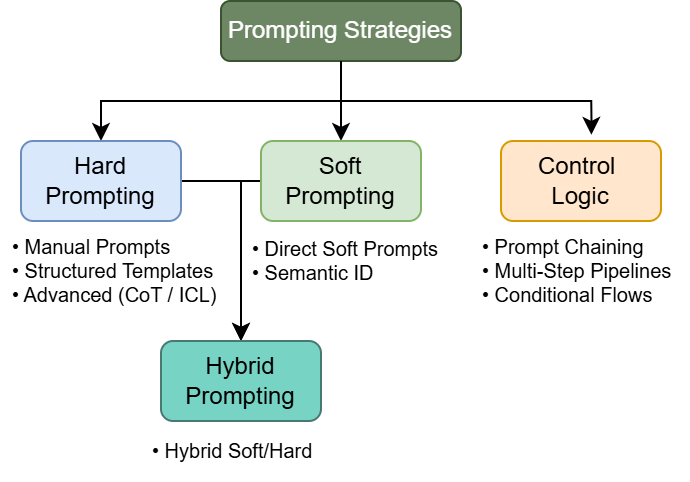
Prompting Strategies in LLM-Based MRS
Prompting is highlighted as a primary interface for LLMs in MRS, facilitating adaptation and rapid task transfer without retraining. The paper identifies multiple prompting strategies:
These strategies are pivotal for addressing cold-start and multi-task scenarios, reducing infrastructure overhead, and supporting zero/few-shot learning.
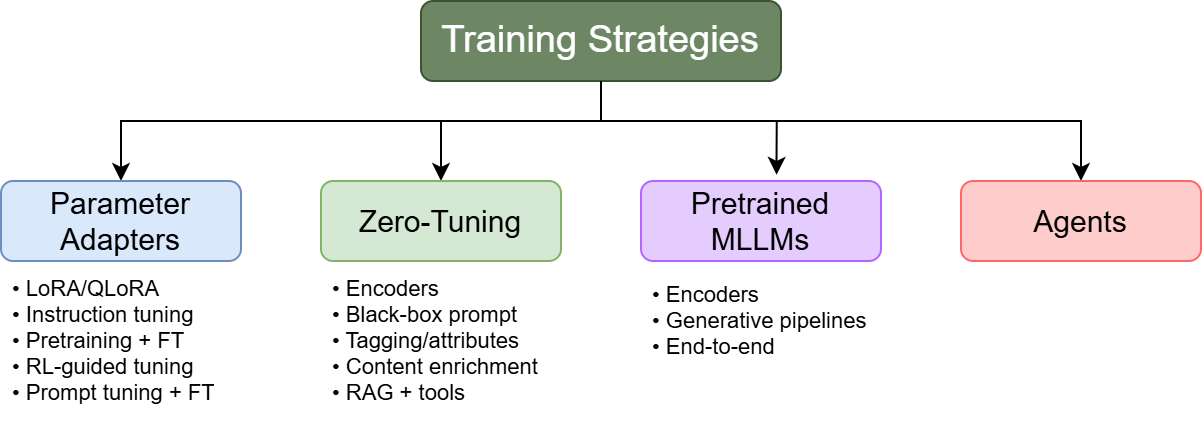
Training and Adaptation Protocols
The survey presents diverse training protocols developed to mitigate computational and accessibility constraints posed by LLMs:
These adaptation routes optimize scalability, support dynamic input handling, and reduce inference latency.
Data Type Adaptation and Modality Integration
Efficient conversion and alignment of non-text modalities for LLM consumption is critical. The paper categorizes adaptation techniques as follows:
This taxonomy is crucial for enabling cross-modal learning without extensive architectural changes.
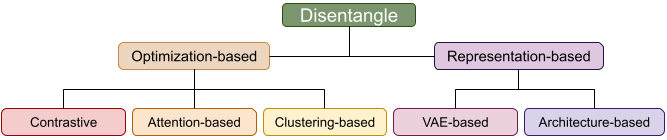
Disentangle, Alignment, and Fusion Mechanisms
The survey analyzes fundamental MRS methods through the lens of LLMs:
This holistic treatment clarifies the synergy between LLM-driven prompting, adaptation, and modality integration, highlighting trade-offs in interpretability, resource demand, and performance.
Evaluation Metrics and Datasets
The paper synthesizes a comprehensive listing of evaluation metrics encompassing both traditional recommendation (Precision@K, Recall@K, NDCG, MAP, HR@K, AUC) and NLP-derived metrics (BLEU, ROUGE, METEOR, BERTScore, BLEURT, CLIPScore, Perplexity). Increasing adoption of LLM-based evaluation protocols signals a shift toward scalable, preference-sensitive assessments. An extensive catalog of datasets for multimodal recommender research is also provided, spanning domains such as e-commerce, fashion, academic, food, and multimedia.
Main Research Trends and Future Directions
Several strong claims and emerging directions are emphasized:
- KGs as a Bridge for Multimodal Integration: KG conversion is positioned as a scalable solution for grounding LLMs, mitigating hallucination, and supporting structured reasoning.
- Soft Prompting & Adapter Fusion: The combination of soft prompting and adapter-based tuning is projected to become a standard for modular and efficient multimodal integration, though further work is needed on fusion order and interference effects.
- Attention Mechanism Synergy: The dynamic fusion of coarse and fine-grained attention based on critical topics is recommended for optimal feature integration.
- Masking and Summarization: Masked contrastive learning and LLM-based summarization remain vital for alignment, particularly in low-resource or unsupervised settings.
- MLLM Utilization: Despite inference overhead, hybrid usage of MLLMs for pretraining or enrichment paired with lightweight deployment architectures is advocated.
- LLM-Based Evaluation: Automated evaluation by LLM judges is noted as a scalable substitute for human assessment, yet introduces risks in reproducibility and alignment.
- Structured Inputs and Agent-Based Reasoning: Trends indicate increasing adoption of structured (JSON, Python class) prompts and retrieval-augmented generation (RAG) in agent orchestration, with implications for interpretability and controllability.
The survey asserts that, although integration of LLMs in MRS is expanding the design space, substantial gaps remain in deployment efficiency, real-time adaptation, and evaluation methodologies.
Conclusion
This survey systematically delineates the transformative role LLMs play in multimodal recommender systems. By transitioning from classic encoder-centric paradigms to reasoning, prompt-driven, and modular adaptation strategies, LLMs grant unprecedented flexibility in semantic representation, cross-modal reasoning, and real-time personalization. The paper’s taxonomy and synthesis provide a rigorous framework for understanding LLM–MRS interactions, highlighting both strong empirical gains and unresolved bottlenecks. Future developments in multimodal recommendation will depend on further research in efficient adaptation, agentic planning, dynamic data fusion, and scalable evaluation—grounded in the technical insights this survey presents.