- The paper provides a comprehensive review of recent techniques in multimodal recommender systems, emphasizing methodologies in feature extraction, encoder design, and fusion strategies.
- It highlights the benefits and challenges of integrating diverse modalities such as text, images, and audio to capture complex user-item interactions.
- It outlines future directions including unified model development and cold-start problem mitigation to further enhance recommendation performance.
A Survey on Multimodal Recommender Systems: Recent Advances and Future Directions
Introduction
Recommender Systems (RS), especially Multimodal Recommender Systems (MRS), have emerged as crucial solutions for addressing the issue of information overload on the internet. Traditional RS models often rely on a single modality, which limits their ability to capture complex user-item interactions. MRS, on the other hand, leverages diverse data modalities such as text, images, video, and audio to enhance the recommendation process. This survey provides a comprehensive review of recent advancements in MRS, focusing on technical categorizations including Feature Extraction, Encoder, Multimodal Fusion, and Loss Function.
Feature extraction in MRS involves deriving low-dimensional, interpretable representations from various modalities. In the visual domain, models like ResNet and ViT are commonly employed, while in the textual field, techniques like BERT and Sentence-Transformer are prevalent. The integration of these features is crucial for accurately capturing user preferences and item characteristics.
Recent studies have highlighted challenges such as handling corrupted data and ensuring the robustness of extracted features. To address these, pre-provided features and pre-trained models are increasingly being utilized, offering a more stable foundation for feature extraction.
Encoder
Encoders in MRS can be categorized into MF-based and Graph-based types. MF-based encoders focus on decomposing the user-item interaction matrix, while Graph-based encoders leverage the graph structures inherent in user-item interactions. Graph-based approaches, including GCN and its variants like LightGCN, are particularly effective due to their ability to incorporate higher-order interactions.
The process of encoding multimodal information often involves choosing between a unified encoder and multiple encoders, depending on the fusion strategy. This choice can significantly affect the ability of the model to learn from multimodal data, either integrating all modalities at once or handling them separately before fusion.
Multimodal Fusion
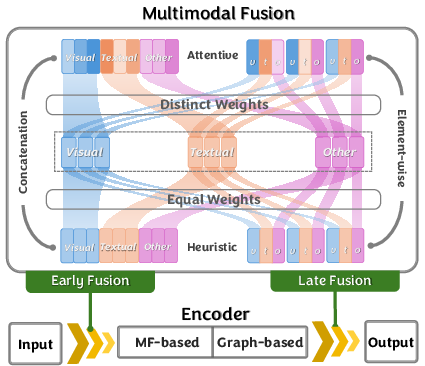
Figure 1: The illustration of Multimodal Fusion.
Multimodal fusion is a key research area in MRS, with strategies categorized based on timing (Early vs. Late fusion) and methodology (Element-wise vs. Concatenation, Attentive vs. Heuristic approaches). Early fusion integrates modalities before the encoding process, possibly uncovering hidden relationships but at the risk of noise. Late fusion focuses on combining outcomes from individual modality-specific encoders, potentially preserving the strengths of each independent modality analysis.
The choice of fusion strategy often interacts with the timing, influencing the model's efficacy in utilizing multimodal data. Comprehensive understanding and careful selection of both aspects are essential for optimizing MRS performance.
Loss Function
Loss functions in MRS consist of supervised and self-supervised components. Supervised learning involves pointwise and pairwise loss, which calibrate predictions against true interactions. In contrast, self-supervised learning, through feature-based and structure-based approaches, exploits the data's inherent structure to generate learning signals without relying exclusively on labels.
Self-supervised methods such as InfoNCE and JS divergence are gaining traction due to their ability to leverage unlabeled data, enhancing the model's robustness and performance in data-sparse scenarios.
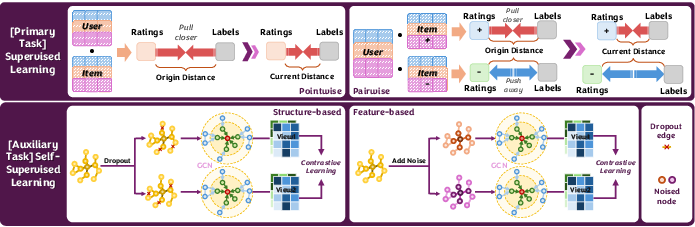
Figure 2: The illustration of Loss Functions.
Future Directions
- Unified MRS Models: Continuous research aims to integrate feature extraction and representation encoding into a single cohesive process. This could alleviate issues stemming from multimodal noise and enhance model efficiency.
- Addressing Cold-Start Problems: Leveraging multimodal data can significantly mitigate cold-start issues, facilitating better adaptation to new users and items by exploiting rich auxiliary information.
- Exploration of New Modalities: Moving beyond visual and textual data, future MRS systems may integrate modalities like audio and olfactory data, offering a richer user experience and deeper personalization.
Conclusion
This survey serves as a comprehensive guide for researchers exploring the field of MRS, providing insights into technological advancements and future research directions. By categorizing recent works and discussing strategic implementations, it aims to facilitate ongoing efforts to develop more sophisticated and effective multimodal recommender systems.