- The paper introduces APEX, integrating decaying action priors with multi-critic reinforcement learning for sample-efficient imitation on articulated robots.
- It demonstrates significant improvements in gait speed and terrain adaptation, achieving peak speeds over 3.3 m/s with robust style consistency.
- The approach mitigates mode collapse seen in adversarial methods, enabling scalable deployment and versatile multi-skill policy learning.
APEX Framework for Skill Imitation on Articulated Robots
Introduction
The APEX framework introduces an innovative approach to overcoming challenges in imitation learning for legged robots. Traditionally, imitation learning (IL) utilizes expert demonstrations to train polymorphic tasks via Behavioral Cloning (BC) which often struggles with effective generalization. Adversarial imitation learning (AIL) via GANs has advanced IL significantly but experiences mode collapse, limiting its real-world applicability due to increased sim-to-real gaps. APEX seeks to address these issues through "Action Priors Enable Efficient Exploration," integrating expert data directly into reinforcement learning (RL) to maintain high exploration efficiency while grounding behavior with expert-informed priors. This integration is facilitated by progressively decaying action priors, which initially bias exploration towards meaningful actions derived from demonstrations but allow more autonomous policy exploration as training progresses. By leveraging multi-critic RL architectures, APEX balances stylistic consistency and task performance, exhibiting sample-efficient imitation learning and multitasking prowess.

Figure 1: (a) A Japanese Spitz exhibiting a canter gait (b) Learned canter gait using animal motion capture data achieves peak speeds > 3.3m/s (c,d) Generalization to stairs and slopes using only flat-ground imitation data preserving the gait trot and canter respectively (e) Gait adaptation based on velocity using a single reinforcement learning policy (f) Extension of APEX to humanoids.
APEX Framework Implementation
APEX's novelty lies in integrating action priors within an RL paradigm to guide policy exploration effectively. The framework capitalizes on decaying action priors, where initial training heavily biases exploration toward expert-like behavior, stemming from feedforward torque calculations based on Proportional-Derivative control parameters on joint angles and velocities. Mathematically, this is formulated as τt=at+γt/kβt, where βt=Kp(θ^t−θt)+Kd(−θ˙t). This setup stabilizes early policy learning by lowering reward sparsity and reducing variance in PPO advantage estimates, contributing to robust policy updates.
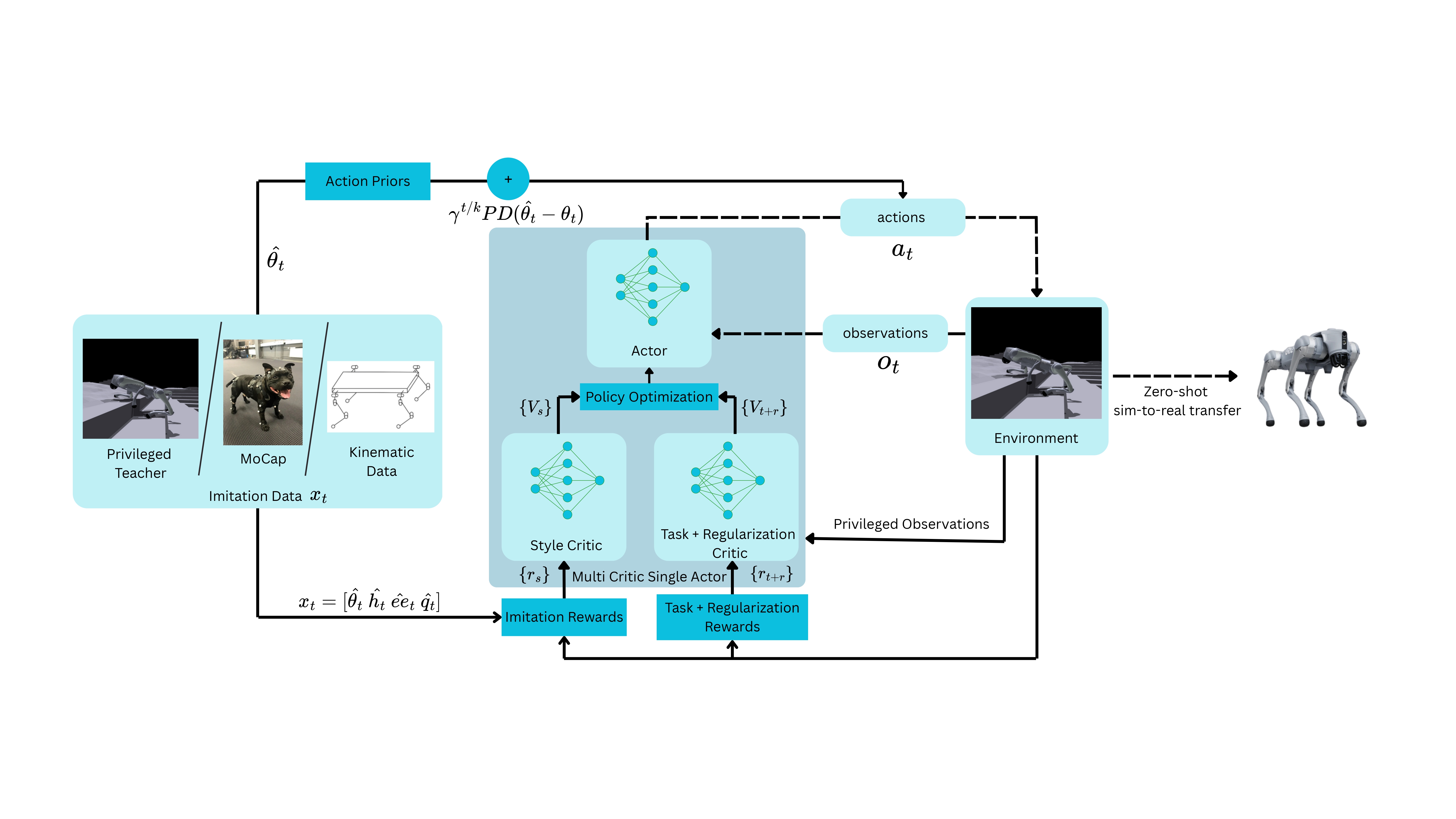
Figure 2: Overview of APEX. Only dashed lines are required during deployment; 1) Imitation data can be collected from various sources; 2) Action Priors are feed-forward torques calculated from kinematic data and added to the actions to bias exploration.
Generalization and Diverse Behavior Learning
APEX's structured exploration translates into efficient training of diverse skills within a unified policy framework. The introduction of a multi-critic architecture, where separate critics provide disjoint reward signals for imitation and task completion, facilitates better style-task balance. Furthermore, the inclusion of phase-based tracking conditions the policy on normalized gait phases, allowing for continuous transformations between distinct behavioral states without external high-level controllers. These mechanisms ensure smooth gait transitions and robust adaptation to unstructured terrains despite the absence of explicit transitional data within the imitation dataset.

Figure 3: (a) Canter gait on uneven slopes (b) Trot gait blindly walking on stairs 5/5 times (c) Robustness of policies trained on flat terrain on uneven terrain (pace gait shown).
In simulation and real-world hardware tests using the Unitree Go2 quadruped, APEX consistently surpasses existing motion imitation frameworks like AMP. APEX policies trained with less data and time achieve high fidelity in executing various gaits with stylistic consistency and adaptability. Notably, APEX achieves peak gait speeds exceeding 3.3 m/s in real-world scenarios, a benchmark unmatched by AMP-trained policies due to their oscillations and sim-to-real barriers. The effectiveness extends to multi-gait learning and terrain generalization, where APEX displays superior ability to maintain behavioral integrity amid domain randomization, an attribute less performant in AMP models prone to conservative drift.

Figure 4: Comparison of single-gait execution in the real world. Each set of images shows the reference motion (top row), APEX (middle row), and AMP (bottom row). APEX matches reference style closely, while AMP shows deviations.
Conclusion
The APEX framework asserts itself as a robust alternative for imitation learning in legged robotics. Its reinforcement learning integrations streamline imitation data utilization without reliance on high-complexity adversarial models, mitigating common pitfalls such as mode collapse and non-trivialization of computational demands. APEX capitalizes on real-world deployment efficacy, exhibiting outstanding generalization across command velocities, terrains, and even humanoid platforms. Its results denote significant strides in mastering efficiency, adaptability, and performance within the field of robotic motion imitation.

Figure 5: Multi-skill policy comparison in real world experiments, showing APEX (top) and AMP (bottom) for pace, pronk, trot, and canter.
In conclusion, APEX demonstrates a pragmatic stride forward in the implementation of imitation learning frameworks, opening new paths toward scalable, deployable robotic systems for diverse applications. Future developments could focus on refining morphological re-targeting processes and integrating exteroceptive sensors for more comprehensive environmental interaction.

