Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL
Abstract: Large reasoning models (LRMs) are proficient at generating explicit, step-by-step reasoning sequences before producing final answers. However, such detailed reasoning can introduce substantial computational overhead and latency, particularly for simple problems. To address this over-thinking problem, we explore how to equip LRMs with adaptive thinking capabilities: enabling them to dynamically decide whether or not to engage in explicit reasoning based on problem complexity. Building on R1-style distilled models, we observe that inserting a simple ellipsis ("...") into the prompt can stochastically trigger either a thinking or no-thinking mode, revealing a latent controllability in the reasoning behavior. Leveraging this property, we propose AutoThink, a multi-stage reinforcement learning (RL) framework that progressively optimizes reasoning policies via stage-wise reward shaping. AutoThink learns to invoke explicit reasoning only when necessary, while defaulting to succinct responses for simpler tasks. Experiments on five mainstream mathematical benchmarks demonstrate that AutoThink achieves favorable accuracy-efficiency trade-offs compared to recent prompting and RL-based pruning methods. It can be seamlessly integrated into any R1-style model, including both distilled and further fine-tuned variants. Notably, AutoThink improves relative accuracy by 6.4 percent while reducing token usage by 52 percent on DeepSeek-R1-Distill-Qwen-1.5B, establishing a scalable and adaptive reasoning paradigm for LRMs. Project Page: https://github.com/ScienceOne-AI/AutoThink.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL”
What is this paper about?
This paper is about teaching AI LLMs to be smart about when to “think out loud.” Some problems need detailed step-by-step reasoning, but many don’t. Writing out lots of steps makes the AI slower and more expensive to run. The authors show how to help these models decide, on their own, whether to do detailed thinking or give a quick answer.
What questions are the researchers trying to answer?
- Can we stop AI models from “overthinking” (writing extra steps that aren’t needed) without hurting accuracy?
- Can a model learn to think deeply only on hard problems and answer briefly on easy ones?
- Is there a simple way to control this behavior that works across different models?
How did they do it? (Methods explained simply)
First, a bit of background:
- Many modern reasoning AIs (called “R1-style models”) are trained to show their work using a special format: they write reasoning inside a “> … </think>” section and then give the final answer.
>
> - This improves accuracy on tough questions but can waste time on easy ones.
>
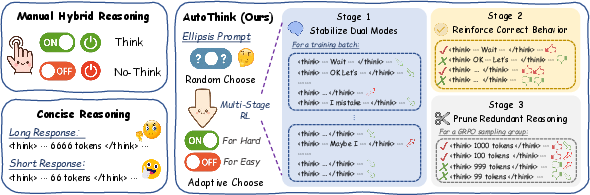
> The authors discovered a neat trick:
>
> - If you put just three dots “...” after “<think>” (like writing “<think> …”), the model sometimes decides to think a lot, and sometimes decides to think very little or not at all. It’s like giving the model a pause and letting it choose how much to explain.
>
> But a tiny prompt change isn’t enough to make the model difficulty-aware (it didn’t reliably think more on hard problems and less on easy ones). So they trained the model with reinforcement learning (RL), which is like giving points for good behavior:
>
> - Think of RL as a game: the model tries different behaviors and gets rewards or penalties based on how helpful they are.
>
> They trained in three stages:
>
> - Stage 1: Keep both “modes” alive. Prevent the model from always thinking or never thinking. If too many examples use one mode, the rewards nudge it back toward balance.
>
> - Stage 2: Get good at both modes. Reward correct answers more, whether the model is thinking or not. This builds accuracy while keeping mode flexibility.
>
> - Stage 3: Trim the fluff. Add rewards that prefer shorter responses when the model is already correct, and allow longer ones when it’s struggling. In short: be brief when right, be thorough when needed.
>
> Analogy: Imagine a student who learns:
>
> 1. not to always show all steps or always skip them,
>
> 2. to get the answer right whichever approach they choose,
>
> 3. to write less on easy questions and show more work on hard ones.
>
> ### What did they find, and why does it matter?
>
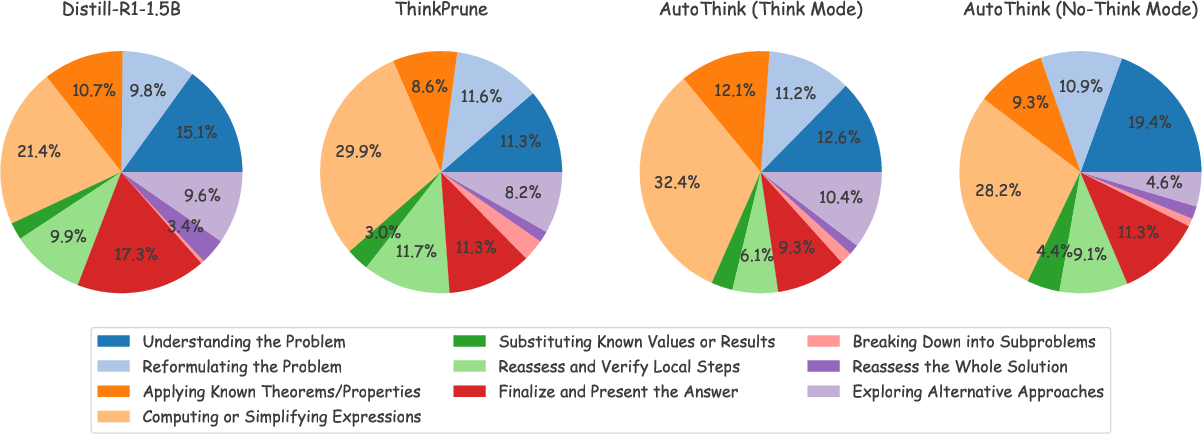
> - The method, called AutoThink, helped the AI automatically choose when to think deeply.
>
> - On five math benchmarks, it gave a better balance between accuracy and speed than other methods that either force short answers or cut steps uniformly.
>
> - A standout result: on a popular 1.5B-parameter model (DeepSeek-R1-Distill-Qwen-1.5B), AutoThink increased accuracy by about 6.4% while cutting token usage (the amount it writes) by 52%. That means better answers with about half the typing—faster and cheaper.
>
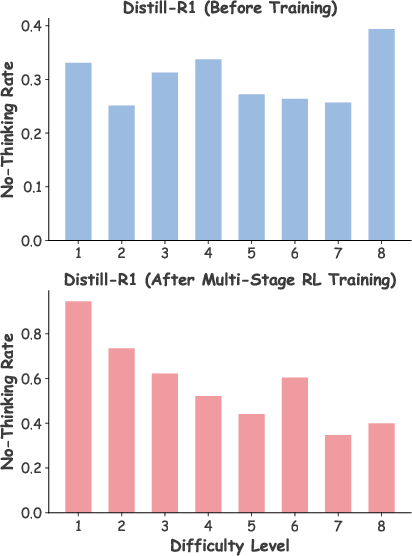
> - After training, the model actually thought more on harder problems and less on easier ones—exactly what we want.
>
> - It works as a drop-in upgrade to many R1-style models (both smaller and larger ones).
>
> ### Why is this important?
>
> - Faster and cheaper: Less unnecessary text means lower cost and quicker responses.
>
> - Smarter behavior: The model thinks like a good student—only showing steps when needed.
>
> - Scalable: It can be added to different models without redesigning everything.
>
> - Practical: Helpful for math, coding, and other tasks where sometimes a quick answer is enough.
>
> ### What are the possible impacts and next steps?
>
> - This approach could make reasoning AIs more efficient for real-world apps (tutors, assistants, search tools), saving time and money.
>
> - It may reduce energy use by cutting extra computation, which is better for the environment.
>
> - Future improvements could:
> - Enforce a strict “budget” (for example, “never write more than X steps”).
> - Stop rare cases where the model hides thinking after the tag.
- Use smarter data selection to train even better.
Overall, AutoThink shows a simple, effective way to teach AI when to think hard and when to keep it short—leading to better results with less effort.
Collections
Sign up for free to add this paper to one or more collections.