- The paper presents a novel framework that dynamically switches between fast and slow thinking modes to substantially reduce redundant reasoning steps.
- The methodology involves identifying reasoning paradigms, curating an SFT dataset, and applying a dual-reference KL-divergence loss for precise mode switching.
- Experimental results demonstrate significant reductions in token usage (up to 68.2%) and improvements in accuracy across various tasks.
Dynamic Thinking Mode Switching for Efficient Reasoning
The paper "OThink-R1: Intrinsic Fast/Slow Thinking Mode Switching for Over-Reasoning Mitigation" (2506.02397) introduces a novel approach to enhance the efficiency of large reasoning models (LRMs) by enabling them to dynamically switch between fast and slow thinking modes. The core idea is to mitigate the over-reasoning problem, where LRMs expend excessive computational resources on simple tasks that can be solved more efficiently by non-reasoning LLMs. OThink-R1 prunes redundant reasoning steps while preserving logical validity, leading to reduced token usage without compromising accuracy.
Methodology
The OThink-R1 framework operates in three key stages, which are illustrated in (Figure 1): identifying reasoning paradigms, constructing a supervised fine-tuning (SFT) dataset with curated trajectories, and performing SFT with a dual-reference KL-divergence loss.
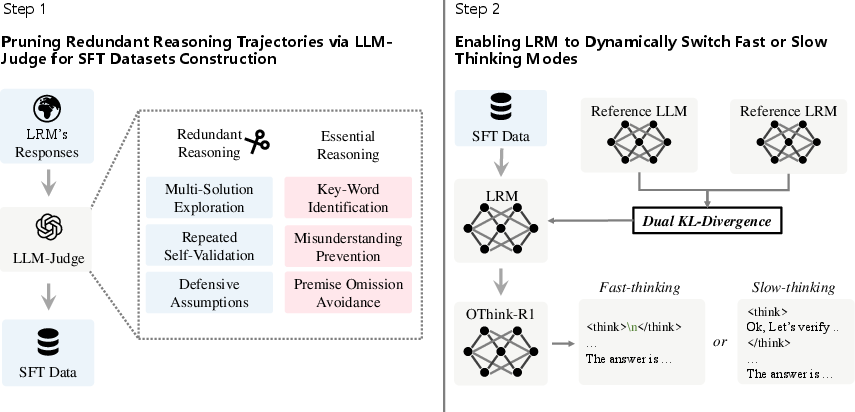
Figure 1: Schematic diagram of the OThink-R1 framework, illustrating the dynamic switching between fast and slow thinking modes.
Identifying Reasoning Paradigms
The authors systematically analyze the reasoning trajectories of LRMs and categorize them into redundant and essential reasoning paradigms. Redundant reasoning includes patterns like multi-solution exploration, repeated self-validation, and defensive assumptions. Essential reasoning, on the other hand, encompasses key-word identification, misunderstanding prevention, and premise omission avoidance. The paper highlights that non-reasoning LLMs can solve a substantial portion of tasks with significantly fewer tokens (Table 1).
SFT Dataset Construction
Based on the identified paradigms, the authors construct an SFT dataset by pruning redundant reasoning trajectories. An LLM-Judge (GPT-4o) is employed to classify reasoning trajectories as either redundant or essential. For tasks where fast-thinking LLMs yield correct answers and the reasoning trajectories of LRMs are judged redundant, the trajectories are pruned, retaining only the immediate responses. This curated dataset promotes the adaptive use of fast or slow thinking depending on the problem.
SFT with Dual Reference KL-Divergence Loss
To enhance the model's dynamic switching ability, a novel loss function is introduced. This loss function incorporates a dual-reference KL-divergence constraint, leveraging guidance from both fast and slow thinking variants of the same model architecture. This strengthens the model's ability to dynamically switch between the two modes while simultaneously learning the output distributions of both reference models. The hybrid loss function is defined as:
$\mathcal{L}_{\text{hybrid} = -\mathbb{E}_{(x,y)\in\mathcal{D}_{\text{SFT}\Big[\log\pi_{\theta}(y\vert x)\Big] + \beta_1 \text{KL}(\pi_{\theta}\Vert\pi_{\text{LRM}) + \beta_2 \text{KL}(\pi_{\theta}\Vert\pi_{\text{LLM})$
where β1 and β2 are hyperparameters that regulate the retention level of the slow thinking mode relative to the reference distribution of LRMs, and the alignment strength of the fast thinking mode with the distribution of non-reasoning LLMs, respectively.
Experimental Results
The authors implement OThink-R1 into the Deepseek-R1-Distill-Qwen series, with varying model sizes. Experiments across mathematical and question-answering tasks demonstrate that OThink-R1 reduces reasoning redundancy by almost 23\% on average without compromising accuracy. Specifically, the average accuracy improves by 3.2\%, 1.3\%, and 0.35\%, while the average number of generated tokens decreases substantially by 68.2\%, 13.9\%, and 21.4\%, respectively. Further analysis reveals that the enhanced model employs fast thinking on more than 27.3\% of problems.
An ablation study (Table 3) confirms the necessity of each component of the OThink-R1 framework, including trajectory pruning, LLM-Judge, and the dual KL-divergence constraint. Removing any of these components leads to a drop in performance or an increase in token usage.
A case study (Figure 2) illustrates how OThink-R1 utilizes the fast-thinking mode to solve a problem correctly, while a reasoning model exhibits overthinking and derives an incorrect answer.

Figure 2: Comparison of a generated response by OThink-R1 using fast-thinking and a standard reasoning model on CommonsenseQA.
Implications and Future Work
The OThink-R1 framework has significant implications for the development of more efficient and adaptive AI systems. By enabling LRMs to dynamically switch between fast and slow thinking modes, the framework reduces computational overhead and improves resource utilization. This approach can lead to more sustainable and scalable AI deployments, particularly in resource-constrained environments.
The authors acknowledge the limitation of using an LLM-Judge to determine redundant reasoning trajectories and suggest that future work should focus on end-to-end identification of redundant reasoning and the design of more specific criteria. Extensions to multimodal reasoning and broader model architectures are also identified as promising directions for future research.
The approach of adaptively selecting between reasoning modes based on task complexity aligns with cognitive theories of human problem-solving [kahneman2011thinking]. This alignment suggests that incorporating cognitive principles into AI design can lead to more efficient and human-like reasoning systems. Future research could explore other cognitive strategies, such as meta-cognition and attention mechanisms, to further enhance the adaptability and efficiency of LRMs.
The dual reference KL-divergence loss is a notable contribution that enables the model to adopt the cautious reasoning style of LRMs during slow thinking while retaining the efficient generation capabilities of base LLMs during fast thinking. Alternative approaches such as SimPO [meng2024simpo] could potentially provide similar benefits in dynamically balancing different thinking modes.
Conclusion
The paper presents a compelling approach to mitigating over-reasoning in LRMs by enabling dynamic switching between fast and slow thinking modes. The OThink-R1 framework combines systematic analysis of reasoning trajectories, a curated SFT dataset, and a novel dual-reference KL-divergence loss to achieve significant improvements in efficiency without compromising accuracy. The experimental results and ablation studies provide strong evidence for the effectiveness of the proposed approach. This work contributes valuable insights and practical guidelines for the development of more efficient and adaptive AI reasoning systems.