- The paper formalizes the gap between explicit language structure and latent human reasoning using Structural Causal Models.
- It identifies a bias in next-token prediction, showing that LLMs often struggle with System 2 inferential tasks due to anti-topological token ordering.
- Empirical evaluations on 11 benchmarks demonstrate that prompt interventions like Echo, Expand, and the combined LoT method significantly enhance reasoning accuracy with reduced token costs.
On the Thinking-Language Modeling Gap in LLMs
Introduction and Motivation
The paper "On the Thinking-Language Modeling Gap in LLMs" (2505.12896) addresses a crucial problem in the deployment and understanding of LLMs: the disparity between modeling explicit language and the underlying process of human reasoning, or the "language of thought" (LoT). Building on dual-process theory—distinguishing System 1 (implicit, fast processes) and System 2 (explicit, logical reasoning)—the paper formalizes how the next-token prediction paradigm prevalent in LLMs introduces a bias: LLMs emulate the external language structure rather than the internal cognitive chains that underpin robust reasoning, often resulting in failures in System 2-style inferential tasks.
The authors utilize Structural Causal Models (SCMs) as an analytical framework to separate latent thought variables from their linguistic expressions. The SCM formalization specifies that human-written texts reflect a causal sequence among mental events, but that the ordering or linguistic expression in natural language often diverges from the topological (causal) order in the underlying reasoning graph.
For example, in a two-premise QA setting, the paper demonstrates that differing sentence orders ("premise A, conclusion, premise B" vs. "premise A, premise B, conclusion") can encode identical semantics for humans due to causal understanding but confuse LLMs, which are trained to predict the next token based only on prior tokens. The result is a language-modeling bias: the model's conditional distributions may omit critical premises when they fall after the conclusion in the text sequence, leading to shortcut or marginal reasoning.
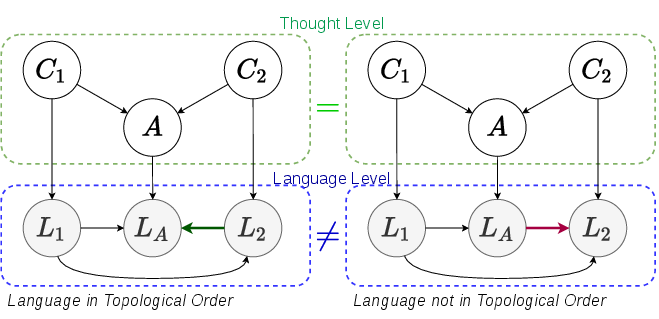
Figure 1: Different SCMs. Left: State conclusion at last; Right: State conclusion earlier.
Theorem 1 explicitly quantifies this bias, showing that even when an LLM could in principle represent correct relations between abstract variables, implicit language expressions or anti-topological token orders can compromise inference, with a lower bound that grows with the confusion (as measured by variational distance) between expressions and their latent referents.
Empirical Verification: Controlled Bias and Prompt-Level Interventions
The paper introduces the WinoControl dataset, modifying the canonical WinoBias task to precisely control L-implicitness (local ambiguity in how information is linguistically encoded) and q-implicitness (contextual or global ambiguity due to surrounding information). This enables systematic measurement of reasoning biases as a function of expression explicitness.
LLMs, including GPT-4o-mini and large open models, were prompted using standard Chain-of-Thought (CoT) methods and with novel interventions termed "Echo", "Expand", and a combined method, LoT (Language of Thought prompting).
- Echo: Instructs the LLM to "observe and echo all the relevant information," targeting reductions in q-implicitness by making the model enumerate key context.
- Expand: Instructs the LLM to "expand all the relevant information," targeting L-implicitness by encouraging the model to restate or clarify contextually obfuscated premises.
- LoT: Combines both interventions for maximal mitigation.
Performance was evaluated across various implicitness levels. The results show a consistent negative correlation between implicitness (especially anti-topological ordering and implicit premises) and reasoning accuracy using CoT alone. Both Echo and Expand outperform CoT, and the combined LoT method yields the best results in most settings.
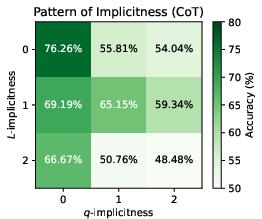
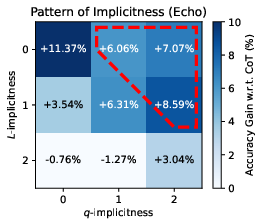
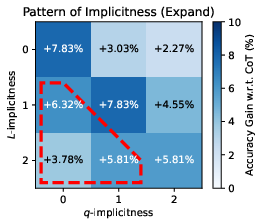
Figure 2: The accuracy patterns on combinations of L- and q-implicitness.
Notably, token cost analysis reveals that these interventions do not mechanically improve performance just by increasing response length—Echo, in particular, often outperforms other prompts with lower token costs.
Case studies on BBQ and WinoBias elucidate the distinct failure modes of single interventions (Echo or Expand) and show that their composition in LoT can overcome many of these deficiencies.

Figure 3: Case study on BBQ and WinoBias, highlighting responses from Echo, Expand, and their combination to diagnose limitation points.
Large-Scale Evaluation on Reasoning and Bias Benchmarks
The interventions were stress-tested on 11 benchmarks: math (Alice), social bias (WinoBias, BBQ), and general reasoning (GPQA, FOLIO, CommonsenseQA, MUSR, MUSIQUE, AGIEval-LSAT, abductive and deductive inference). Evaluations spanned multiple SOTA LLMs (DeepSeek-V3, GPT-4o-mini, Qwen-2-72B-Instruct, Llama-3.1-70B-Instruct, etc.), with CoT, Direct prompting, RaR, LtM, and the proposed LoT series as comparators.
Across almost every setting, LoT-based prompting delivered increased robustness, higher accuracy, and sharper reductions in bias than any baseline, with improvements most pronounced in tasks requiring nuanced integration of multiple, potentially implicitly expressed premises.
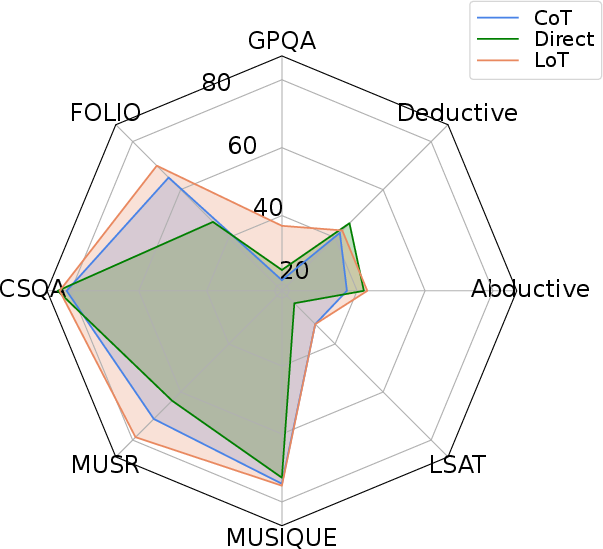
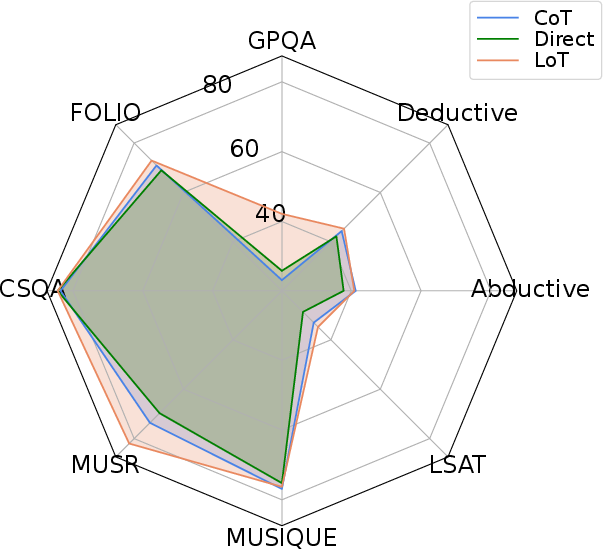
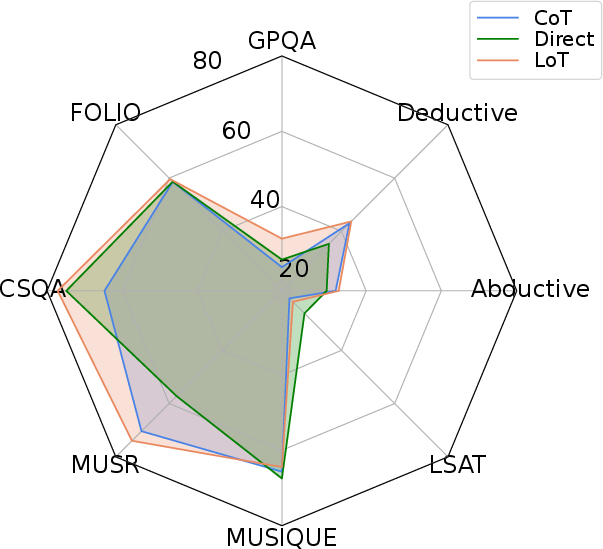
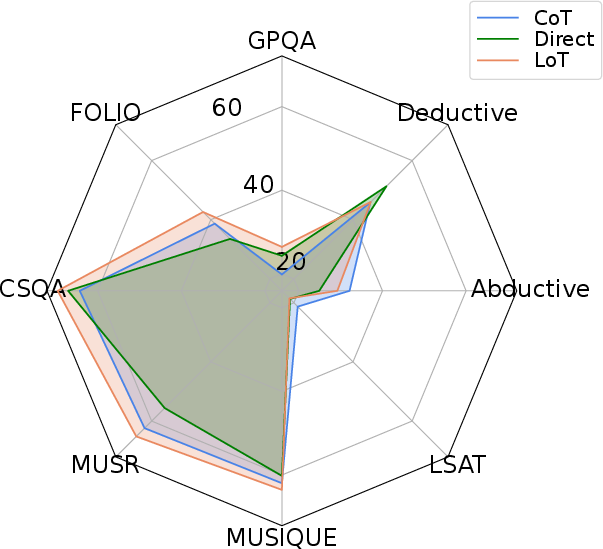
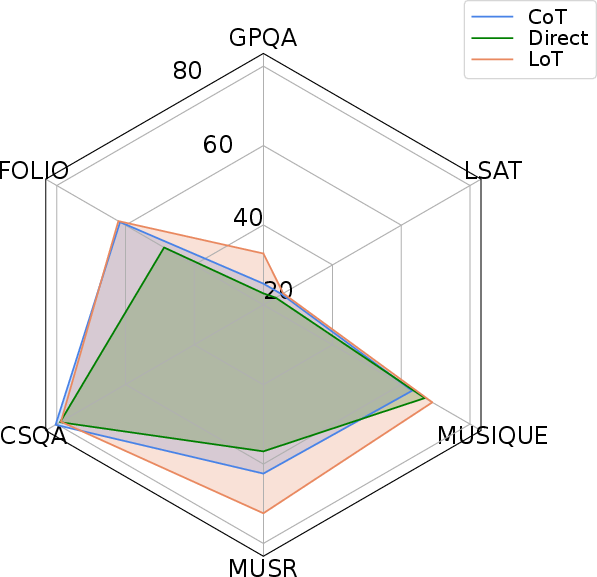
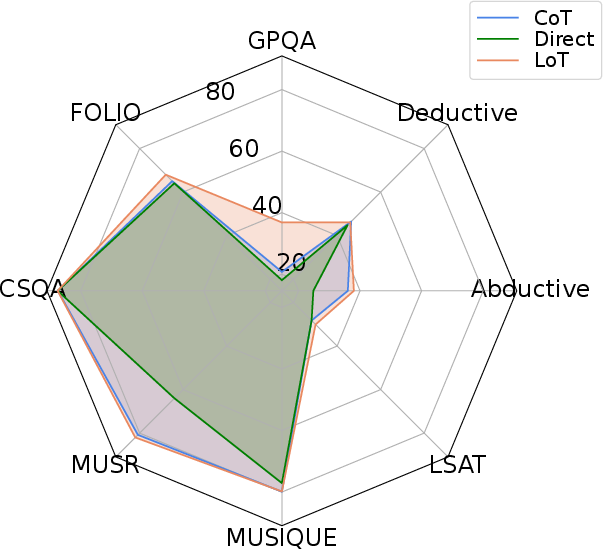
Figure 4: Comparison with Direct and CoT prompting across 8 reasoning benchmarks and 6 LLMs.
The ablation studies highlight that tasks with strong L-implicitness (e.g., Alice, WinoBias) benefit disproportionately from Expand, while q-implicitness-heavy tasks (e.g., BBQ) are more amenable to Echo. The composite LoT prompt consistently performs best or second best in the majority of conditions.
Theoretical and Practical Implications
These results have concrete implications:
- Theoretical insight: Next-token prediction imbues LLMs with a strong dependence on token order and explicitness, which diverges from the causal semantics of human thought. Even with powerful models, biases induced in training can only be partially mitigated via prompting.
- Prompt engineering: Carefully crafted meta-level instructions (LoT) that force LLMs to expand and echo relevant information demonstrably close part of the reasoning gap and suppress expression-induced biases.
- Model and training design: The persistence of the gap points toward limitations in the next-token paradigm itself. Integrating causal modeling and explicit latent reasoning supervision may be necessary for true System 2 abilities in LLMs.
- Evaluation: Benchmarking LLMs on controlled linguistic and reasoning ambiguities reveals latent failure points in current CoT approaches that are masked in standard accuracy metrics.
Prospective Research Directions
Future research should address:
- Algorithmic intervention: Beyond prompt engineering, integrating causal structure discovery and explicit latent thought modeling into LLM training.
- Instruction tuning: Systematic use of interventions like LoT in pretraining or finetuning regimens to robustify models against implicitness-induced reasoning failures.
- Automated diagnosis: Development of tools to detect and measure L- and q-implicitness in real-world data, guiding both model improvement and benchmark construction.
- Neurosymbolic and hybrid approaches: Blending symbolic SCM logic with neural language modeling to bridge the gap identified here.
Conclusion
This work rigorously delineates and quantifies the "thinking-language modeling gap" in LLMs, both theoretically and empirically. By leveraging SCMs, controlled benchmarks, and prompt-level interventions, the authors reveal systematic limitations in prevailing LLM training and reasoning paradigms. The proposed LoT prompting demonstrates a practical pathway to mitigate biases arising from anti-causal or implicit language ordering but also highlights the fundamental obstacles for universal System 2 reasoning with next-token-prediction LLMs. Bridging this gap will necessitate both architectural and training paradigm innovations in future AI systems.