- The paper introduces a robust, rubric-agnostic reward model framework that enhances interpretability and flexibility for aligning language models with human preferences.
- It employs a unified training process using both hand-crafted and model-generated rubrics to support point-wise, pair-wise, and binary evaluations across diverse tasks.
- Benchmark results show that the R3 framework outperforms traditional rubric-based models, offering improved generalizability and transparency on RM-Bench and RewardBench.
R3: Robust Rubric-Agnostic Reward Models
The paper "R3: Robust Rubric-Agnostic Reward Models" (2505.13388) presents a novel framework for reward modeling in NLP tasked with aligning LLM outputs to human preferences. The motivation stems from the current limitations in reward modeling, particularly in terms of the lack of controllability and interpretability in existing models, along with their constrained generalizability across diverse tasks and evaluation criteria.
Introduction and Motivation
Traditional reward models, which are integral for LLM alignment, often suffer from limited scalability and interpretability. The authors aim to tackle issues such as limited controllability—where models are overly narrow in scope and lack the flexibility to adjust to unseen evaluation criteria—and interpretability challenges, where scalar scores fail to impart any actionable insights due to inadequate description and contextual reasoning. The paper emphasizes the importance of aligning LLMs with diverse human values to extend their usability across a variety of downstream applications.
Robust Rubric-Agnostic Framework
black: Robust Rubric-Agnostic Framework
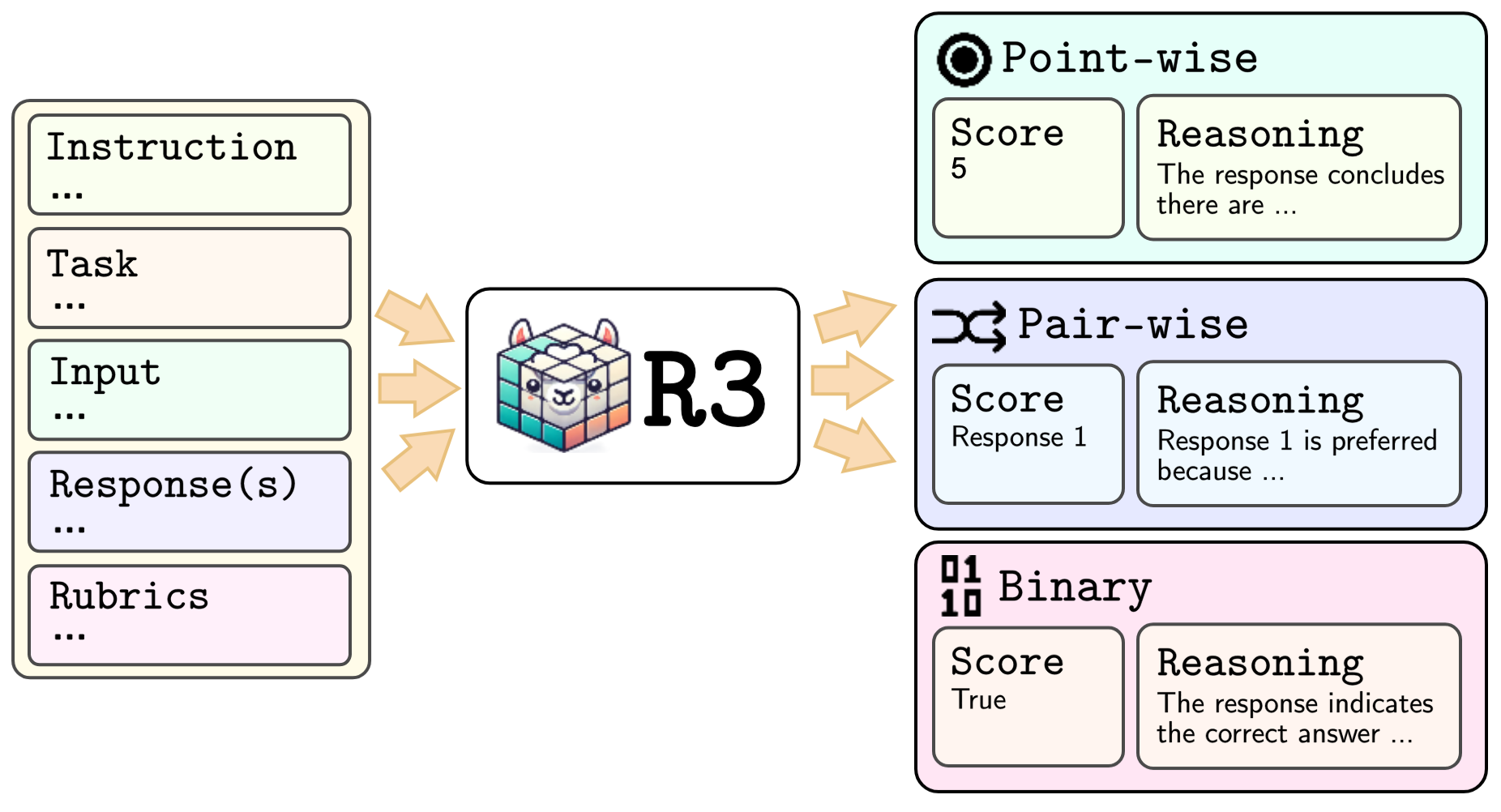
Figure 1: black (black) models both the input and output of a task. It takes a prompt that includes an instruction, task description, input, response(s), and evaluation rubrics, and generates a score along with the corresponding reasoning.
The cornerstone of this research is the introduction of the black model. Unlike existing rubric-based systems requiring external rubrics, black, by its design, is rubric-agnostic and highly generalizable across different evaluation dimensions. The presented framework supports task-agnostic robust reward model training, leveraging fine-grained rubrics to provide controllable, interpretable scores, thus enabling transparent evaluation of LLMs. By employing both hand-crafted and model-generated rubrics, the method supports a unified structure for training reward models using point-wise, pair-wise, and binary formatted datasets. This feature permits adapting data into standardized forms, amplifying the model's efficacy in handling diverse domains and tasks.
Dataset Sources for Training
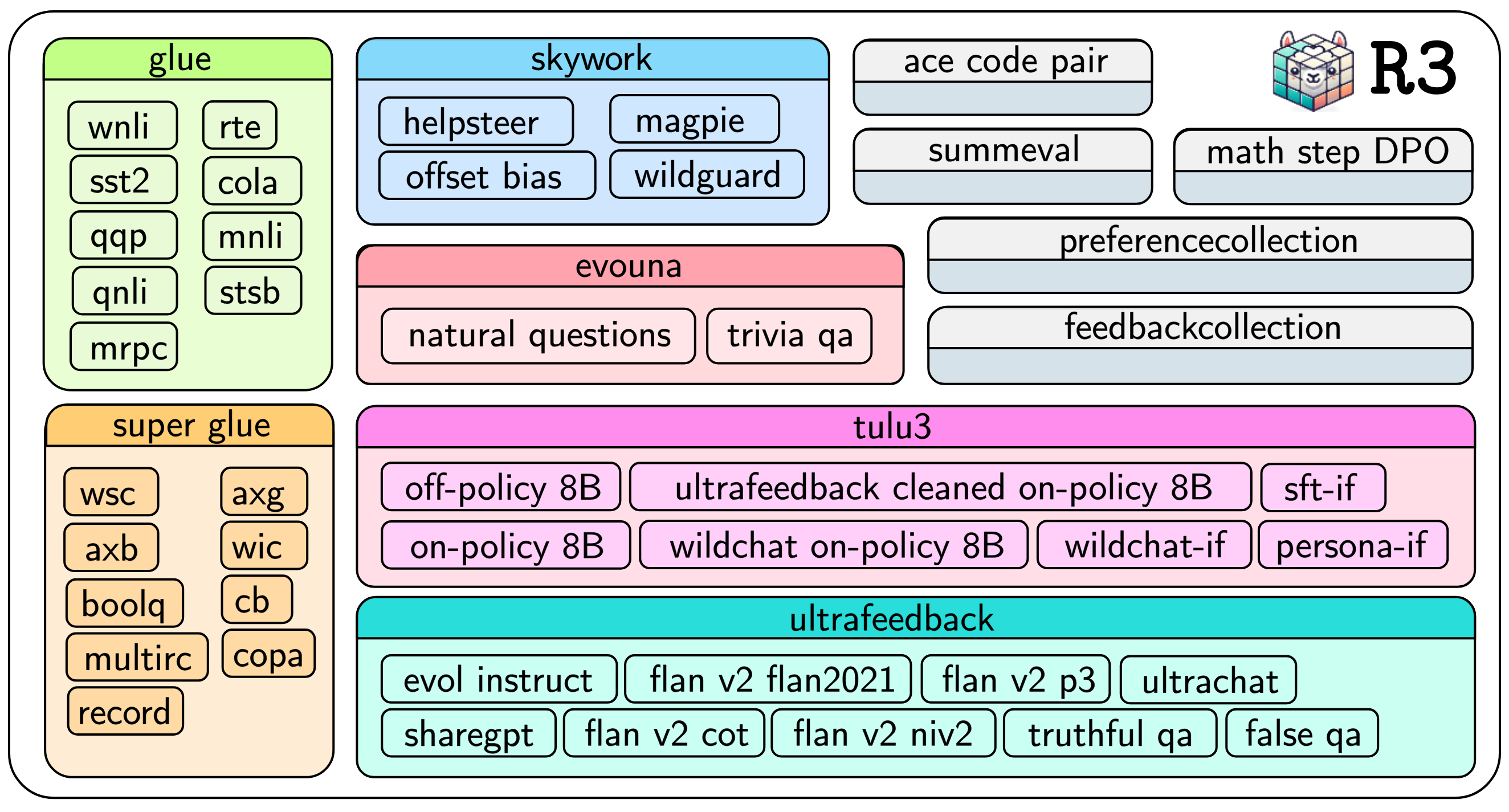
Figure 2: Dataset sources utilized in training the black model.
R3 constructs new datasets from 45 varied sources, targeting tasks such as classification, preference optimization, and question answering. This effort addresses the challenge that existing datasets lack consistent evaluation rubrics and machine-assisted explanation traces. To ensure a representative sample set, a nuanced diversity sampling method is applied. The training data is further refined through multi-stage curation and rubric generation, ensuring high-quality input for the development of robust reward models.
The unified framework proposed supports three evaluation formats:
- Point-wise Evaluation: Assigns integer scores (e.g., 1–5) for single responses, suitable for tasks requiring scalar quality measures.
- Pair-wise Evaluation: Compares two responses, selecting the preferred one based on specific criteria.
- Binary Evaluation: Executes definitive judgments on correctness utility, critical for tasks like factual verification or simple binary assessments.
The methodology demonstrates superior performance against existing models on established benchmarks such as RM-Bench and RewardBench. The black models not only achieve—often surpass—proprietary models and established baselines under constrained datasets and computational resources but do so with transparency and interpretable scores. Notably, the black framework outperformed competitive models across key evaluation domains, demonstrating enhanced generalizability and interpretability.
Implications and Future Directions
The R3 framework has significant potential implications for both academic research and practical applications. The introduction of rubric-agnostic reward models promises advancements in flexible and transparent alignment technologies for LLMs, catering to a broader array of human values and contexts. Potential future research could focus on expanding the dimensions and domains addressed by such models, pushing towards finer scalability, improved efficiency, and further integration with RL techniques for enhanced model adaptation.
Conclusion
The paper delineates the R3 framework that crafts a significant stride towards more flexible and interpretable reward models. By circumventing the limitations of existing rubric-dependent approaches, black models introduce a versatile model capable of consistently high performance under diversified and resource-constrained scenarios. This development marks a notable step in aligning NLP models with human preferences with greater clarity and adaptability, fueling innovation and reliability in AI evaluation mechanisms.