- The paper introduces MemoryEQA, a framework that centralizes hierarchical, multi-modal memory for integrated planning, stopping, and answering in embodied Q&A tasks.
- It demonstrates an 18.9% gain in success rate on multi-target datasets and a ~25% improvement in step efficiency over planner-centric models.
- Empirical results on MT-HM3D and real-world deployments validate that dynamic memory retrieval enhances semantic reasoning and reduces redundant exploration.
Memory-Centric Embodied Question Answering: Framework, Mechanisms, and Empirical Analysis
Introduction and Motivation
Memory-Centric Embodied Question Answering (EQA) introduces a principled shift from planner-centric architectures to a memory-driven reasoning paradigm for interactive agents operating in dynamic environments. The MemoryEQA architecture pivots on hierarchical, multi-modal memory that is injected into the agent’s planner, answering module, and stopping module, resulting in more efficient multi-region, multi-target exploration and improved answering accuracy. In contrast to existing methods where the memory module is siloed and often unable to affect planning decisions directly, MemoryEQA treats memory as the central substrate for all inter-module interactions.
The shortcomings of planner-centric methods are illustrated in multi-entity tasks, where failure to leverage exploration history leads to redundant trajectories (Figure 1).
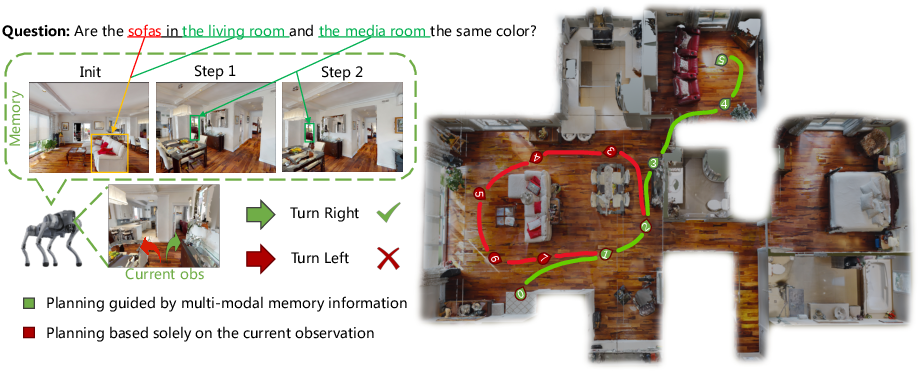
Figure 1: Memory-guided reasoning avoids redundant exploration by leveraging entity state recall, unlike planner-centric baselines.
Embodied Question Answering tasks assess agents’ ability to combine semantic reasoning, navigation, and environmental understanding [das2018embodied, gordon2018iqa]. Prior works (e.g., ExploreEQA, Embodied-RAG [xie2024embodied], GraphEQA [saxena2024grapheqa]) explored planner-centric module orchestration, semantic or episodic memory in vector or topological forms [anwar2024remembr, chaplot2020object]. These approaches inadequately support multi-modal, multi-target queries due to insufficient cross-module memory utilization and rigid memory organization.
MemoryEQA supersedes these limitations by dynamically retrieving, updating, and injecting both global (semantic scene maps, entity states) and local (object observations, VLM-annotated descriptions) memory for planning, stopping, and answering processes.
Framework Architecture
The overall architecture is demonstrated in Figure 2. The agent gathers visual and state observations, updates hierarchical memory, retrieves query-relevant entries, and injects them into downstream modules. Planning decisions are conditioned on annotated candidate directions and concatenated memory-question context fed to the VLM; stopping is guided by memory-derived confidence prediction; the answering module leverages only query-relevant retrieved entries for response synthesis.
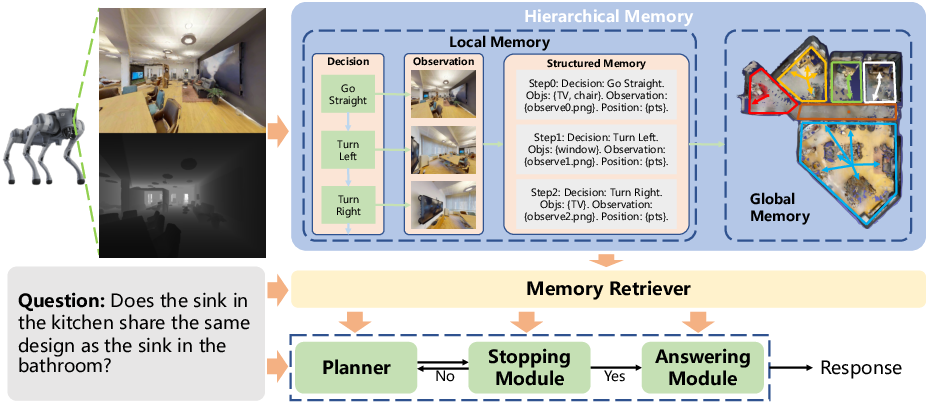
Figure 2: Memory-centric EQA system diagram, highlighting memory update, retrieval, and injection for multi-modal reasoning and navigation.
The hierarchical memory structure (see Figure 3) maintains global memory via annotation of entity states on a real-time scene map, alongside local memory composed of visual observation and fine-grained object information. Both are indexed for rapid retrieval using dense vector search via unified encoders (Clip-ViT-Large).
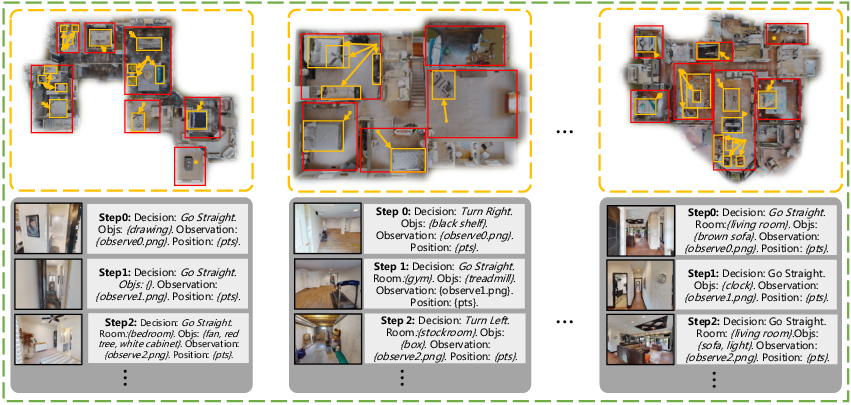
Figure 3: Hierarchical memory organization, integrating global semantic map annotation and local object-centric visual/attribute features.
Discrete stop criteria are computed via VLM-prompted confidence reasoning. Real-time memory update mechanisms are triggered by spatial and semantic novelty, with integration of SSIM and vector similarity for efficient state change detection.
Multi-Target Dataset Construction
To rigorously evaluate memory-centric reasoning, the MT-HM3D dataset was introduced, extending HM3D with 1,587 multi-target, multi-region questions across 500 scenes. The data construction leverages GPT-4o and manual verification to sample diverse task types: comparison, relationship, counting, and attribute, designed to stress agents’ long-term memory and reasoning capabilities.
Empirical Results
MemoryEQA achieves an 18.9% gain in success rate over baseline planner-centric models on MT-HM3D, reaching 55.1% with GPT-4o, and establishes SOTA on OpenEQA and near-SOTA on HM-EQA. Step efficiency improvements of ~25% compared to baselines are demonstrated.
Ablation analysis reveals additive benefits of memory injection across modules. The planner module, when memory-enhanced, is crucial in eliminating redundant navigation (Figure 4).
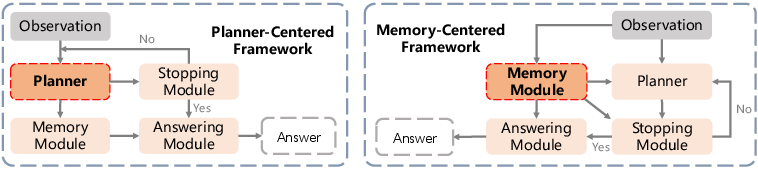
Figure 4: Schematic comparison highlighting planner-centric and memory-centric frameworks.
Injecting memory into stop and answering modules (S+A+P) yields peak performance on both complex multi-target (MT-HM3D) and more conventional HM-EQA tasks. Both global and local memory modalities contribute distinctly—global memory improves exploration efficiency whereas local memory enhances fine-grained answering accuracy.
Real-World and Visualization Studies
Experiments with the Unitree Go2 robot in office and staged environments validated that hierarchical memory prevents double-counting and supports rapid, correct attribute reasoning. A two-round QA visualization (Figure 5) further underscores how persistent memory empowers second-round exploration optimization and reduced step counts.

Figure 6: Real-world agent deployment demonstrates memory-centric framework efficacy in open scenario and office environments.

Figure 5: Two-round QA on HM3D, showing planning points for baseline (red) and MemoryEQA trajectories (green) exploiting exploration-acquired memory for improved efficiency.
Limitations and Future Work
Current exploration strategies remain heuristic, and the model may occasionally answer questions without verifiable relevance of exploration-derived memory. Evaluation metrics may not fully capture reasoning traceability. Future work includes trajectory annotation enrichment and development of process-aware metrics evaluating agent memory utilization and decision validity.
Conclusion
The MemoryEQA paradigm advances embodied QA by centralizing memory as a dynamic, multi-modal foundation driving planning, stopping, and answering. Hierarchical memory with real-time update and retrieval mechanisms demonstrably optimizes efficiency and robustness in multi-target, multi-scenario environments, as evidenced by strong empirical gains. The framework, supported by the MT-HM3D benchmark, establishes new best practices for memory-centric agent design, with broad implications for lifelong learning, continual reasoning, and scalable robotic cognition. Future research should address richer memory representation, exploration interpretability, and process-level evaluation to further integrate autonomous agents into real-world semantic-scene reasoning contexts.