- The paper introduces RL-of-Thoughts, a reinforcement learning framework that dynamically selects logical blocks to enhance LLM reasoning adaptability.
- It employs a navigator model trained with the Double-Dueling DQN algorithm within an MDP framework to structure reasoning dynamically.
- Experiments show up to 13.4% improvement on benchmarks across STEM, mathematics, and commonsense tasks with strong transferability.
RL of Thoughts: Navigating LLM Reasoning with Inference-time Reinforcement Learning
The paper "RL of Thoughts: Navigating LLM Reasoning with Inference-time Reinforcement Learning" introduces a novel inference-time technique to enhance the reasoning capabilities of LLMs using a reinforcement learning framework. The main contribution is the RL-of-Thoughts (RLoT) method, which employs a navigator model trained with reinforcement learning to dynamically select and sequence logical blocks during the reasoning process. This approach aims to create task-specific logical structures that improve the adaptability and performance of LLMs in complex reasoning tasks.
Problem Statement
Despite the significant progress made by LLMs like GPT, Llama, and others, their token-level autoregressive nature limits their ability to handle complex reasoning tasks, which demand sophisticated logical structures and long-term dependencies. Existing inference-time techniques such as Chain-of-Thought and Tree-of-Thoughts provide lightweight alternatives by introducing predefined logical structures. However, these approaches are task-agnostic and inflexible, applying the same structures across diverse tasks without adaptation.
Methodology
The RLoT framework leverages reinforcement learning to train a navigation model that constructs adaptive logical structures at inference time based on specific problem characteristics.
MDP Framework: The reasoning process is modeled as a Markov Decision Process (MDP), with specially defined state, action, reward, and state transition mechanisms.
- State: Captured through a self-evaluation mechanism, offering a concise summary of problem-solving status based on correctness, complexity, and completeness aspects.
- Action: Inspired by human cognitive strategies, five basic logic blocks (Reason one step, Decompose, Debate, Refine, Terminate) are designed as potential actions for decision-making.
- Reward: Process reward models (PRM) score intermediate results to provide feedback on single-step quality.
Navigator Model Training: The RLoT framework trains the navigator model using the Double-Dueling DQN algorithm. The navigator dynamically selects logic blocks based on the current reasoning state, creating task-specific logical structures for LLMs.
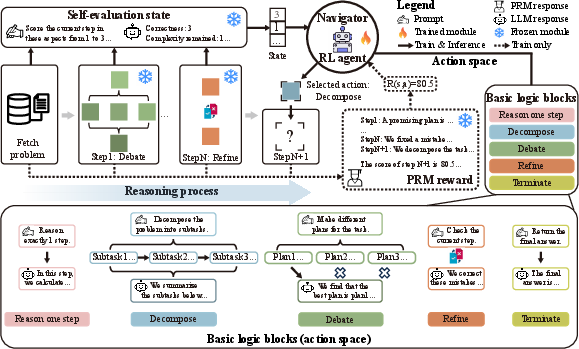
Figure 1: Framework of RL-of-Thoughts (RLoT), enhancing LLMs' ability to handle complex reasoning tasks via dynamic selection and combination of logic blocks.
Experiments
Experiments were conducted across various reasoning benchmarks, including mathematics, STEM, and commonsense tasks, to evaluate the efficacy of RLoT.
Results: RLoT significantly outperforms established inference-time techniques, demonstrating up to 13.4% improvement over baselines. With less than 3K parameters, the RL navigator enhances sub-10B LLMs to perform comparably to much larger models.
Transferability: The navigator model exhibits strong transferability across different LLMs and tasks without fine-tuning, further demonstrating its practical utility.
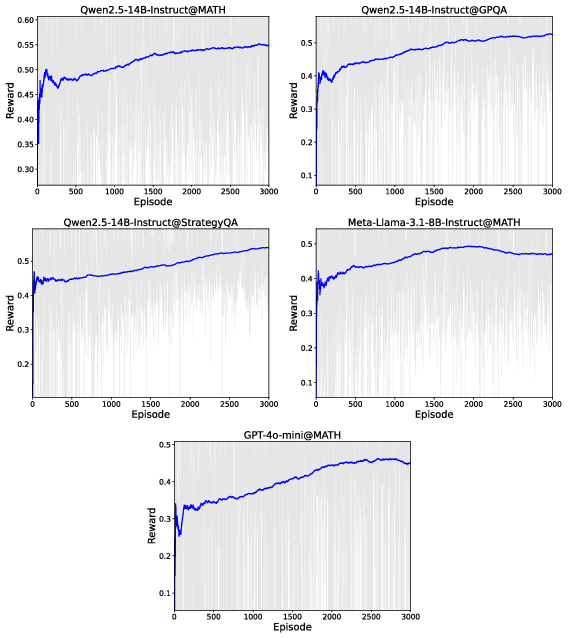
Figure 2: Learning curves during RL training of all navigator models, indicating good convergence of the training process.
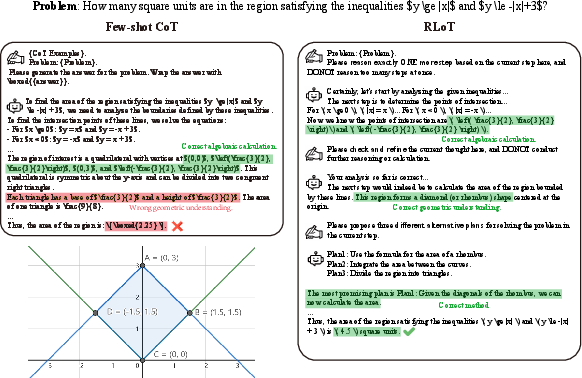
Figure 3: A case study comparing few-shot CoT and RLoT on a representative problem in the MATH dataset, showing the superiority of the RLoT-generated reasoning pathway.
Implications and Future Work
The use of RL in inference-time reasoning presents a promising pathway for enhancing LLM capabilities without the need for costly model parameter updates. The adaptability and efficiency of the RLoT framework make it well-suited for deployment in diverse real-world applications requiring complex reasoning. Future developments could explore extending this approach to broader problem domains and refining logic block designs to further enhance adaptability and effectiveness.
Conclusion
RLoT introduces a significant advancement in the flexible and adaptive enhancement of LLM reasoning capabilities at inference time. By training a lightweight navigator model with reinforcement learning, the framework enables task-specific logical structures that significantly improve LLM performance across diverse problem domains, demonstrating both high efficiency and transferability. The findings highlight the potential of RL in unlocking more adaptive and efficient reasoning processes in AI systems.