- The paper introduces Meta-Reasoner, a framework that dynamically optimizes inference-time reasoning in LLMs using contextual multi-armed bandits.
- It leverages chain-of-thought generation paired with progress reporting to decouple high-level strategy from detailed reasoning steps.
- Experimental results show a 9–12% accuracy improvement and a 28–35% reduction in inference time across various benchmarks.
Introduction
The paper introduces Meta-Reasoner, a framework designed to address computational inefficiencies and error propagation challenges inherent in LLMs during inference-time reasoning. This framework enables LLMs to dynamically optimize their reasoning strategies by effectively managing computational efforts to prioritize promising reasoning paths. By leveraging dual-process theory, Meta-Reasoner decouples high-level strategy generation from the stepwise chain-of-thought (CoT) generation, allowing for adaptive guidance during inference.
Framework and Methodology
Meta-Reasoner's architecture comprises several key components: CoT generation, progress reporting, strategy generation using contextual multi-armed bandits (CMABs), and reward modeling.
- Chain-of-Thought Generation: This initial step involves the LLM generating reasoning steps sequentially to extend its CoT, maintaining coherence by integrating previous reasoning and strategic guidance provided by the Meta-Reasoner.
- Progress Reporting: A compact summarization function distills the CoT into an efficient progress report. This summary aids the Meta-Reasoner in evaluating high-level progress without exploring granular details.
- Strategy Generation: Utilizing CMABs, the Meta-Reasoner dynamically selects strategies that optimize subsequent reasoning steps. This decision-making process involves either fixed or dynamically generated strategies, allowing adaptation based on feedback from prior reasoning efforts.
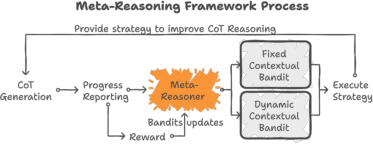
Figure 1: Workflow of Meta-Reasoner. In each round, LLM produces a new reasoning step to extend its CoT reasoning.
Contextual Multi-armed Bandits
The decision-making process for strategy selection in Meta-Reasoner is primarily guided by CMABs. This approach balances exploration and exploitation: trying new strategies to learn while leveraging known effective strategies. The CMAB framework is suitable for dynamically choosing strategies during inference, which aligns with Meta-Reasoner’s goal to optimize reasoning paths efficiently.
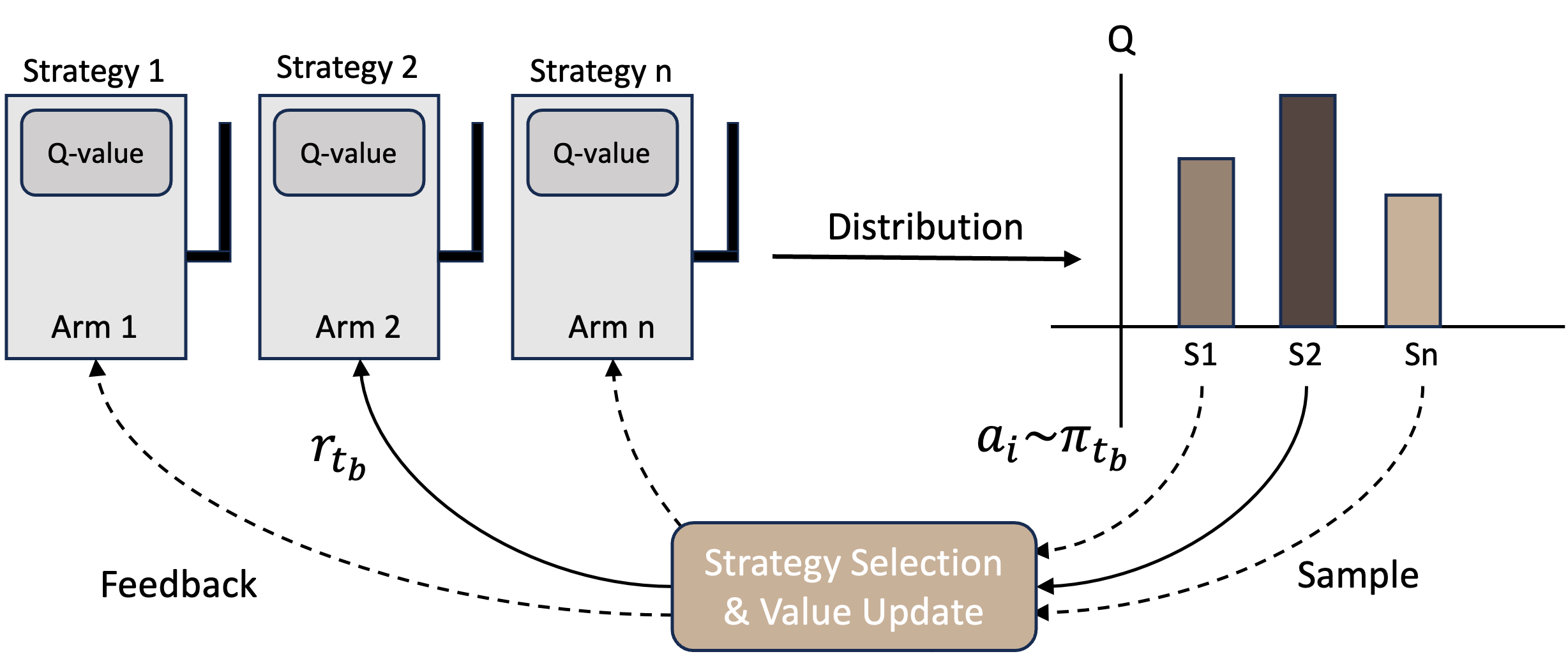
Figure 2: Demonstration: Contextual Multi-armed Bandits.
Experimental Results
Evaluations were conducted on various benchmarks, such as the Game-of-24, TheoremQA, and SciBench, demonstrating performance improvements over state-of-the-art methods. Notably, Meta-Reasoner improved accuracy by 9-12% and reduced inference time by 28-35%.
- Performance Metrics: Meta-Reasoner outperforms traditional methods in accuracy, as evidenced by experiments across different LLMs and reasoning-intensive tasks.
- Inference Efficiency: It exhibits significant reductions in inference time compared to existing methods, highlighting its capability to enhance computational efficiency during reasoning.
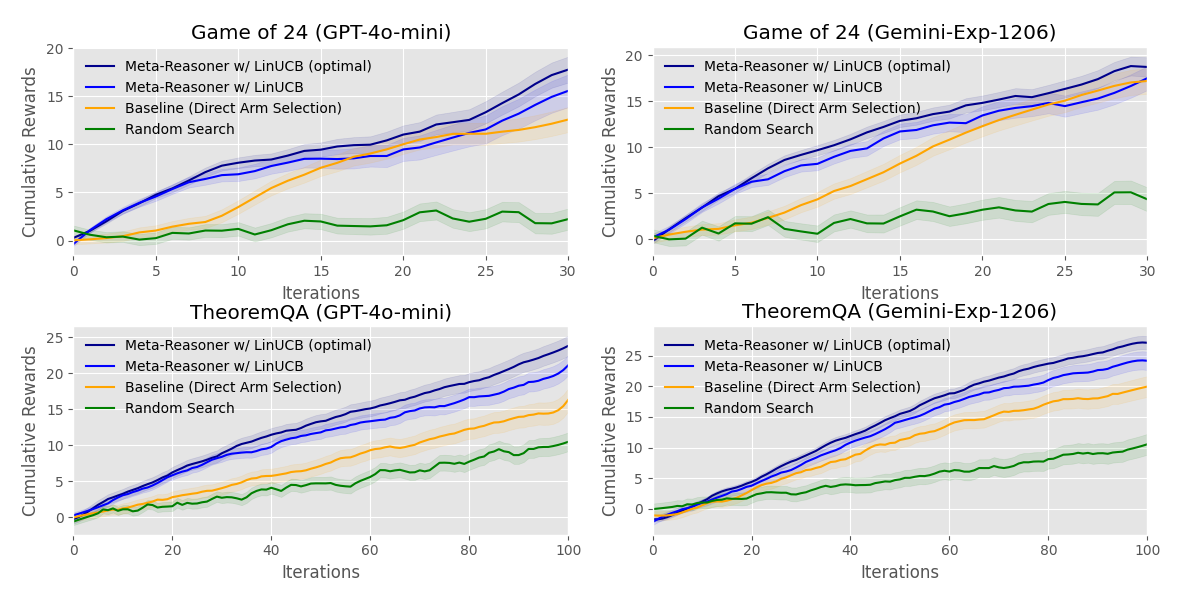
Figure 3: Cumulative reward of different settings across iteration.
Implementation Considerations
- Scalability: Meta-Reasoner's framework is scalable across various domains, such as math, science, and creative writing, without requiring task-specific tuning.
- Computational Requirements: The adaptive strategy generation mechanism efficiently manages computational resources, prioritizing promising reasoning paths to mitigate wasted efforts on less effective strategies.
Conclusion
Meta-Reasoner presents a novel approach to optimized inference-time reasoning in LLMs, offering improved accuracy and efficiency by dynamically guiding the reasoning process through strategic interventions. This framework has the potential to extend to diverse domains, demonstrating scalability and adaptability while addressing key reasoning challenges in LLMs. Future developments may explore integrating more complex strategy-generation mechanisms and further refining reward structures to enhance the framework's efficacy.