- The paper presents a novel supervised framework that integrates phonetic classification and CTC tasks to improve both phonetic representation and signal reconstruction.
- It employs a unique architecture with an encoder, quantizer using Residual Vector Quantization, and decoder, enhanced by a transformer and auxiliary heads.
- Experimental results demonstrate that PAST outperforms state-of-the-art models with a PNMI of 0.75 and SISNR of 4.84 while reducing computational overhead.
PAST: Phonetic-Acoustic Speech Tokenizer
Introduction
The paper presents PAST, a Phonetic-Acoustic Speech Tokenizer, which offers an innovative framework for joint modeling of phonetic information with signal reconstruction. Unlike traditional approaches relying on pretrained self-supervised learning (SSL) models, PAST employs supervised phonetic data, thus integrating domain knowledge directly into the tokenization process via auxiliary tasks. This approach not only enhances phonetic representation but also facilitates real-time applications through its causal variant, demonstrating superior performance across several standard evaluation metrics.
Method and Architecture
PAST introduces a novel architecture comprising three main components: Encoder, Quantizer, and Decoder. The encoder leverages a convolutional module followed by a transformer encoder, while the quantizer employs Residual Vector Quantization (RVQ) to generate discrete tokens. The model's design is shown in Figure 1, where auxiliary heads process the output of the first vector quantization module.
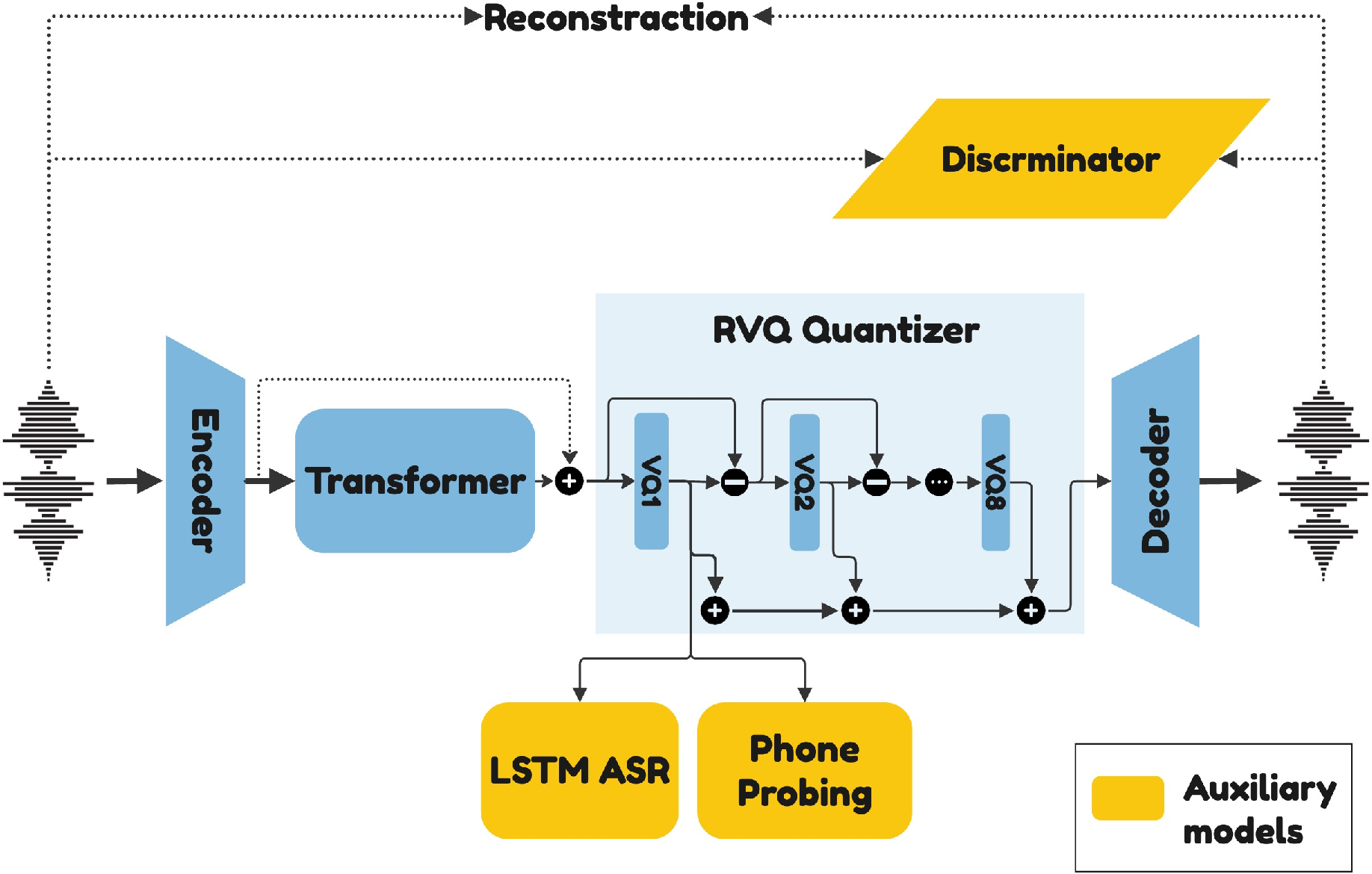
Figure 1: Schematic of the PAST pipeline. The auxiliary heads use the output of the first vector quantization module as input.
PAST employs auxiliary tasks for phonetic classification and connectionist temporal classification (CTC) for character alignment, enhancing its ability to capture phonetic content directly. These tasks replace distillation from SSL models, further simplifying the architecture and reducing computational overhead.
Experimental Evaluation
The efficacy of PAST is demonstrated through comprehensive experiments comparing it with state-of-the-art tokenizers such as SpeechTokenizer and X-Codec. PAST outperforms these baselines across phonetic and acoustic metrics as seen in Table 1 and Table 2. Notably, PAST achieves a Phonetic Normalized Mutual Information (PNMI) score of 0.75 and superior signal reconstruction quality, with a Scale-Invariant Signal-to-Noise Ratio (SISNR) of 4.84.
Table 1 highlights PAST's performance on phonetic metrics, while Table 2 discusses signal reconstruction quality. The results indicate that PAST achieves notable improvements, especially in phonetic information capture without compromising signal quality.
Speech Language Modeling
Further validation is provided by evaluating PAST's performance in Speech Language Modeling (SLM). By leveraging a common backbone using AudioGen’s architecture, PAST shows improved sWUGGY scores, indicating better phonetic information preservation and interpretation during speech modeling.
Component Ablation and Analysis
An ablation study underscores the significance of different components within PAST. The auxiliary losses, particularly, play a critical role in encapsulating phonetic information within the latent space. Additionally, the transformer module, in conjunction with a strategic skip connection sampling, enhances sequence modeling and training stability.
Conclusion
PAST showcases a significant advancement in speech tokenization by optimizing phonetic and acoustic representations through supervised learning. Without the dependency on SSL models, PAST simplifies the tokenization architecture and sets a new benchmark in tokenization efficacy. Future enhancements may focus on extending PAST for use in multilingual settings, broadening its applicability.
By presenting PAST, this paper contributes a robust framework that enhances the integration of phonetic information within tokenization processes, providing a pathway for more accurate and efficient speech LLM applications.

