- The paper introduces a novel single-stage diffusion-based fMRI decoding framework that preserves temporal information for improved image reconstruction.
- It leverages subject-specific linear projections and per-timestep parameterization to convert continuous BOLD signals into effective conditioning for latent diffusion models.
- Quantitative experiments demonstrate superior performance on metrics like SSIM, CLIP, and AlexNet, underscoring its potential for dynamic brain decoding and cross-subject generalization.
Dynadiff: Single-stage Decoding of Images from Continuously Evolving fMRI
Context and Motivation
Decoding images from fMRI has advanced rapidly due to increases in data scale and the adoption of diffusion models for image synthesis. However, prominent methods typically employ multi-stage pipelines with time-collapsed preprocessing, which discards dynamic information intrinsic to BOLD fMRI. Moreover, existing approaches often rely on extensive ad-hoc feature engineering, multi-stage fine-tuning, and require averaging across multiple repetitions of stimuli, restricting generalizability and temporal resolution.
Single-stage Diffusion-based Decoding Pipeline
The Dynadiff framework proposes an end-to-end, single-stage training pipeline that directly decodes images from continuous, time-resolved BOLD fMRI data. Unlike prevailing methods, Dynadiff handles the full time series of fMRI, thereby preserving temporal information. The pipeline consists of a brain module and a diffusion-based image generation module:
- The brain module projects fMRI time series from a subject-specific voxel space to the conditional embedding space of a latent diffusion image generation model via a sequence of linear projections, normalization, and temporal aggregation. Key to this is (1) a subject-specific linear projection, (2) per-timestep parameterization (non-shared weights across time), and (3) late temporal aggregation.
- The image generation module is adapted from pretrained latent diffusion models, interfaced via cross-attention layers using brain-derived embeddings as conditioning signals (with null text prompts).
This architecture enables joint training—diffusion model weights remain frozen except for LoRA adapters inserted into its cross-attention layers.
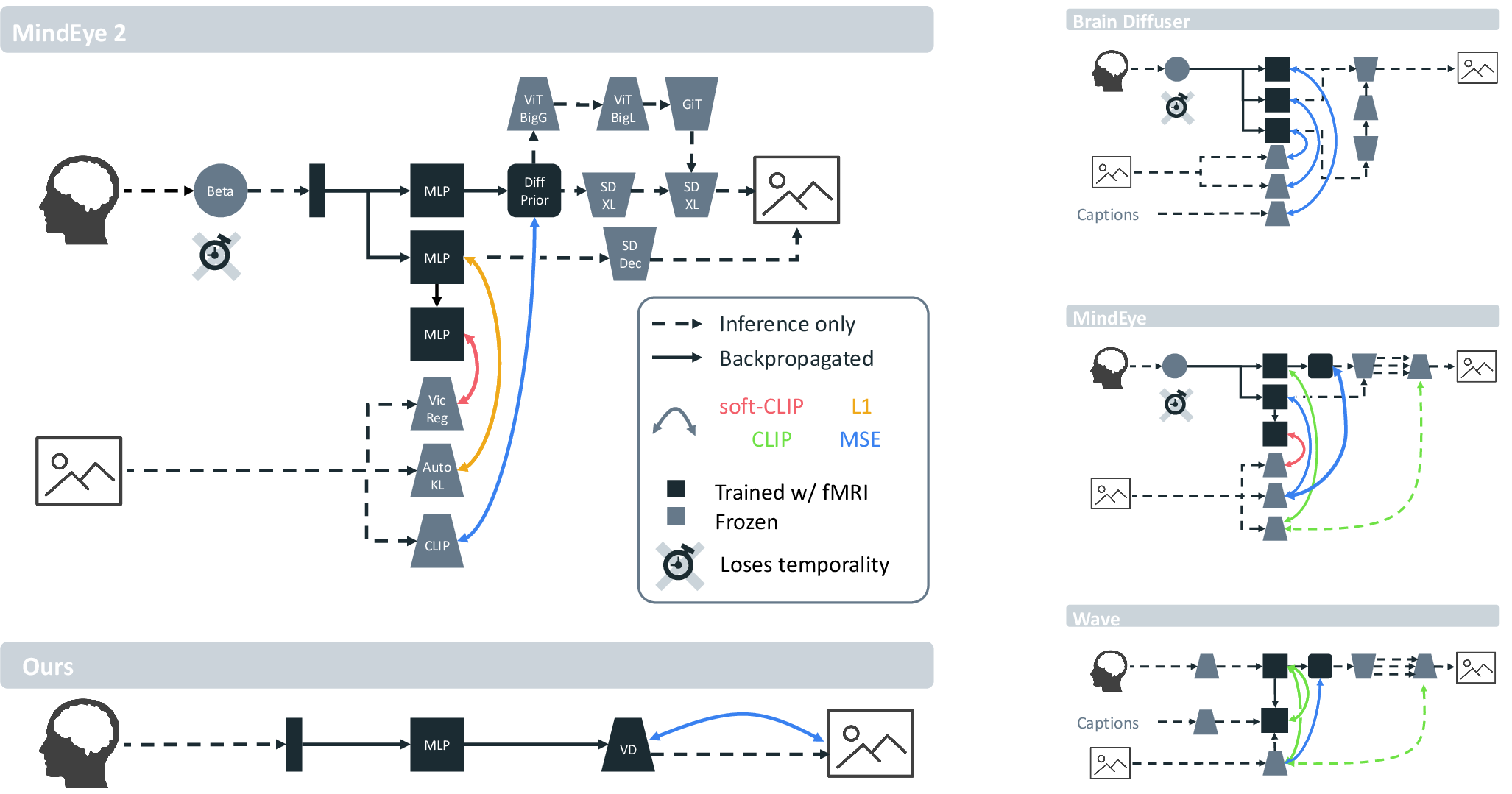
Figure 1: Schematic bird's-eye view of four foundational fMRI-to-image pipelines. Dynadiff enables single-stage end-to-end training and time-resolved conditioning, in contrast to prior multi-stage approaches.
Experimental Protocol
Experiments are conducted using the Natural Scenes Dataset (NSD): ultra-high-field (7T) fMRI from subjects exposed to 10,000 unique images, each shown three times. No repetition averaging is performed; models are evaluated on single-trial time series, leveraging BOLD signals restricted to a posterior cortex ROI. Each trial's fMRI sequence is preprocessed with slice-timing correction, motion and distortion correction, spatial resampling, detrending, and z-scoring—intentionally avoiding high-pass filtering and other potential information-distorting steps.
Quantitative and Qualitative Results
Dynadiff consistently outperforms state-of-the-art baselines—both classical (Brain-Diffuser) and modern multi-stage methods (MindEye1/2, WAVE), with marked improvement in both low-level (SSIM, AlexNet) and high-level (CLIP, DreamSim, mIoU) metrics. For example, Dynadiff achieves up to 98.20 on AlexNet(5), 93.53 on CLIP-12, and 8.50 on mIoU, all surpassing MindEye2 by nontrivial margins.
Qualitative reconstructions also show improved compositional alignment and object localization compared to alternatives, supporting metric superiority.
Temporal Generalization and Time-resolved Decoding
A critical finding is that Dynadiff enables true time-resolved decoding. The model generalizes to windows shifted in time relative to stimulus onset. Decoder performance peaks for windows beginning ~3s post-stimulus—a finding aligned with canonical HRF latency profiles. However, superior results are obtainable at each time point by training specialized decoders per window, revealing that image-representative neural codes evolve rapidly, with distinguishable patterns supporting accurate reconstructions at multiple temporally offset positions.
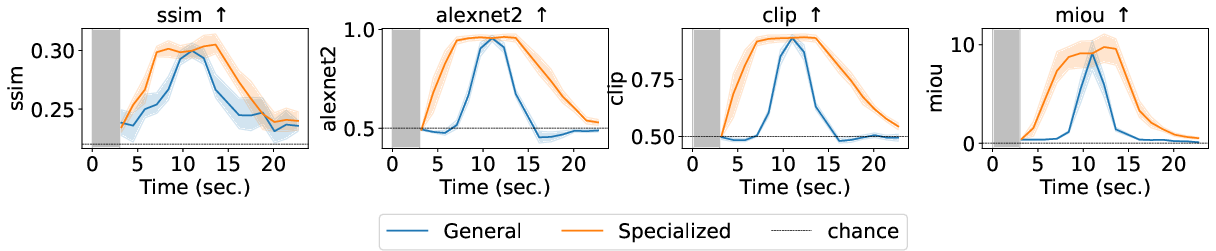
Figure 3: Image reconstruction metrics (e.g., SSIM, CLIP, AlexNet) as a function of fMRI time window, contrasting generalist and specialist decoders. Gray area denotes the image presentation interval.
Impact of Observation Window and Model Design
An ablation varying the decoding window's duration demonstrates that maximal decoding fidelity saturates between 3.9s and 7.8s, but does not improve with longer intervals, highlighting precision in the temporal mapping between fMRI and perceptual encoding.
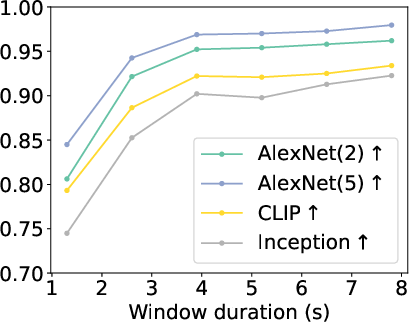
Figure 5: Evolution of AlexNet, CLIP, and Inception metrics vs. window duration. Metrics plateau at moderate time windows, emphasizing importance of aligning window length with HRF dynamics.
Ablations further show that the presence of dedicated time-step layers and late temporal aggregation in the brain module are essential for optimal performance. The architecture's simplicity—eschewing separate alignment, candidate selection, or staged semantic refinement—has direct advantages for interpretability, reproducibility, and training efficiency.
Cross-subject Generalization
Dynadiff incorporates a parameter-efficient strategy for cross-subject training: only the initial subject- and time-specific projections are individualized, with the larger brain module shared among subjects. Pretraining on multiple subjects and fine-tuning on small amounts of target subject data provides measurable performance benefits, partially mitigating the per-subject data requirement and aligning with aspirations towards subject-agnostic brain decoding.
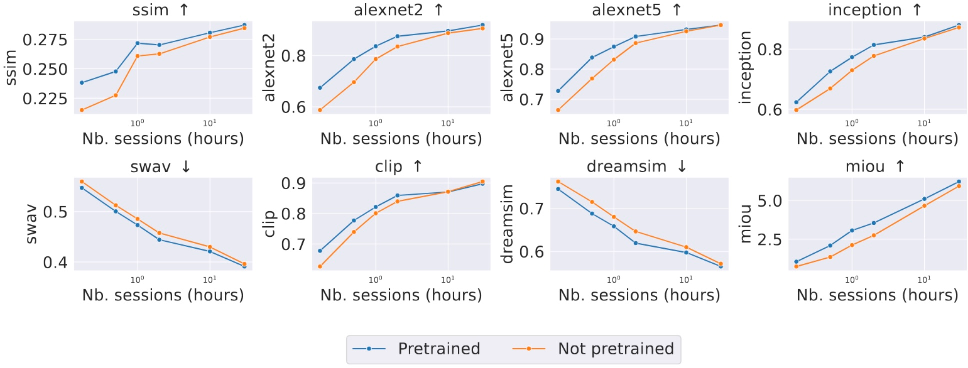
Figure 2: Cross-subject decoding accuracy (e.g., CLIP, SSIM) versus number of subject-specific data samples. Pretraining provides a clear sample efficiency improvement.
Theoretical and Practical Implications
The paper empirically demonstrates that the temporal dimension in fMRI signals carries non-redundant, dynamically evolving representations supporting perceptual decoding. The data-driven discovery that temporal generalization of decoders is limited and that specialized models are required to accurately capture evolving perceptual codes aligns with theories of dynamic coding in neural circuits, now extended to the fMRI regime.
Dynadiff's reduction of pipeline complexity stresses the feasibility of single-stage training for neural decoding and sets a strong baseline for temporally resolved image (and potentially video) reconstructions. This strongly suggests that subsequent work should embrace the continuous and high-dimensional BOLD time series, rather than rely on simplistic GLM-based time-collapsed representations.
Practically, the results refine the limits of decoding fidelity from non-averaged, single-trial fMRI and inform future designs of brain–computer interfaces, especially in the domain of perceptual prostheses and neuroethics.
Limitations and Future Developments
The approach is limited by its reliance on large, highly repeated, and potentially biased datasets such as NSD, as well as ongoing subject-specificity in training. The pipeline presumes access to standardized preprocessing, which, if streamlined via foundation models, could further relax these requirements. Importantly, generalization to unseen non-training subjects and to less stereotypical visual distributions remains an open problem.
Future work should target:
- Generalization to unseen subjects via subject-invariant encoding,
- Extension of the approach to temporally continuous visual input (video) and other task domains (e.g., speech, language),
- Exploration of transfer learning across imaging modalities and tasks,
- Further reduction of data and subject specificity requirements, possibly leveraging contrastive or self-supervised learning in the neuroimaging space.
Conclusion
Dynadiff advances the state of fMRI-to-image decoding by integrating a single-stage, end-to-end pipeline capable of decoding from dynamic, non-collapsed BOLD signals. It achieves superior empirical performance, facilitates fine-grained temporal characterization of perceptual neural codes, and reduces reliance on elaborate, multi-stage pipelines—thereby reshaping both methodological and theoretical approaches to neural decoding from fMRI data (2505.14556).