- The paper’s main contribution is the BAGEL architecture that enables unified multimodal pretraining for both understanding and generation tasks.
- It leverages a Mixture-of-Transformer-Experts design with vast interleaved data to enhance performance across text, image, and video benchmarks.
- The study reveals emerging phase transitions in model capabilities, emphasizing the advantages of large-scale multimodal data integration.
Emerging Properties in Unified Multimodal Pretraining
Introduction
The paper "Emerging Properties in Unified Multimodal Pretraining" presents BAGEL, an open-source unified multimodal model designed to integrate both understanding and generation capabilities across various modalities—text, image, and video. The authors assert that by pretraining BAGEL with vast and diverse multimodal interleaved data, it exhibits emerging abilities in complex multimodal reasoning and surpasses current open-source models in benchmark evaluations.
BAGEL leverages a Mixture-of-Transformer-Experts (MoT) architecture to facilitate separate but concurrent processing of multimodal understanding and generation. This architecture choice aims to overcome the bottlenecks seen in previous models by harmonizing data across modalities without task-specific constraints.

Figure 1: Showcase of the versatile abilities of the BAGEL model.
Model Architecture
BAGEL's architecture employs two distinct encoders and transformer experts tailored for different functionalities: one for semantic content understanding and another for generation tasks. Each component uses a shared multi-modal self-attention mechanism to handle a unified sequence of tokens, ensuring coherent multimodal integration. This design is adept at scaling with massive datasets, supporting long-context multimodal tasks such as image manipulation and video frame prediction.
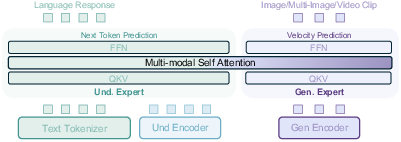
Figure 2: Architecture overview with distinct encoders and shared multi-modal self attention in each Transformer block.
Data Management
A novel aspect of BAGEL's training is its approach to data curation and integration. The model is trained on trillions of tokens sourced from interleaved data sets comprising text, images, and videos. This expansive dataset is meticulously filtered and structured to enhance the model's reasoning underpinnings, especially in relation to temporal and spatial data extracted from video sequences.
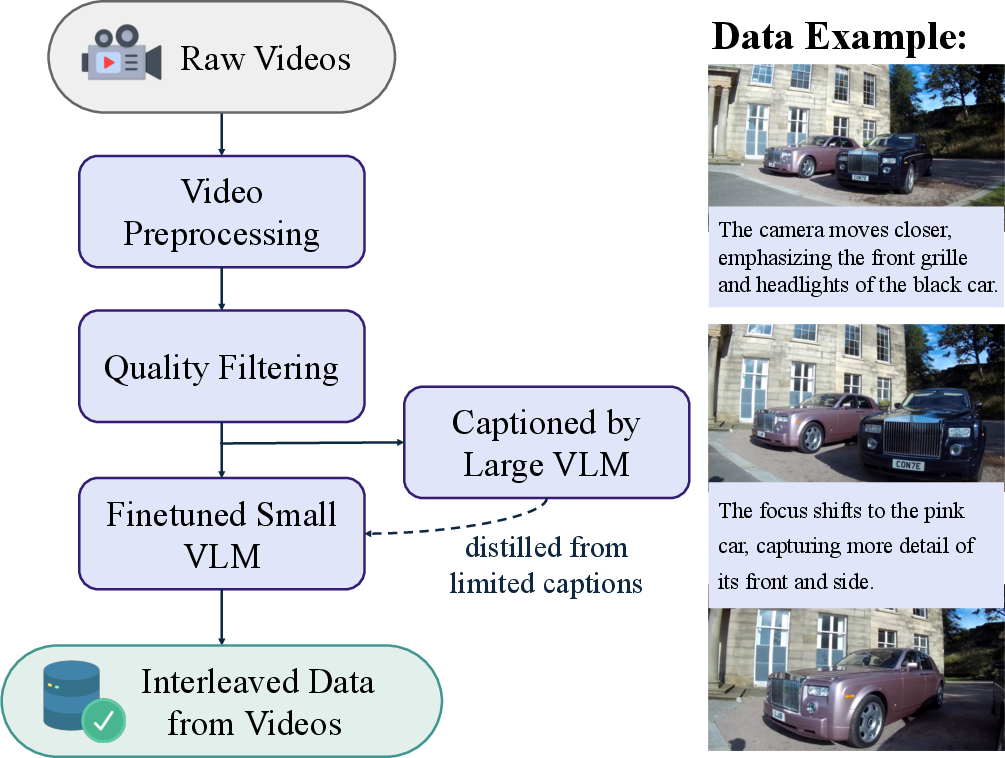
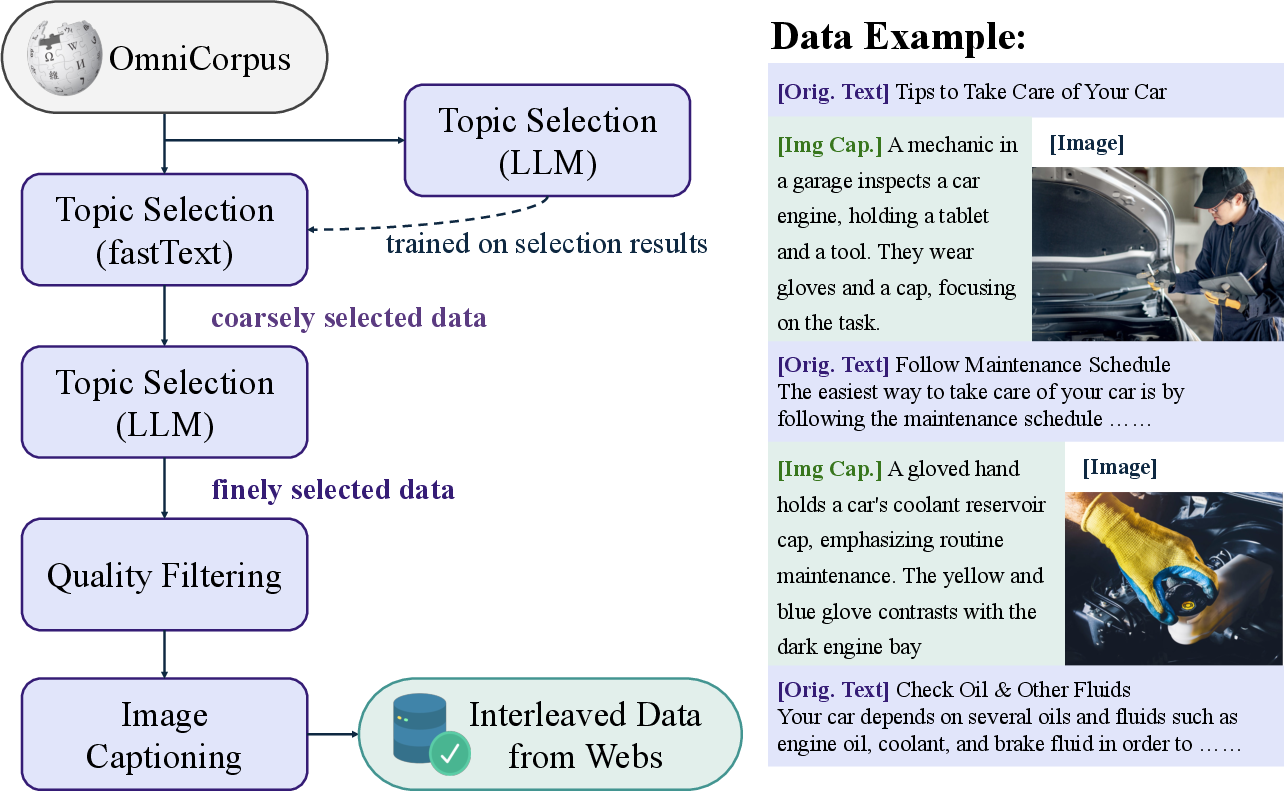
Figure 3: Data pipeline for interleaved data from videos.
The data allocation is scientific, optimizing the ratio of generation to understanding examples, as detailed in controlled ablation studies. These procedures show that BAGEL significantly boosts data synthesis and provides new insights into sampling strategies for future model training.
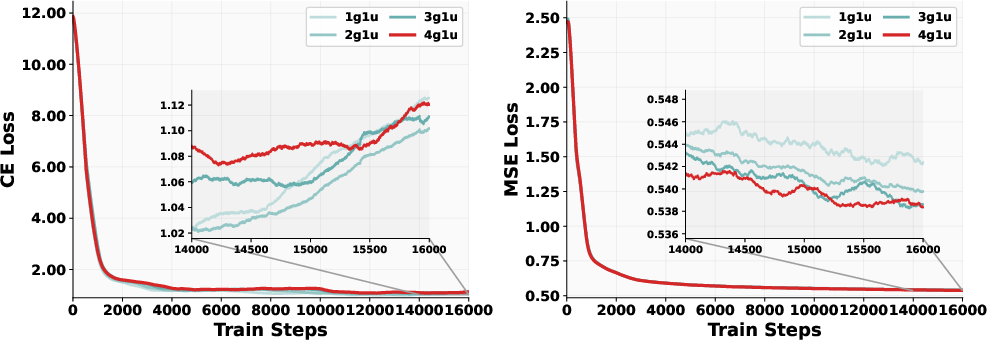
Figure 4: Loss curves of different data ratios.
Training Protocol
BAGEL was trained using a staged strategy involving an Alignment, Pre-training, Continued Training, and Supervised Fine-tuning stage. Each stage incrementally adjusted data input attributes and learning objectives to refine both foundational capabilities and advanced multimodal reasoning. Empirical adjustments in these stages helped achieve a balance between learning rate stability and multimodal task efficacy.
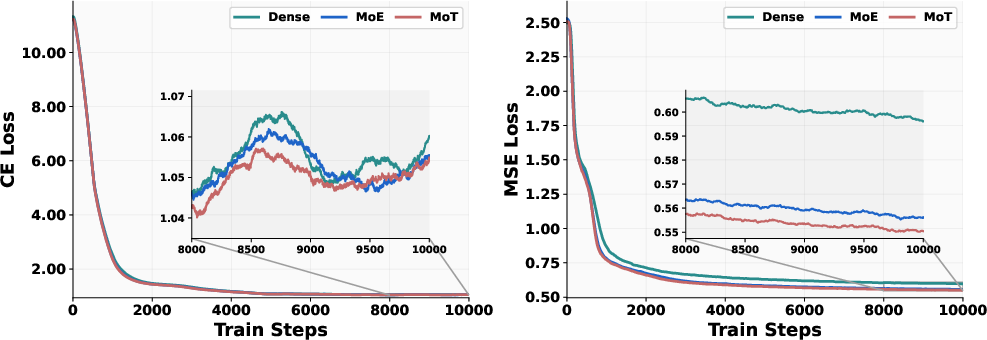
Figure 5: Loss curves of various designs.
Evaluation
In evaluations, BAGEL outperformed several open-source models across benchmarks for both text-to-image generation and image understanding. The results show BAGEL's superior capability to manage complex tasks requiring in-depth semantic and world-knowledge integration.
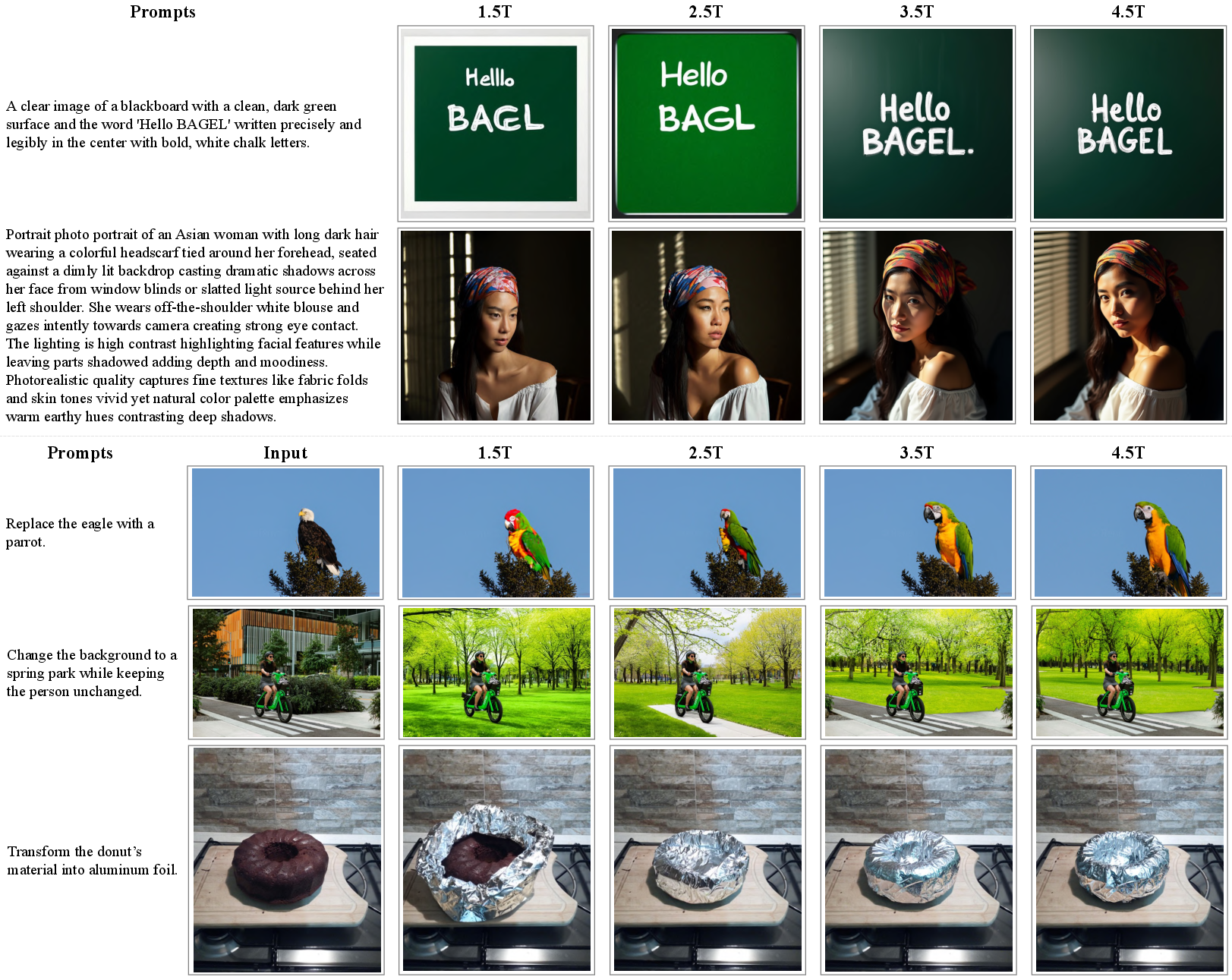
Figure 6: Comparison of models with different amounts of training tokens.
Emerging Abilities
Beyond traditional benchmarks, BAGEL demonstrates a spectrum of emerging functionalities as the model scales. This includes enhanced capabilities for free-form image manipulation and intelligent image editing, as observationally validated in the newly proposed IntelligentBench evaluation.

Figure 7: Comparison on IntelligentBench.
The scaling of training tokens highlights a phase transition in capabilities, reinforcing the importance of integrated learning across modalities. These insights underscore that increasing the scale in multimodal settings generates synergy and emergent properties not captured by traditional model assessments.
Conclusion
BAGEL's contributions are two-fold: a novel multimodal architecture facilitating extensive scalability and the demonstration of emerging properties through strategic data integration and model design. These advancements collectively set a framework for future endeavors in the field of unified multimodal AI models. The implications of BAGEL’s performance suggest an untapped potential in leveraging large-scale interleaved pretraining to unlock sophisticated multimodal reasoning abilities.