- The paper presents PhyX, a benchmark designed to test MLLMs’ ability to integrate domain knowledge with physical reasoning.
- It utilizes 3K curated questions across 25 sub-domains and 6 physics areas to evaluate both visual and textual reasoning.
- Performance insights reveal significant gaps between current models and human experts, underlining the need for enhanced multimodal integration.
PhyX: Does Your Model Have the "Wits" for Physical Reasoning?
Introduction to Physical Reasoning in Multimodal LLMs (MLLMs)
The "PhyX: Does Your Model Have the 'Wits' for Physical Reasoning?" paper introduces PhyX, a benchmark designed to assess the physical reasoning capabilities of foundation models, specifically Multimodal LLMs (MLLMs). Despite advances in natural language processing and multimodal models, the ability of these models to integrate domain knowledge and symbolic reasoning with real-world physical constraints remains an area requiring further exploration.
Multimodal reasoning extends the challenges faced by models beyond mere mathematical deduction, adding layers of complexity by incorporating realistic physical scenarios. This requires models to decode implicit conditions, maintain consistency across reasoning chains, and ground abstract physical formulas into tangible visual contexts. The paper posits that the ability to reason about physical processes is crucial for developing AI systems capable of understanding and interacting with the world in meaningful ways.
The necessity for robust evaluation of such capabilities led to the design and implementation of the PhyX benchmark, which comprises 3K meticulously curated questions across 25 sub-domains and six core physics areas: mechanics, electromagnetism, thermodynamics, wave/acoustics, optics, and modern physics.
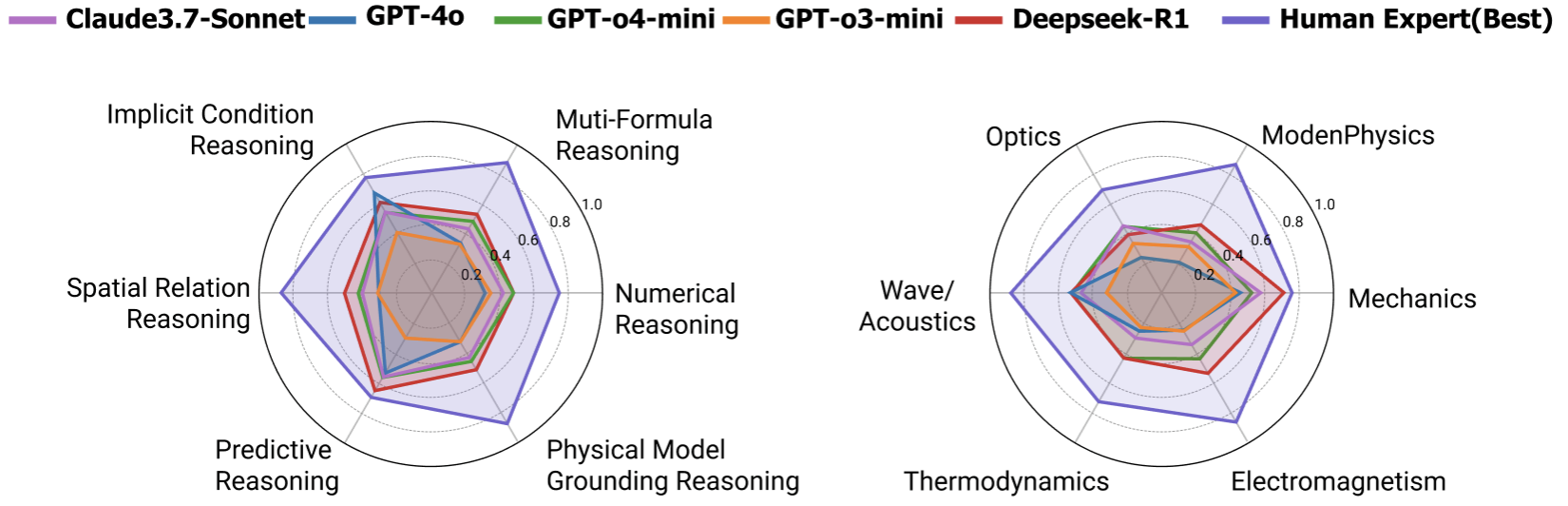
Figure 1: Accuracies of three leading MLLMs, two leading LLM, and human performance on our proposed PhyX across 6 physical reasoning types and 6 domains.
Benchmark Composition and Dataset Quality
The PhyX dataset includes both multiple-choice and open-ended questions, presenting realistic scenarios grounded in physics. Each entry within the dataset is shaped to test various reasoning types, including physical model grounding reasoning, spatial relation reasoning, multi-formula reasoning, implicit condition reasoning, numerical reasoning, and predictive reasoning.
The dataset is validated rigorously, with scenarios assessed by physics Ph.D. students to ensure accuracy and eliminate biases. The intention is to create a benchmark that pushes MLLMs beyond mere memorization and surface-level pattern recognition. Instead, PhyX targets the requirement for models to understand and apply physical laws in a manner akin to human reasoning.
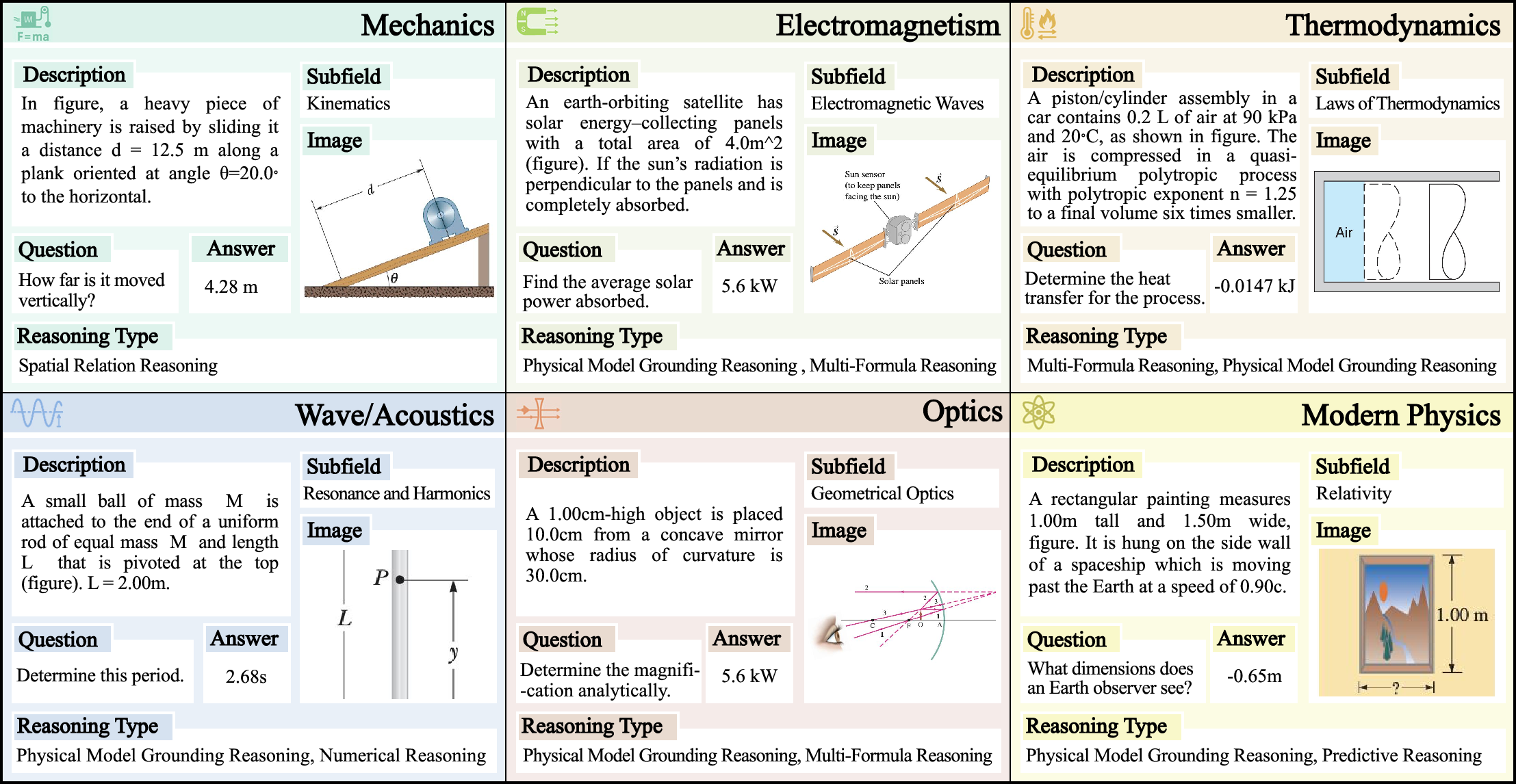
Figure 2: Sampled PhyX examples from each domain.
The evaluation results indicate a pronounced capability gap between models and human experts. Human performance in physics reasoning showcases a stark contrast to the best-performing MLLM models such as GPT-o4-mini, Claude3.7-Sonnet, and others, with substantial performance disparities persisting across all domains. Notably, areas encompassing Modern Physics and Wave/Acoustics highlight these gaps most prominently.
Despite their potential, MLLMs demonstrate deficiencies in extracting and leveraging visual context effectively, often reverting to text-based reasoning even in multimodal settings. This reliance exposes limitations in models' capability to fully integrate visual signals for comprehensive physical reasoning tasks.
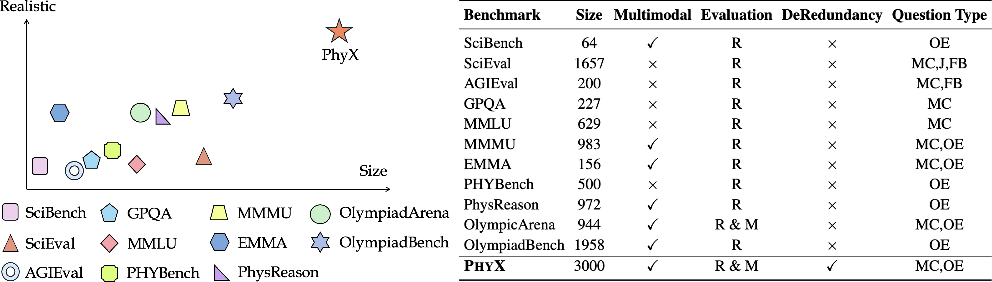
Figure 3: Comparison with existing physics benchmarks. Realistic refers to the extent to which the dataset contains visually realistic physical scenarios. Size indicates the number of physics questions with images in multimodal benchmarks or total physics questions in text-only benchmarks.
Critical Observations and Error Analysis
An error analysis reveals several key shortcomings:
- Visual Reasoning Errors: These errors stem from misinterpretation or incorrect reasoning based on visual data.
- Text Reasoning Errors: Highlighted by models incorrectly processing or interpreting textual information.
- Knowledge Gaps: Reflective of incomplete domain knowledge, impacting models' understanding of specific physics concepts.
- Calculation Mistakes: Errors in arithmetic operations and formula applications.
Each error category suggests avenues for enhancing model design and training approaches, particularly focusing on improving integration between visual and textual modalities in reasoning processes.
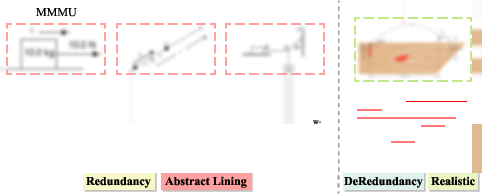
Figure 4: Existing benchmarks that contain physics-related questions suffer from information redundancy and abstract representation. In contrast, de-redundancy in PhyX benchmark increases the difficulty, as models can perceive concepts from ONE modality only.
Conclusion and Future Developments
The PhyX benchmark provides a comprehensive toolkit for evaluating the physical reasoning capabilities of advanced AI models and highlights crucial areas needing improvement. The substantial gap in physical reasoning performance underscores the ongoing need to develop models capable of combining abstract concepts with real-world knowledge comprehensively. Future work should expand upon multimodal reasoning frameworks, aiming to close the gap between machine and human understanding of complex physical phenomena.
The challenge remains to ensure models can effectively leverage diverse input modalities to produce reliable, physics-grounded reasoning—demonstrating true 'wits' for physical reasoning. The implications for AI systems are vast, ultimately contributing to more intelligent, versatile tools capable of robust interactions within dynamic physical environments.

