- The paper introduces Flowsep, a novel method that leverages flow matching techniques for precise single-channel audio source separation.
- The method innovatively augments mixture samples with artificial noise while using a permutation equivariant network to ensure mixture consistency.
- Experimental results show improved SI-SDR, ESTOI, and DNSMOS scores, indicating robust performance and enhanced signal intelligibility.
Source Separation by Flow Matching
Source separation in signal processing refers to the task of recovering individual signals from a mixture. This paper introduces an innovative methodology called "Flowsep," which employs flow matching techniques for single-channel audio source separation, ensuring strict mixture consistency. This approach marks a departure from regression-based models, leveraging advanced generative modeling techniques in the process.
Flow Matching Approach
Flow matching is a sophisticated methodology that utilizes samples from two probability distributions over the same space, converting one sample distribution to another using an ordinary differential equation (ODE). In this paper, flow matching harnesses this technique by augmenting mixture samples with artificial noise components. This augmentation aligns the dimensionality with that of the multiple source distribution, facilitating accurate reconstruction of individual sources from mixtures.
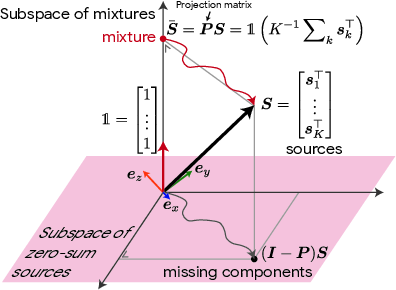
Figure 1: Illustration of the geometry of sources. The mixture lives in the uni-dimensional subspace spanned by vone=[1,…,1]⊤ while the missing components reside in zero-sum signals.
Permutation Equivariant Network
A key innovation in this paper is the use of a permutation equivariant network architecture. This architecture addresses the permutation invariance inherent in source separation problems (since any permutation of sources results in the same mixture). The network uses a multi-head self-attention module with specialized positioning for mixture signals, embedded within a Mel-band split architecture. This setup ensures that the network retains equivariance properties essential for accurate separation while leveraging powerful modeling components like convolutional layers and complex embeddings.
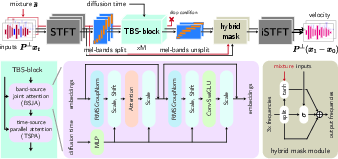
Figure 2: The overall architecture of the network, showcasing permutation equivariant structures.
Experimental Validation
The paper implements Flowsep in various audio source separation tasks involving overlapping speech signals. It compares Flowsep with popular models like Conv-TasNet and MB-Locoformer, demonstrating superior performance across metrics like SI-SDR, ESTOI, and DNSMOS. Flowsep not only offers robustness against noise but also improves intelligibility and quality of the separated signals, emphasizing the efficacy of flow matching combined with permutation equivariance in practical applications.
Conclusion
Flowsep introduces a novel paradigm for source separation, combining flow matching with permutation equivariant architectures. This approach not only ensures mixture consistency but provides robust handling of the permutation ambiguity without relying on regression-based techniques. The promising results obtained from rigorous experimentation indicate potential advances in audio processing domains, paving the way for further exploration in generative models for signal separation. Future work might involve extending these methods to handle noisy environments and investigate their applicability beyond speech processing.