Abstract: Differential Transformer has recently gained significant attention for its impressive empirical performance, often attributed to its ability to perform noise canceled attention. However, precisely how differential attention achieves its empirical benefits remains poorly understood. Moreover, Differential Transformer architecture demands large-scale training from scratch, hindering utilization of open pretrained weights. In this work, we conduct an in-depth investigation of Differential Transformer, uncovering three key factors behind its success: (1) enhanced expressivity via negative attention, (2) reduced redundancy among attention heads, and (3) improved learning dynamics. Based on these findings, we propose DEX, a novel method to efficiently integrate the advantages of differential attention into pretrained LLMs. By reusing the softmax attention scores and adding a lightweight differential operation on the output value matrix, DEX effectively incorporates the key advantages of differential attention while remaining lightweight in both training and inference. Evaluations confirm that DEX substantially improves the pretrained LLMs across diverse benchmarks, achieving significant performance gains with minimal adaptation data (< 0.01%).
The paper introduces a differential attention mechanism that reduces noise in self-attentions and improves model expressivity.
It demonstrates reduced head redundancy by diversifying attention scores, supported by pairwise cosine distance metrics.
Dex efficiently integrates Diff’s benefits into pretrained models using a learnable adaptation parameter, enhancing performance without extensive retraining.
Differential Transformer (Diff) has been devised to address significant performance challenges in transformer architectures, particularly the noise in self-attention mechanisms. The research elaborates on how Diff achieves its benefits in expressivity, head redundancy reduction, and learning dynamics. This paper introduces a novel framework called Differential Extension (Dex), which integrates Diff's benefits into pretrained LLMs without necessitating extensive retraining.
Mechanisms Behind Differential Transformer
Diff Transformer introduces a differential attention mechanism that amplifies token relevancy by comparing two sets of attention scores, thus mitigating common noise. This differential process enhances performance not by traditional sparsity (having many attention scores near zero) but by facilitating intricate attention distributions, including negative scores.
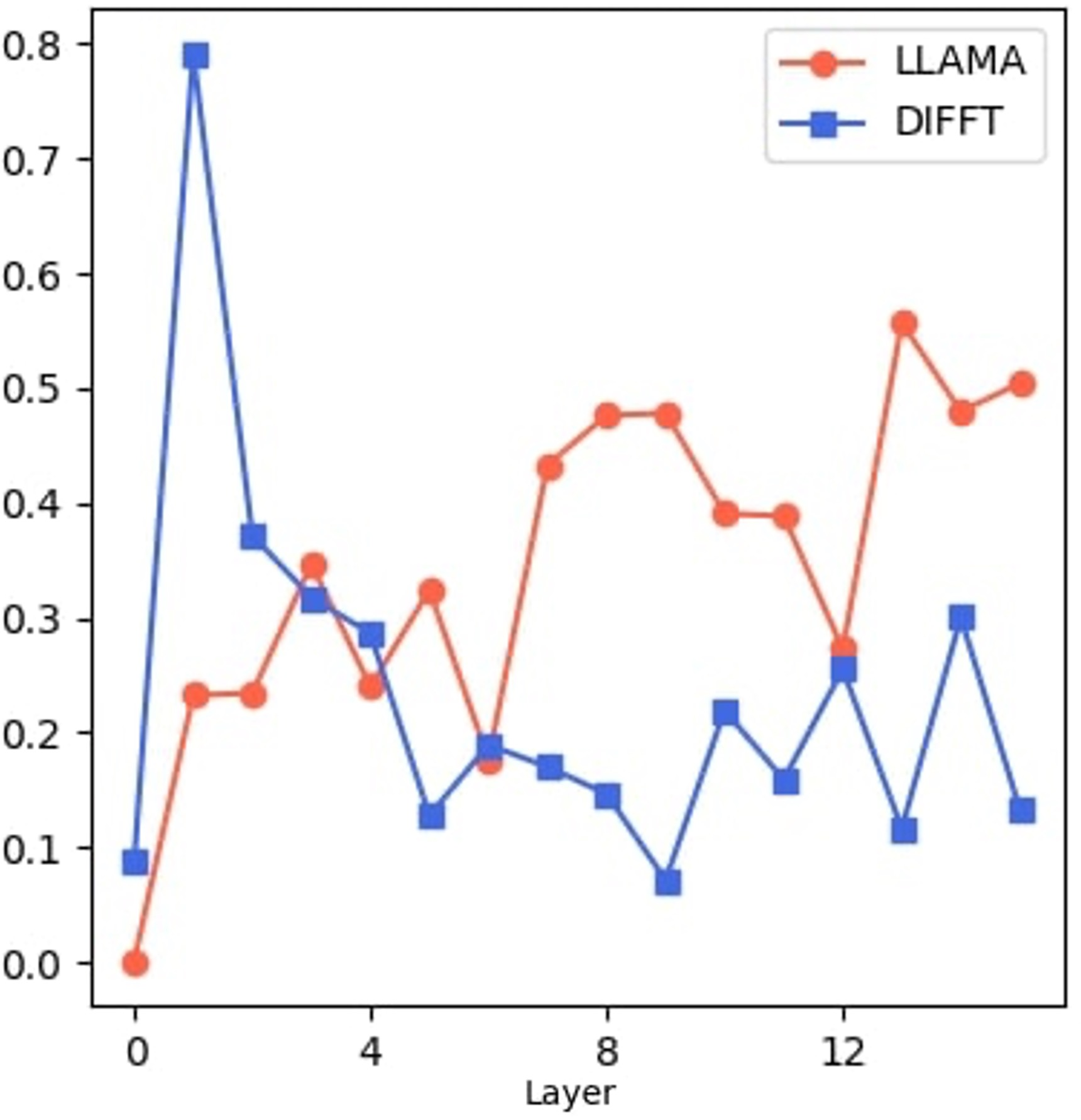
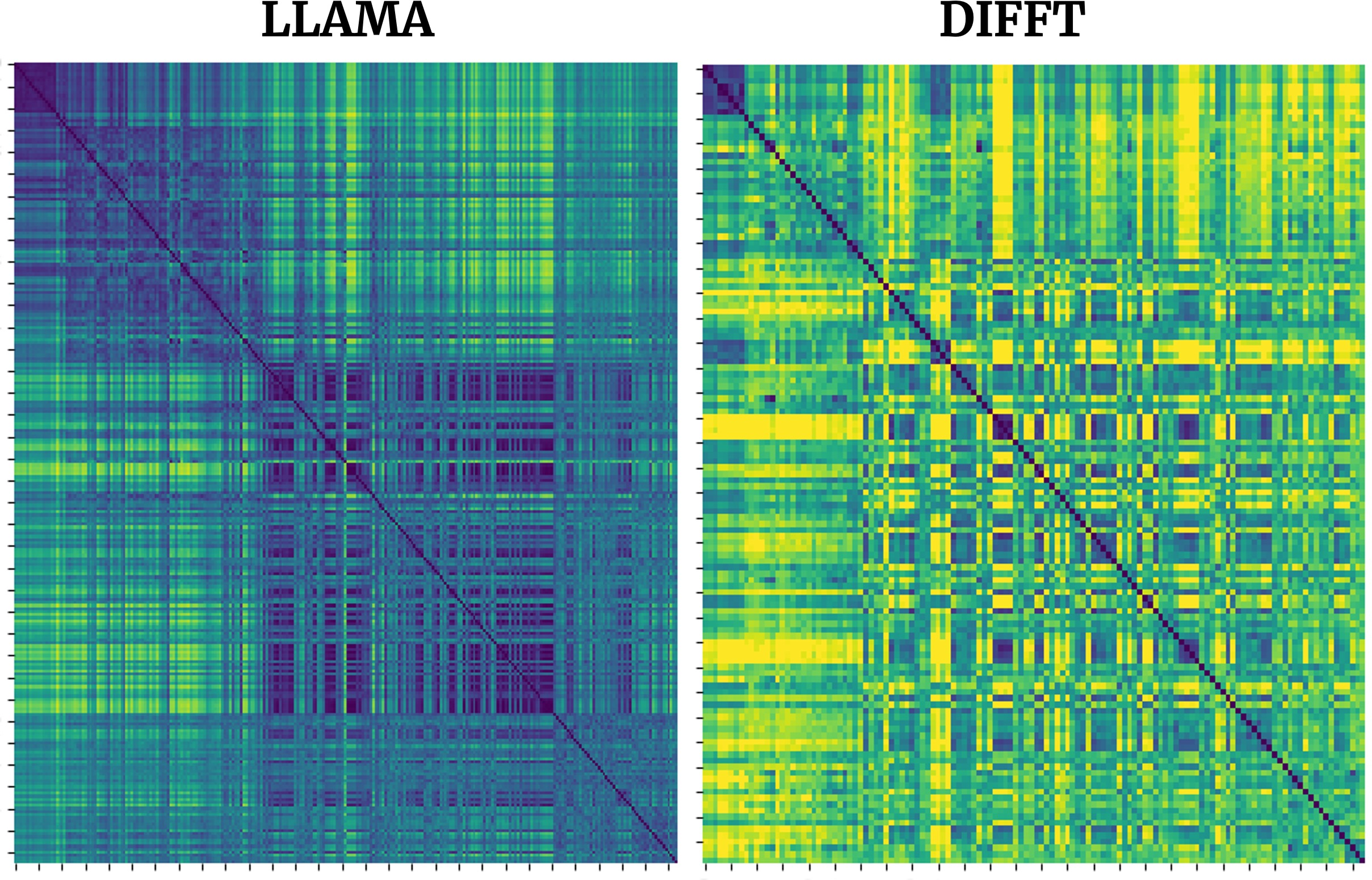
Paradoxically, Diff exhibits lower sparsity ratios and higher entropy in its attention heads compared to conventional models (Figure 1).
Figure 1: Sparsity ratio (ε=1×10−4) highlights the broader distribution of attention scores in Diff.
Improved Expressivity Through Negative Attention
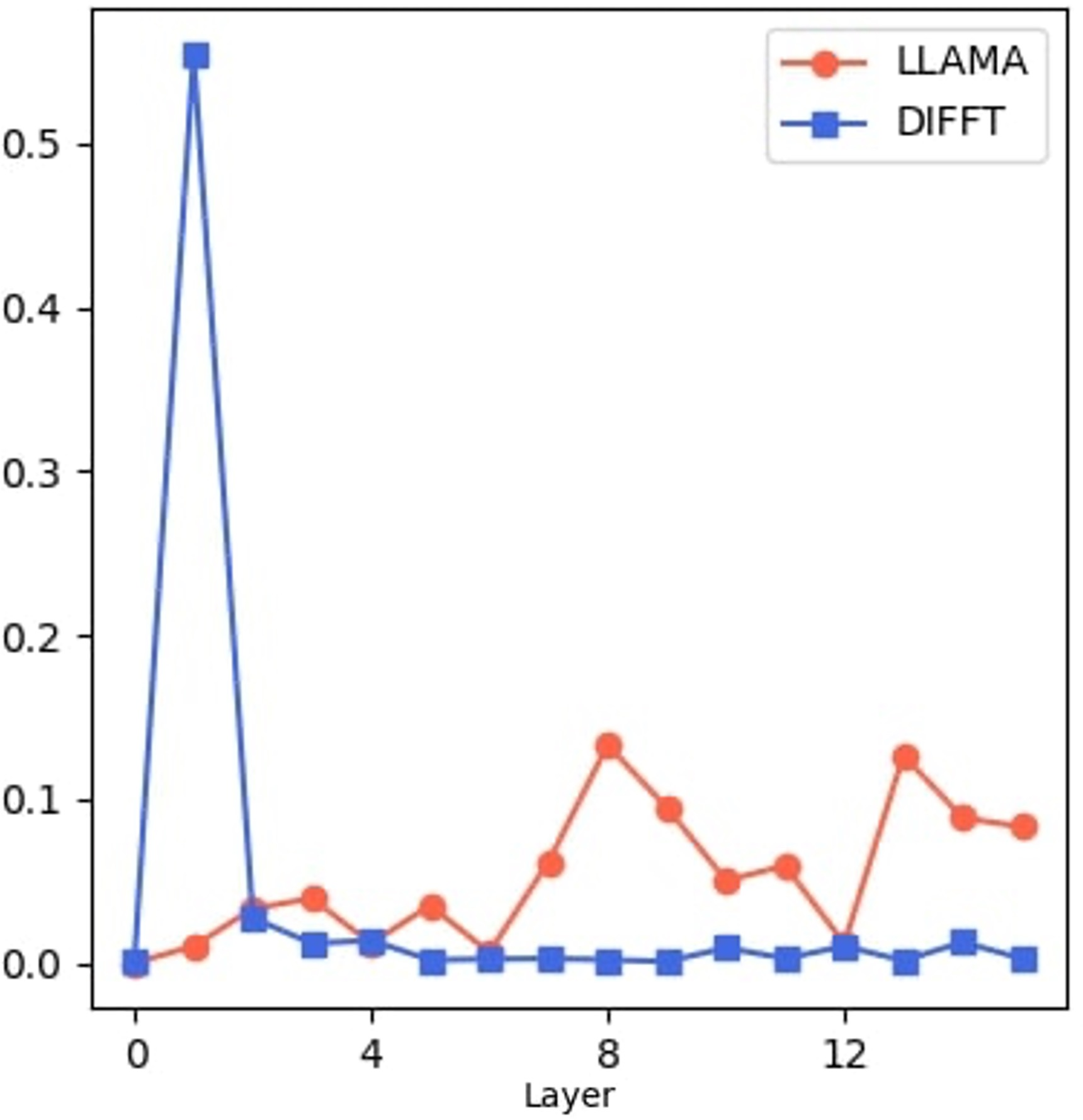
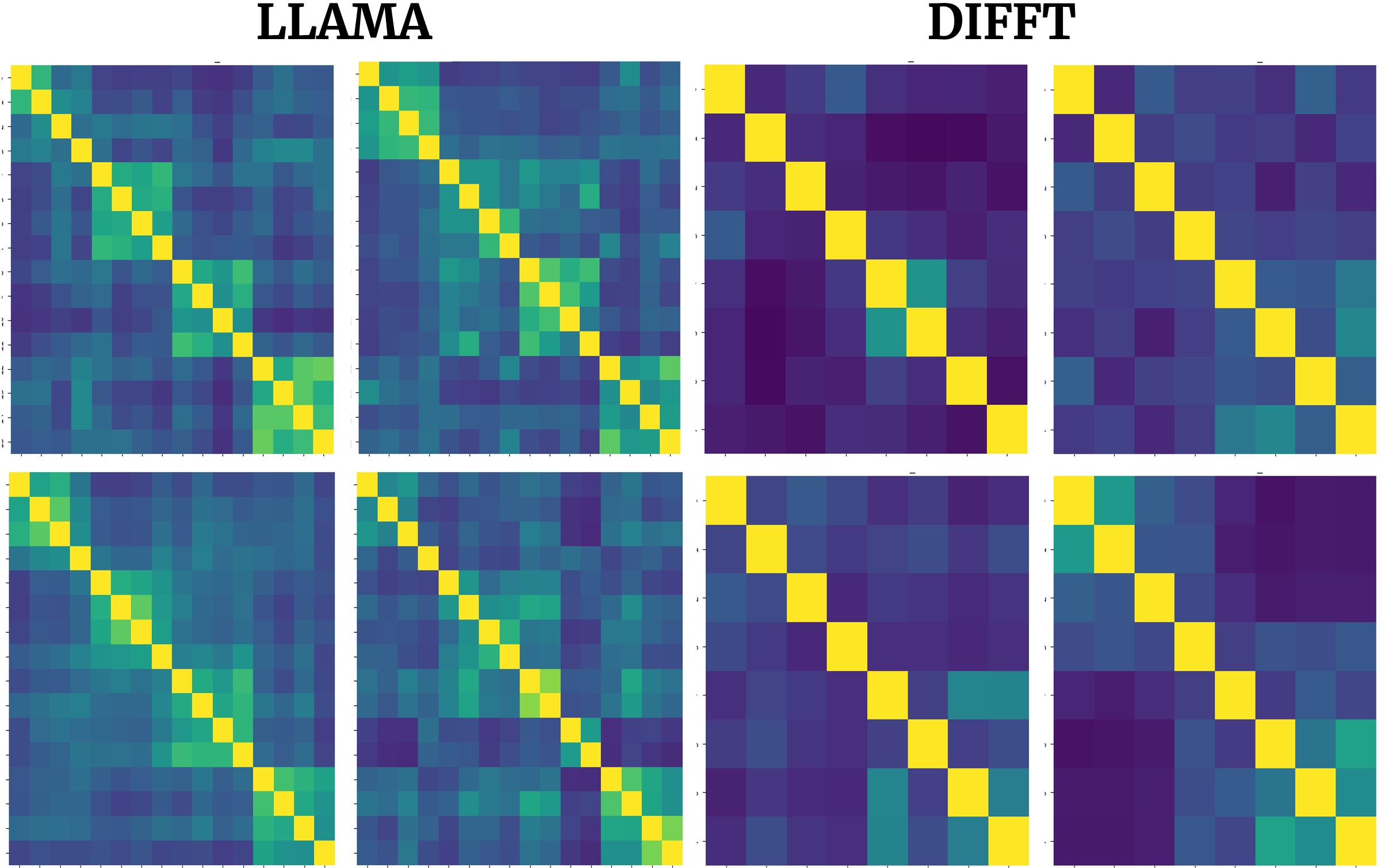
The novel implementation of negative attention in Diff permits a finer grained control over which tokens are deemed less relevant, allowing for more expressive and contextually rich representations. Diff assigns negative scores to non-salient tokens, enabling the model to suppress unnecessary information while enhancing meaningful token interactions (Figure 2).
Figure 2: Cosine distance between attention scores emphasizes structural similarities in attention calculations across layers, but highlights Diff's unique head-specific score distributions.
Reduced Attention Head Redundancy
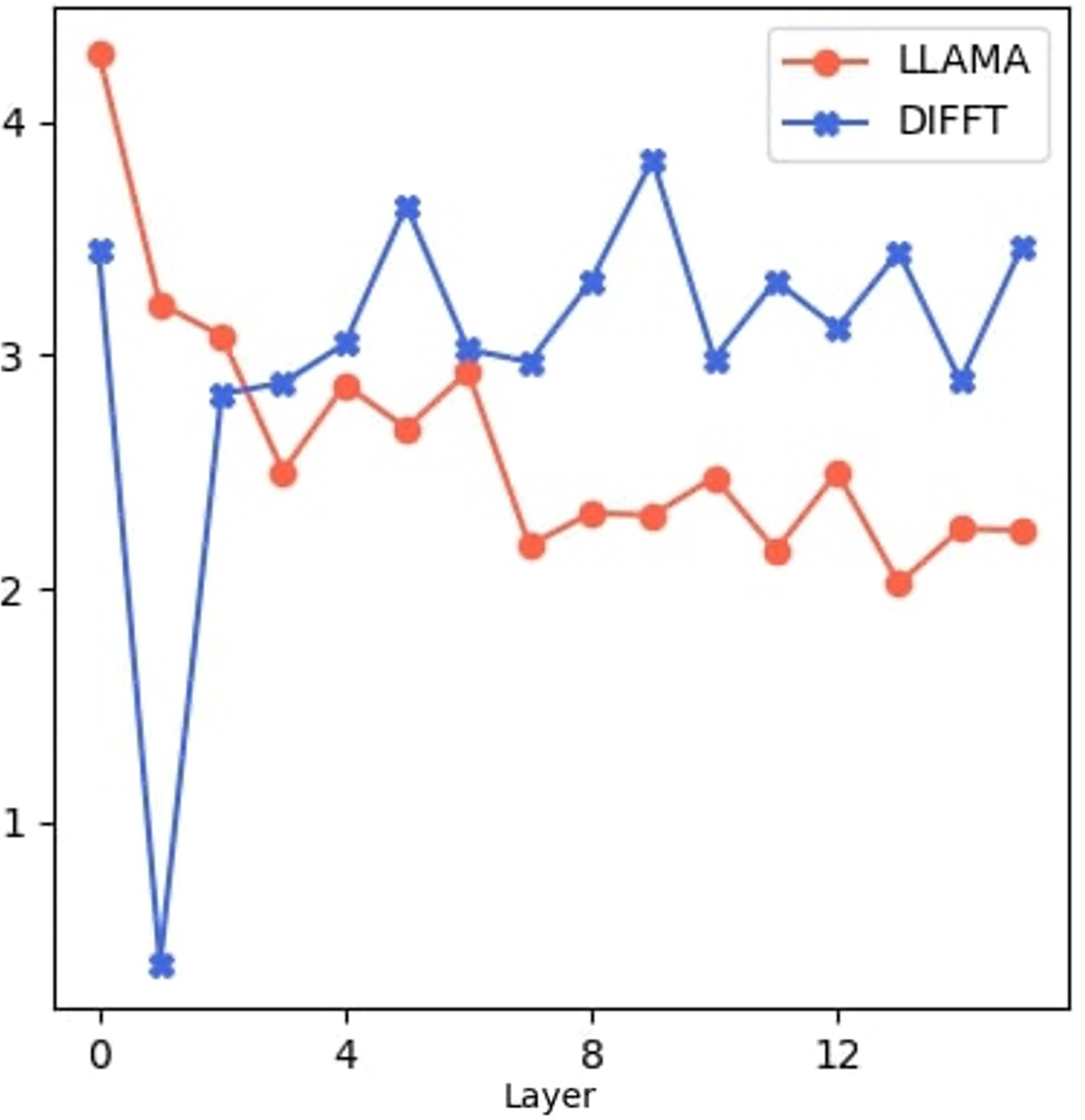
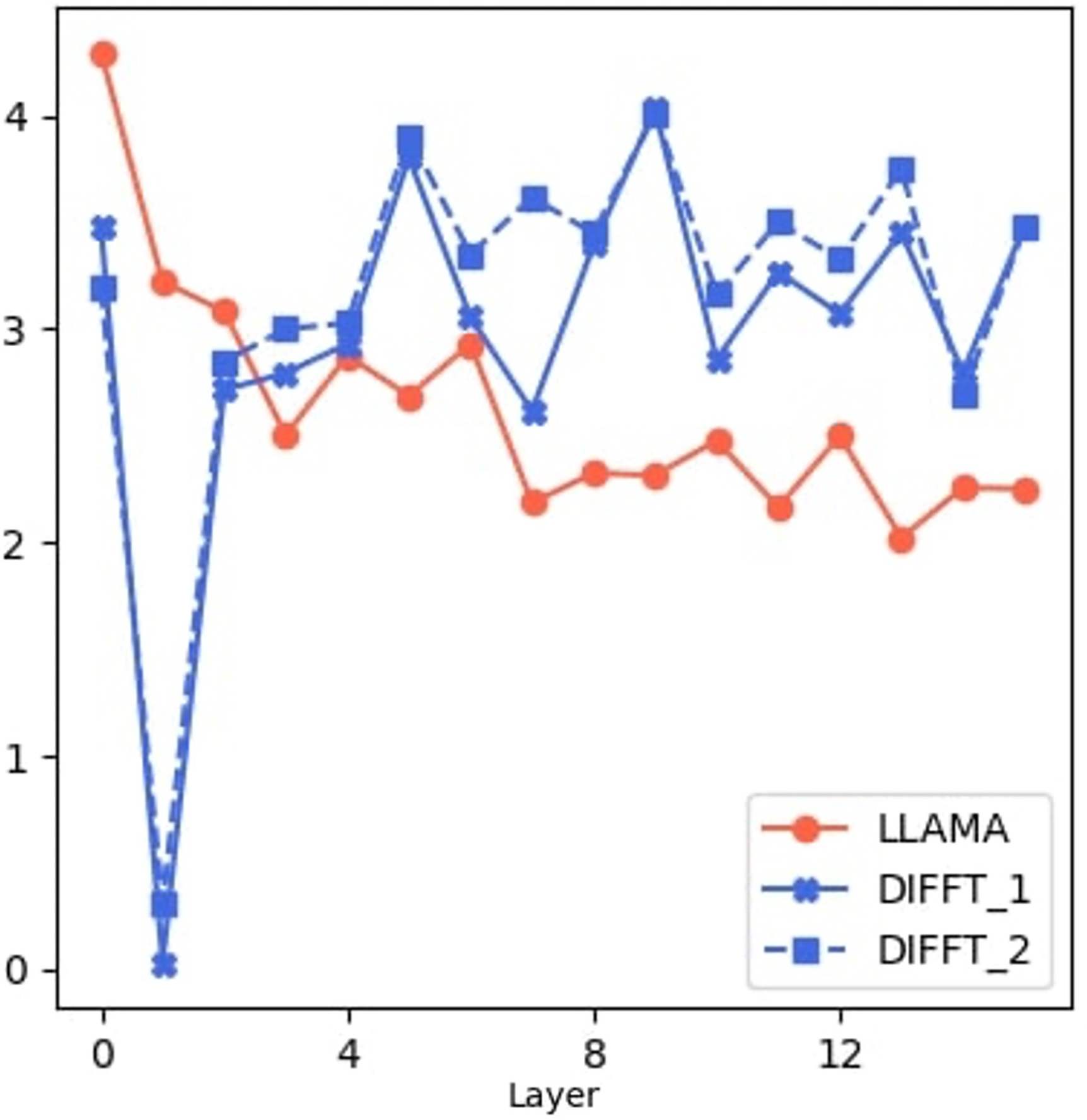
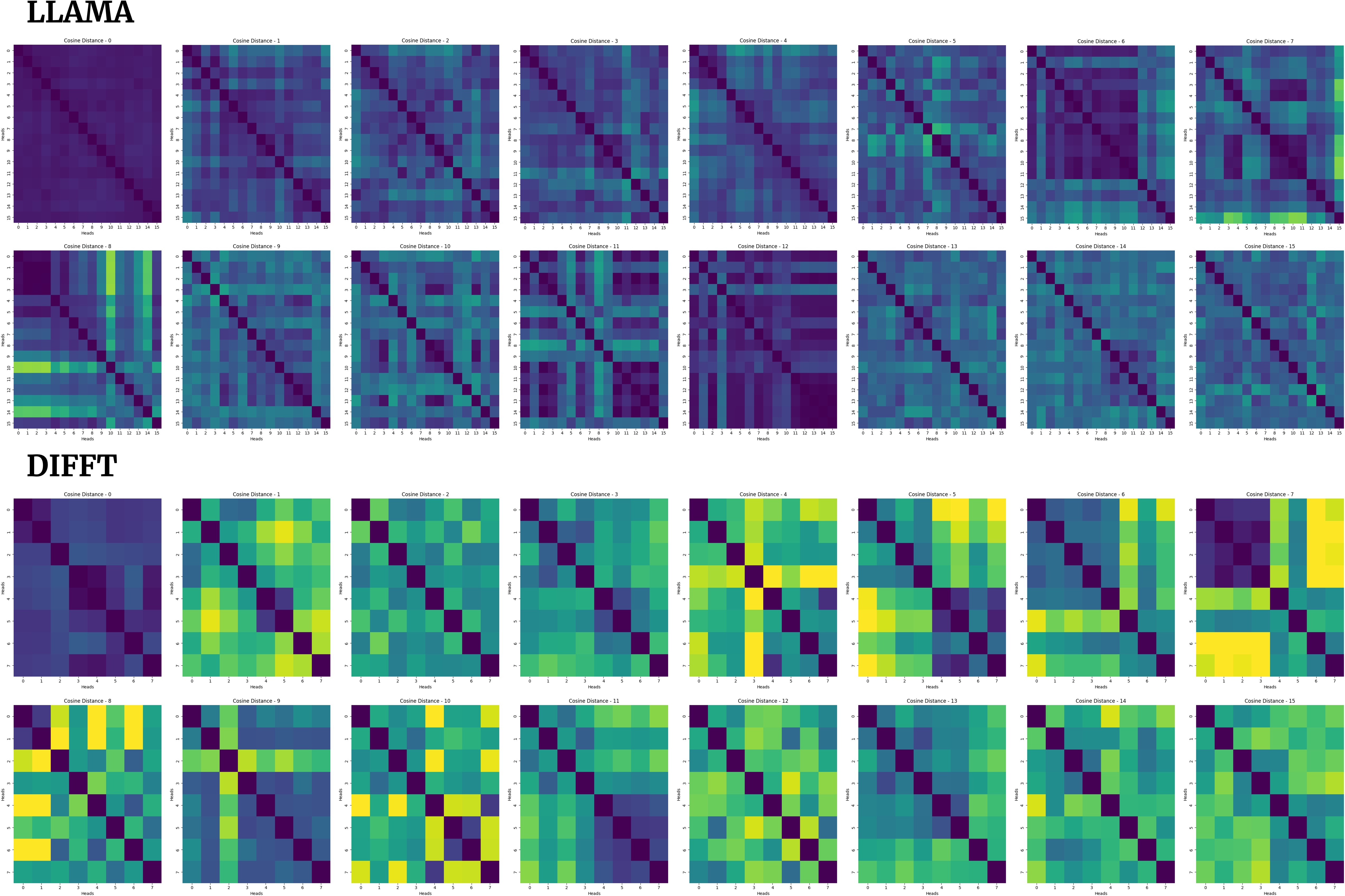
Diff's architectural novelty reduces redundancy among attention heads in transformers. By increasing diversity in attention focus, Diff distributes the representational workload more evenly across heads, minimizing overlapping functions and improving the model's capacity to learn diverse features efficiently. Pairwise cosine distances between attention heads provide evidence for this reduced redundancy (Figure 3).
Figure 3: Bright regions demonstrate reduced redundancy, corresponding to higher pairwise cosine distances between attention maps.
Dex: Efficient Integration With Pretrained Self-Attentions
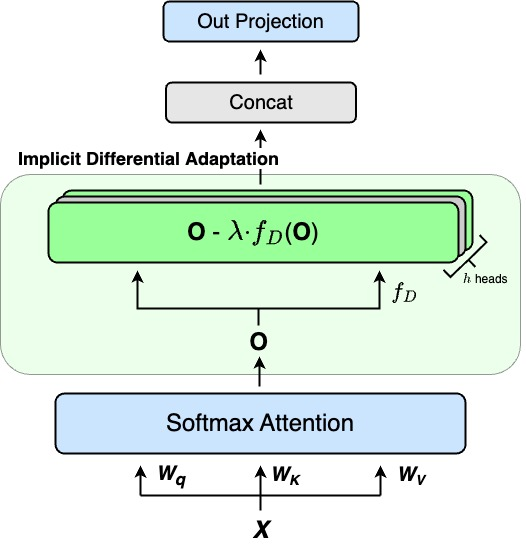
Dex synthesizes the benefits of Diff's attention by reintegrating its strengths into pretrained models. By injecting differential mechanisms in the output value processing rather than the attention computation phase, Dex maintains computational efficiency and achieves performance improvements without extensive modifications or retraining of the underlying model structure. This efficient adaptation leverages pretrained attention maps (Equation 2):
O=softmax(dQKT)V−λ⋅fD(O),
where λ is a learnable parameter initiating differential adaptation (Figure 4).
Benefits of Learnable λ and Adaptive Head Selection
Dex introduces a controlled adaptation through a learnable λ, which provides a stable transition between pretrained model dynamics and Dex's architectural modifications. Selective head adaptation further ensures that computation resources are devoted to the most relevant components, enhancing the representational power of the model while preserving essential pretrained knowledge.
Conclusion
The integration of differential mechanisms through Dex establishes a profound improvement in the expressive capacity and performance stability of LLMs. By maintaining computational efficiency and leveraging existing pretrained structures, Dex makes significant advancements towards scalable, high-performance transformer models. This research lays the groundwork for future explorations into noise-robust architectures, vector differential adaptations, and learning dynamics calibration, which could fundamentally transform the landscape of neural network architectures in natural language processing tasks.