- The paper demonstrates a provable three-stage convergence where the transformer learns generalized induction heads through sequential parent selection, token copying, and output classification.
- It introduces a modified chi-square mutual information method in the FFN to optimally select parent subsets from n-gram Markov chains, with concrete convergence rates.
- Experimental validation shows robust generalization to longer sequences and varied priors, underscoring the critical, nonredundant roles of each transformer component in in-context learning.
Introduction
This work rigorously characterizes the emergence and role of induction head-like mechanisms in transformer-based models during in-context learning (ICL) on n-gram Markov chain data. Unlike prior analyses restricted to simplified architectures or first-order Markov chains, the authors provide a mathematically precise account of how a two-attention-layer transformer—with relative positional embedding (RPE), multi-head softmax attention, and a feed-forward network (FFN) with normalization—learns to implement a generalized induction head (GIH). The theoretical results are substantiated by experiments, establishing concrete relationships between transformer architecture, training dynamics, and feature selection relevant to ICL.
Theoretical Framework and Model Construction
Task Setting and Model Overview
- Data: Sequences sampled from a mixture of random n-gram Markov chains.
- Model: A two-attention-layer transformer TF(M,H,d,D):
- RPE: Each attention head in the first layer attends over a window of size M.
- Multi-head Attention: H parallel heads.
- FFN: Implements a low-degree polynomial kernel with normalization (layer norm).
- Final Classifier: Second attention layer uses learned similarity scores to predict next token.
Induction Head Mechanism and Generalization
The induction head, originally observed empirically and characterized for first-order Markov chains (i.e., bigram tasks), is generalized to n-gram settings. Here, prediction depends on statistically relevant subsets of the past n tokens, not just single-parent copying.
- Selector: The FFN, via a low-degree polynomial kernel, selects an informationally optimal subset of the Markov parents using a modified χ2-mutual information criterion.
- Copier: The first attention layer learns to deterministically copy tokens at parent positions into the representation for a given timestep.
- Classifier: The second attention layer aggregates those context tokens for which the relevant parent pattern matches that at the output position, performing exponential kernel regression for prediction.
The process is visually summarized below.
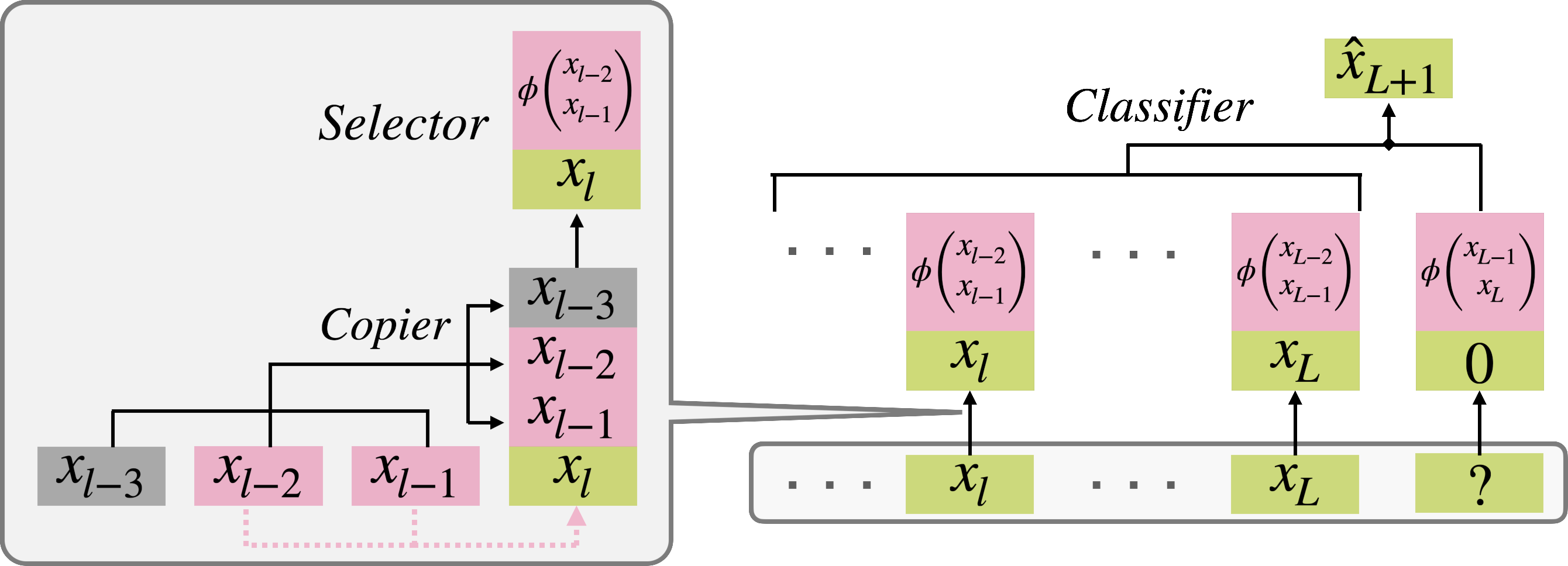
Figure 1: A depiction of the Generalized Induction Head (GIH) process, highlighting the copiers (heads), selector (FFN), and classifier modules acting in concert to produce the output from a Markov chain prompt.
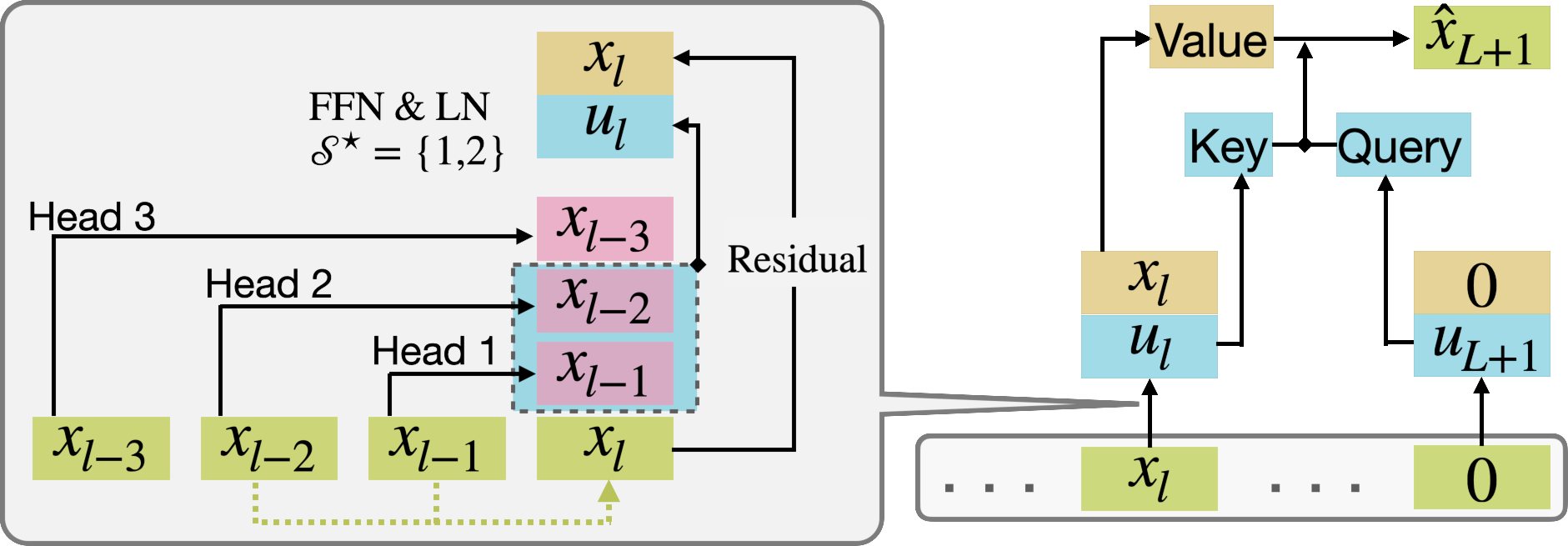
Figure 2: Schematic: the first layer copies parent tokens corresponding to the parent set, selector chooses information-rich subsets (e.g., $\cS^\star$), and the classifier head matches features to produce the final output.
The selection of which parent subset to condition on—critical for nontrivial Markov structure—is achieved by maximizing a modified χ2-mutual information, formally:
$\tilde I_{\chi^2}(\cS) = \mathbb{E}\left[\left(\sum_{e \in \mathcal{X}} \frac{\mu^\pi(z=e \mid Z_{-\cS})^2}{\mu^\pi(z=e)} - 1\right) \cdot \mu^\pi(Z_{-\cS})\right]$
Here, $\cS$ is a candidate subset of parent indices. This quantity balances two effects:
- Statistical informativeness of the subset (favoring large $\cS$).
- Estimation error/model complexity (favoring smaller $\cS$).
Thus, the optimal subset maximizes relevant historical information with manageable generalization error—showing that the transformer does not simply memorize exact Markov parent sets but makes statistically optimal choices based on training data and sequence length.
Provable Training Dynamics: Three-Stage Convergence
The main theoretical result is a precise characterization of the gradient flow of cross-entropy loss minimization (in the population limit) into three distinct stages, each corresponding to learning a component of the GIH mechanism.
Stage I: Parent Selection (FFN dominates)
- Only the FFN/selector parameters are updated.
- Among all possible parent subsets, the one maximizing the modified χ2-mutual information is exponentially selected (its corresponding FFN kernel weight dominates all others).
- Analytical rate: $p_{\cS^\star}(t) \to 1$ exponentially fast.
(Figure 3, panel a)
Figure 3a: Exponential domination of the optimal subset's FFN weight $p_{\cS^\star}$ during the first phase.
- Heads in the first attention layer specialize to copy unique parents for the subset $\cS^\star$; attention weights approach one-hot vectors focusing on unique parent tokens.
- Each attention head converges to deterministic copying over time, with convergence rate polynomially in time.
(Figure 3, panel b)
Figure 3b: Transition of attention weights to focus on single parents, corresponding to the selector's set.
- The scalar weight in the second attention layer starts to dominate, growing logarithmically, which increases focus on matching parent histories.
- Eventually, only positions matching the current output token's parents (according to $\cS^\star$) are used in prediction, which recovers the GIH mechanism.
(Figure 3, panel c)
Figure 3c: Slow regime transition as the classifier parameter a grows, sharpening matching for next-token prediction.
Expressivity, Emergence, and Approximation Guarantees
- Exact GIH recovery: The limiting transformer model converges to the GIH mechanism up to diminishing errors, as sequence length L→∞.
- Approximation error bound: After the three-stage process, difference between the transformer's output and the GIH is O(L−a/logL), with high probability.
- Origin of structure: The theoretical analysis explicitly shows that each architectural component contributes a unique, nonredundant role in ICL:
- Multi-head design enables copying of the parent tokens.
- Feed-forward with polynomial kernel and normalization enables selection and feature construction.
- Second-layer attention with large scalar parameter enables exponential kernel-based context aggregation.
Experimental Validation and Ablations
All theoretical claims are supported by measured training dynamics and ablations:
- When trained in three-stage separation, the expected convergence dynamics are clearly observed, with rapid selection of $\cS^\star$, specialization of heads, and then slow growth in the classification layer parameter.
- End-to-end training (without stage splitting) is empirically observed to eventually yield the same structure, though with slower, sometimes non-monotonic, selection of the true parent set.
- Model generalizes well when tested on longer sequences and sampling from Markov chains with different prior distributions, confirming that the learned GIH mechanism is robust to length and prior shifts.
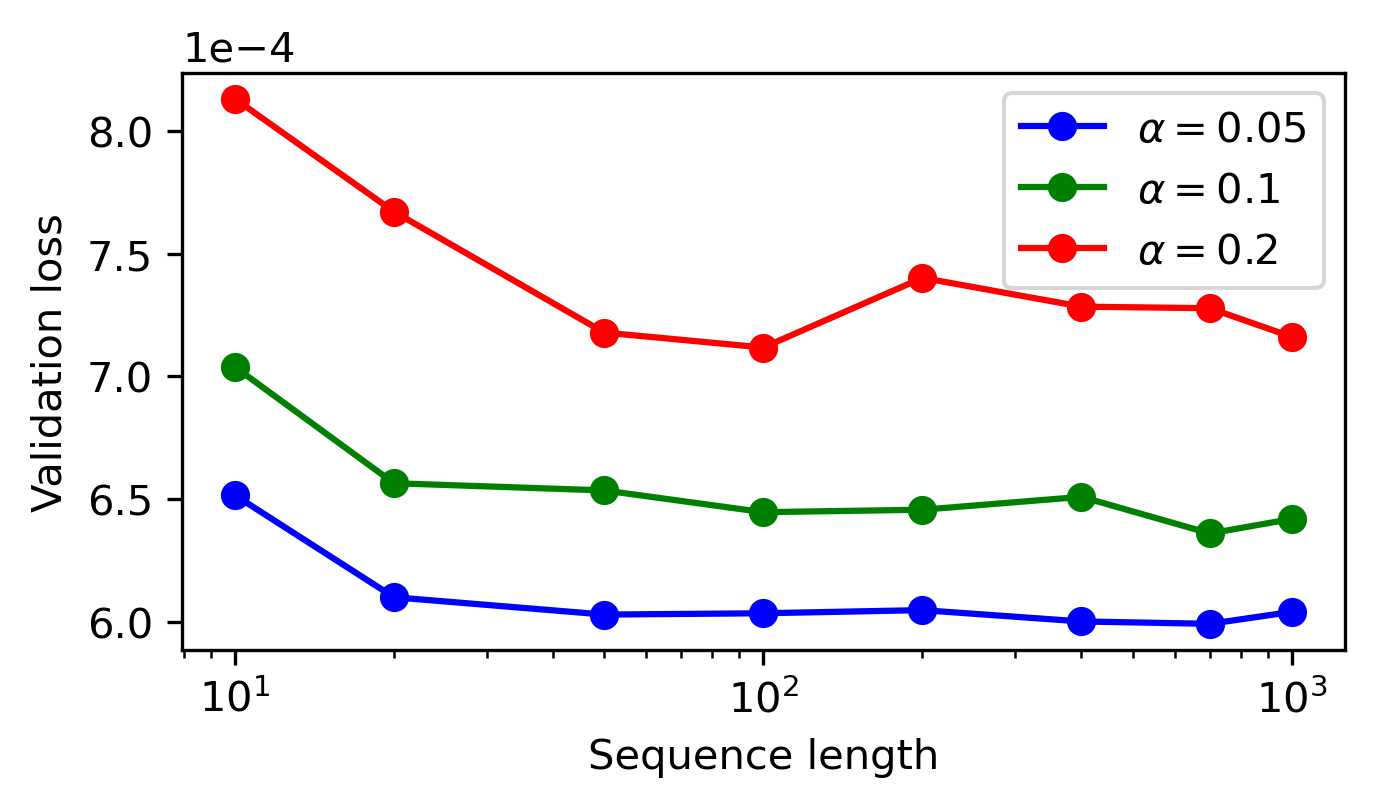
Figure 4: Cross-entropy loss of the pre-trained model across varying sequence lengths and prior Dirichlet concentration α, showing robust generalization beyond training configuration.
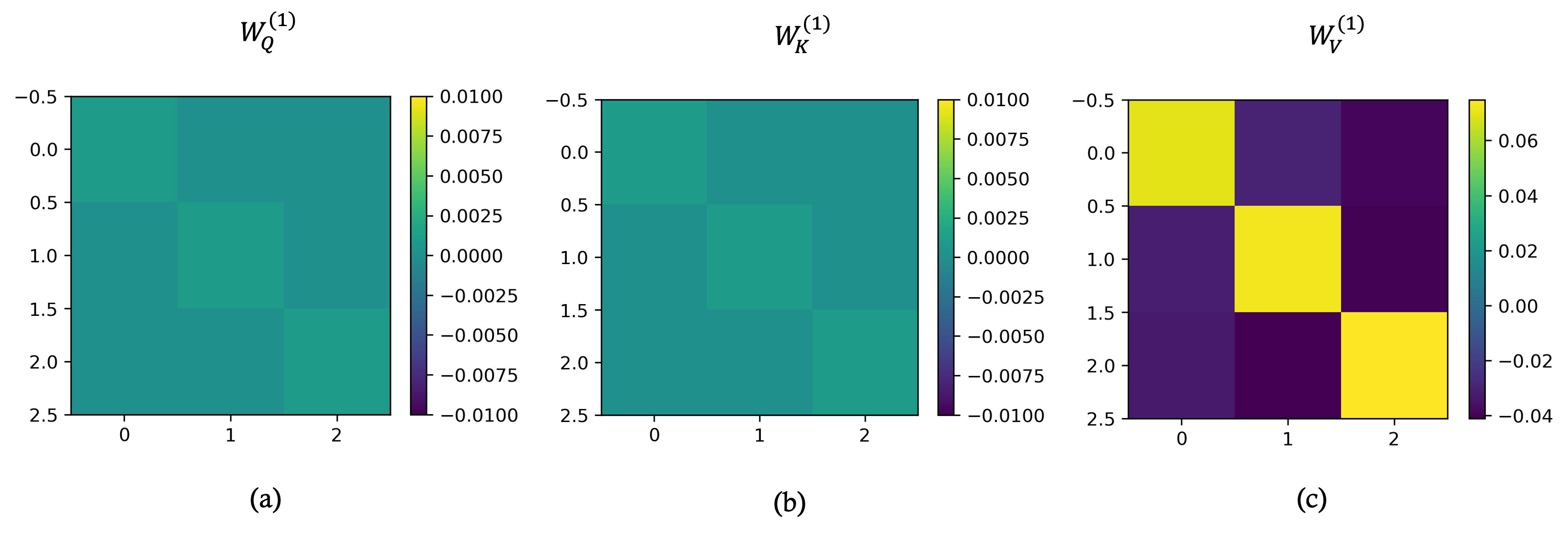
Figure 5: Visualization of embedding matrices after full model training; WQ and WK collapse to (near-)zero matrices, while WV becomes nearly diagonal—empirically justifying the architectural simplifications in the theoretical analysis.
Implications, Limitations, and Future Directions
Practical and Theoretical Implications
- The analysis establishes that full-featured transformer blocks—beyond the mere attention operation—are provably indispensable for ICL with correlated data (Markovian or otherwise).
- The three-stage convergence analysis provides a predictive blueprint for interpretable modularity in transformer training: parent sets (and hence "causal" graph structure) can be read from selector/FFN weights; token copying is manifest in attention score specialization; matching for output relies on classifier sharpness.
- The generalized induction head mechanism formalizes transformer behavior on tasks with structured data dependencies, extending earlier empirical circuit interpretations to higher-order Markov and more realistic data generating processes.
Limitations and Potential Extensions
- The theoretical results are shown for a model using a polynomial kernel FFN. Extending the analysis to standard MLP-based FFN with usual activations and true learned layer normalization remains open.
- Scalability to deeper transformer stacks or to other forms of complex data dependencies (beyond fixed n-gram Markov) is not established here, though the authors conjecture similar modularity could be shown.
- Iterative programs (e.g., chains-of-thought or recursive reasoning heads) are not addressed but would be natural next steps.
Speculative Future Directions
- Mechanistic interpretability: These results support extraction of mechanistic circuits from trained LLMs in practical settings, with selector weights and RPE serving as transparent indicators of learned "code".
- Architecture design: The demonstrated functional separation between selection/copying/classification may motivate architectural variants with explicit enforcement or encouragement of such separation for enhanced interpretability or modularity.
- Meta-learning and causal discovery: Since selector weights provably identify information-optimal causal parents, similar structures could be leveraged for interpretable causal reasoning or meta-learning over tasks with latent data dependence.
Conclusion
This work supplies the most comprehensive and rigorous characterization to date of how transformers, via gradient-based training, implement in-context learning on structured, correlated data. The emergence of a generalized induction head—modularly constructed from standard transformer components and theoretically pinned down through the provable convergence of training dynamics—clarifies both the internal computation and the necessity of each architectural block. The results unify mechanistic interpretability with statistical optimality, provide concrete guidance for transformer interpretability research, and open avenues for principled, modular architecture design.