- The paper introduces a framework that uses interleaved Markov chains to guide attention mechanisms for dynamic causal structure identification.
- It constructs a three-layer attention-only transformer that integrates positional and semantic embeddings to implement Selective Induction Heads effectively.
- Empirical validation shows the proposed model approximates the Maximum Likelihood Estimate, achieving statistically significant performance improvements.
Selective Induction Heads: How Transformers Select Causal Structures In Context
Introduction
The paper introduces a framework to study transformers' ability to handle dynamic causal structures using interleaved Markov chains with varying lags. This framework unveils the formation of Selective Induction Heads, enhancing transformers' ability to predict next tokens by identifying correct causal structures in-context. This new mechanism enriches the understanding of transformers' decision-making processes.
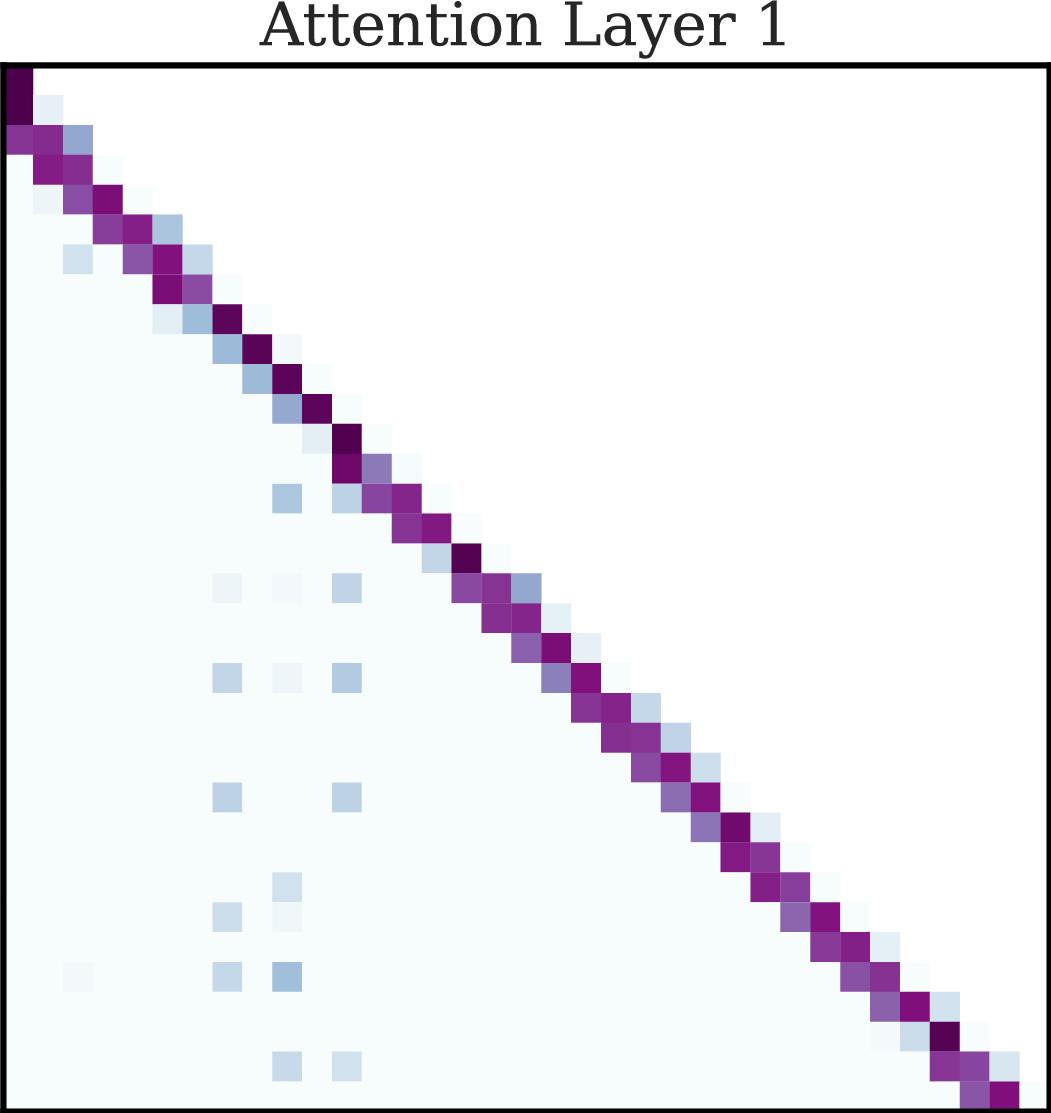
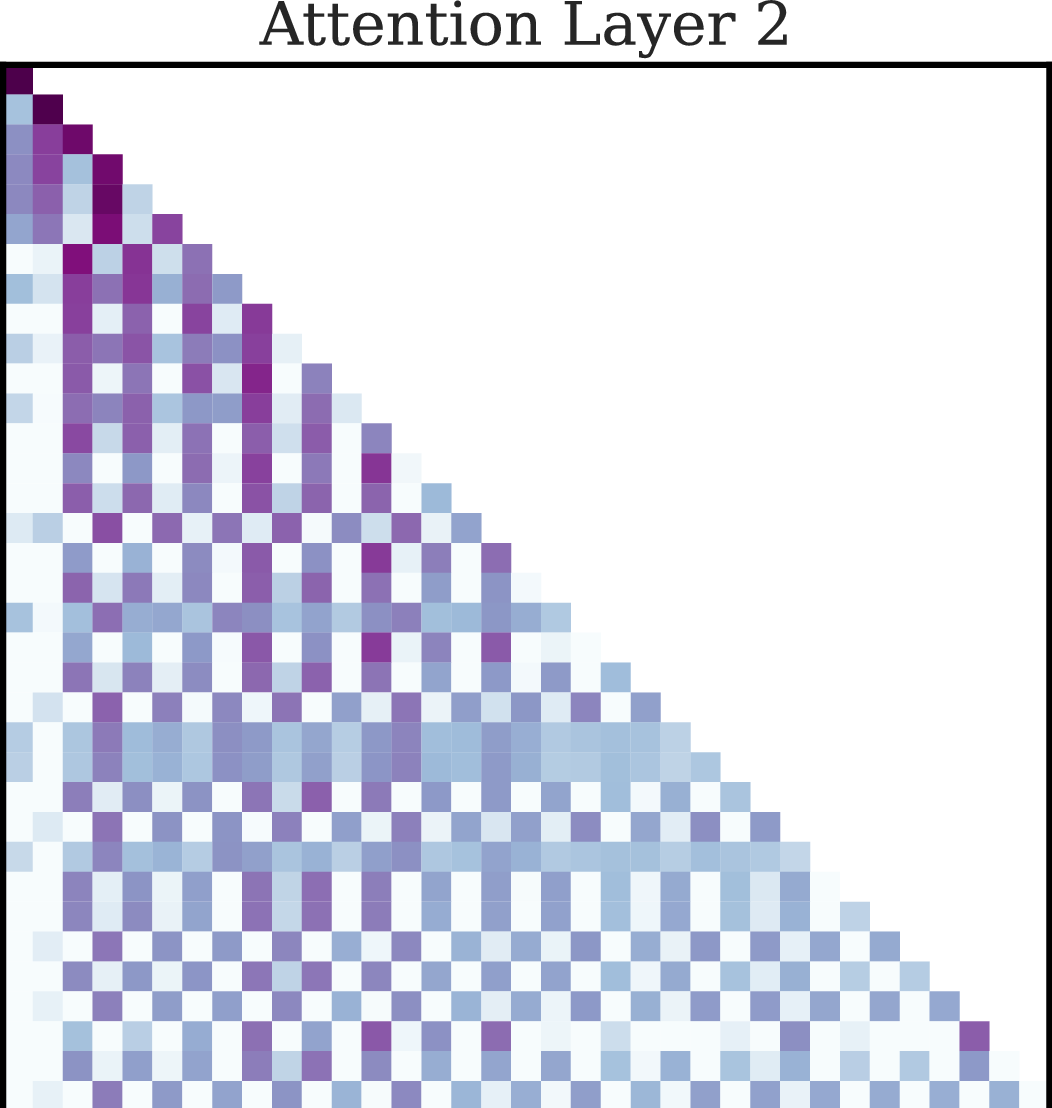

Figure 1: Summary of the framework involving interleaved Markov chains and attention-only transformers.
Framework and Problem Setup
The proposed framework hinges on interleaved Markov chains varying by lag, with a consistent transition matrix. The task is to predict the next state given a sequence of unknown lag. The model must solve the following minimization problem:
f⋆=finfE[DKL(P(XT+1∣XT−k+1)∥f(X1,…,XT))]
Here, DKL denotes the Kullback-Leibler divergence. The theoretical solution to this task is the Bayesian model average (BMA), which converges asymptotically to the Maximum Likelihood Estimate (MLE).
A three-layer attention-only disentangled transformer is constructed to implement Selective Induction Heads. Here's the pseudocode for the architecture:
- Input Layer: Maps input sequences into vectors using a canonical basis and positional encodings.
- First Layer: Computes transition probabilities for each lag using a specialized attention matrix.
- Second Layer: Aggregates past transition probabilities, storing them in the current token's embedding.
- Third Layer: Implements the selective induction mechanism, attending to the lag with the highest cumulative transition probability score.
The constructively designed attention heads efficiently implement this algorithm through a combination of positional and semantic embeddings.
Empirical Validation
Several experiments validate the proposed construction against standard transformers trained with Adam optimizer. The performance is measured using the KL-divergence between predicted and actual next-token distributions.


Figure 2: Performance comparison of constructed transformers against trained standard transformers and theoretical estimators.
In tasks with different lag configurations, the constructed models consistently match or exceed the performance of trained models, showcasing the effectiveness of the proposed selective induction mechanism.
The selective induction head mechanism, with large enough parameters, approximates the MLE effectively. Empirical results demonstrate the convergence of cumulative normalized transition probabilities, with the true lag showcasing statistically higher values.
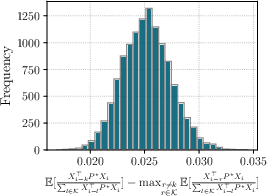
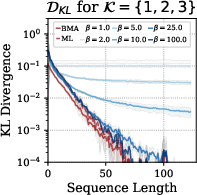
Figure 3: Empirical validation highlighting higher expected transition probabilities for the true lag.
Scaling Heads and Layers
Explorations in scaling transformer layers and heads suggest that while multiple heads can match optimal MLE performance, even fewer attention heads can robustly approximate the results. Additional layers beyond three do not yield significant performance improvements, indicating the sufficiency of a three-layer model.
Conclusions
The work advances the understanding of in-context selection mechanisms within transformers. The introduction of Selective Induction Heads demonstrates that attention layers can adaptively learn and apply causal structures dynamically, offering insights into potential optimizations in transformer architectures. This could guide future developments in training strategies and model interpretability.
Future work may focus on extending this framework to more complex causal structures and real-world data scenarios, further exploring the profound capabilities of transformers in handling dynamic sequential dependencies.