- The paper introduces a self-rewarding RL framework that uses the model itself to generate reward signals, bypassing the need for external annotated data.
- The methodology leverages Group Related Policy Optimization and is validated on English-Chinese benchmarks, demonstrating improved translation performance.
- The study indicates that SSR, especially when combined with external rewards, can enhance scalability and performance in low-resource machine translation scenarios.
SSR-Zero: Self-Rewarding Reinforcement Learning for Machine Translation
Introduction
The study "SSR-Zero: Simple Self-Rewarding Reinforcement Learning for Machine Translation" introduces a novel reinforcement learning (RL) approach specifically tailored for machine translation (MT) that does not rely on external reward models or human-annotated reference data. Despite the impressive abilities of LLMs in MT, the reliance on external supervision such as annotated reference data is a significant barrier due to the expense and difficulty in acquiring such resources. The proposed Simple Self-Rewarding (SSR) RL framework aims to tackle this challenge by implementing a self-judging mechanism using the model itself to generate reward signals. This method potentially reduces the overhead associated with scaling MT systems.
Methodology
The SSR framework employs a pre-trained LLM which acts dually as an actor and a judge within the training process (Figure 1). The model generates candidate translations for given inputs and evaluates these translations to derive reward signals. This approach follows an R1-like RL training paradigm but shifts the evaluation burden away from external models.
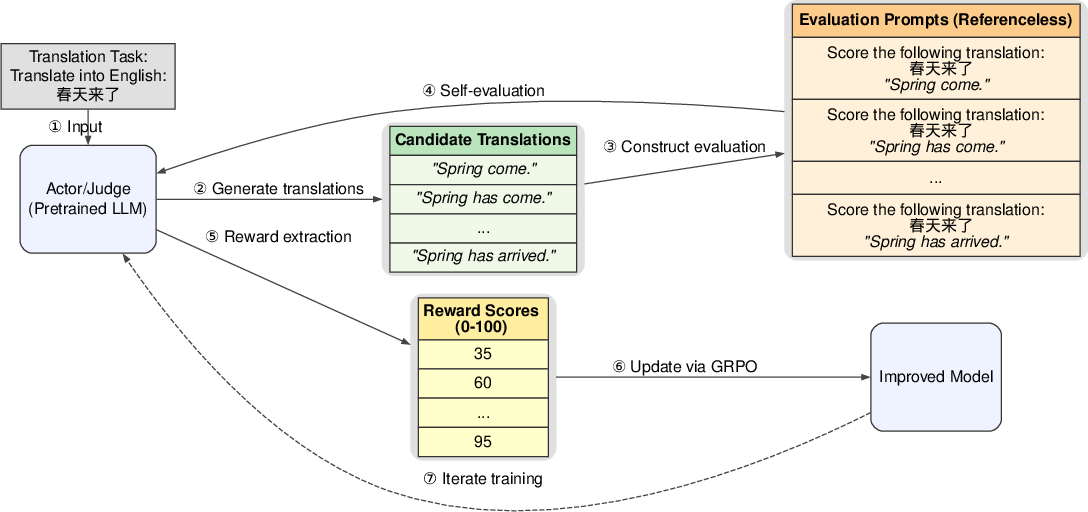
Figure 1: Overview of the SSR framework. SSR is an R1-Zero-like RL training method for machine translation, which uses the same model as both actor and judge. It does not require external reward models or human-annotated reference data. Prompts shown here are simplified for clarity.
The SSR method utilizes Group Related Policy Optimization (GRPO) for model optimization. Training involves GRPO updating of model parameters based on rewards computed from self-evaluated translations.
Experimental Setup
The experiments focused on English-Chinese translation tasks. The SSR-Zero model was built upon the Qwen2.5-7B backbone, trained on 13,130 monolingual examples. It was evaluated on several benchmarks, including WMT23, WMT24, and FLORES-200, using COMETKIWI-XXL and XCOMET-XXL metrics.
SSR-Zero-7B outperformed several existing open-source MT-specific models as well as some larger LLMs across English-to-Chinese (EN→ZH) and Chinese-to-English (ZH→EN) translation tasks. The model indicates substantial improvements in both directions with self-generated rewards leading to notable performance gains.
Enhancing SSR with external reward models such as COMET further improved the model, leading to SSR-X-Zero-7B achieving state-of-the-art (SOTA) performance in the evaluated benchmarks.
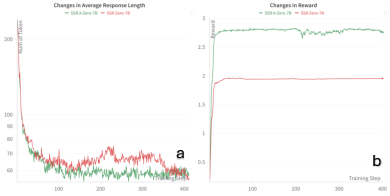
Figure 2: Changes in average response length (a) and training rewards (b) of SSR/SSR-X-Zero-7B during GRPO training.
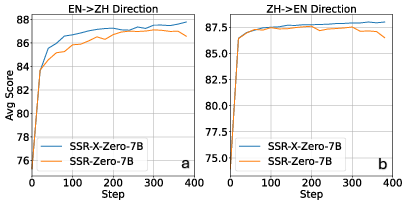
Figure 3: Changes in translation quality during training, measured by the average scores of COMETKIWI-XXL and XCOMET-XXL on the EN → ZH (a) and ZH → EN (b) benchmarks.
Comparative Analysis
The SSR framework has a clear advantage over external LLM-based rewards of similar size, indicating efficacy in leveraging self-generated feedback for performance enhancement. However, dedicated MT evaluation reward models like COMET and COMETKIWI exhibit superior capabilities when trained on substantial annotated data.
Conclusion
The SSR framework offers an effective methodology for training MT models devoid of extensive external resources. The research demonstrates the capability of SSR to enhance translation performance significantly and highlights the complementary benefits when combined with external reward signals. This self-rewarding approach opens avenues for developing scalable MT systems with reduced dependency on external supervision, especially beneficial in low-resource scenarios. Future investigations may expand the applicability of SSR across different languages and model architectures, while exploring the potential of alternative prompting and self-improvement techniques.