- The paper presents a novel cascade pruning-quantization (CPQ) method that dynamically prunes insignificant KV cache elements and quantizes remaining data, achieving up to 159.9× energy efficiency improvement.
- It leverages a Compute-in-Memory design and dedicated pruning units to reduce redundant computations, resulting in a 34.8× throughput gain over Nvidia A100 GPUs.
- Experimental results validate Titanus's effectiveness, showing a 58.9% reduction in KV cache movements and significant improvements in both energy efficiency and throughput for LLM inference.
Titanus: Enabling KV Cache Pruning and Quantization On-the-Fly for LLM Acceleration
Introduction
The continual growth in the scale of LLMs has directed attention towards optimizing the computational and memory demands of model inference. Titanus proposes a sophisticated software-hardware co-design that performs KV cache pruning and quantization dynamically, or "on-the-fly", aimed at improving the efficiency of LLMs during inference. The core innovation, the Cascade Pruning-Quantization (CPQ) method, combined with a Hierarchical Quantization Extension strategy, achieves significant reductions in energy consumption and data movement overheads.
Algorithm Design
CPQ Compression Method
In LLMs, the cascade of pruning followed by quantization represents a potent strategy to minimize resource consumption. The CPQ method begins with pruning insignificant elements from the KV cache, determined by a threshold. Subsequent quantization focuses on non-zero elements, encapsulating both processes into a coherent flow that minimizes computational overhead.
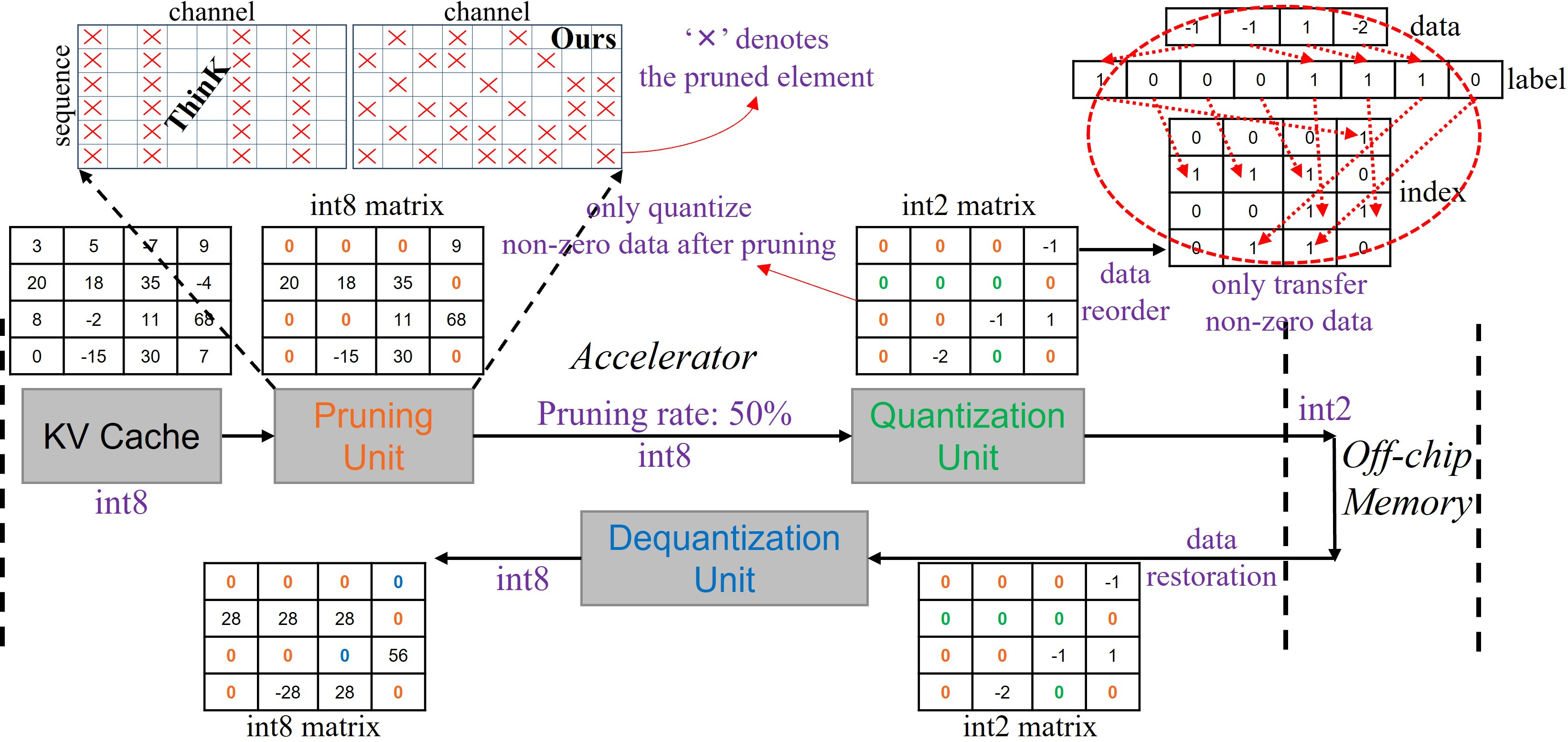
Figure 1: Overview of cascade pruning-quantization method.
Hierarchical Quantization Extension Strategy
This strategy addresses the challenges associated with non-independent per-channel quantization. The hierarchical nature allows dynamic adjustments in precision requirements for newly generated tokens during inference, avoiding repetitive quantization of tokens and ensuring minimal memory overhead with efficient handling of quantization parameters.
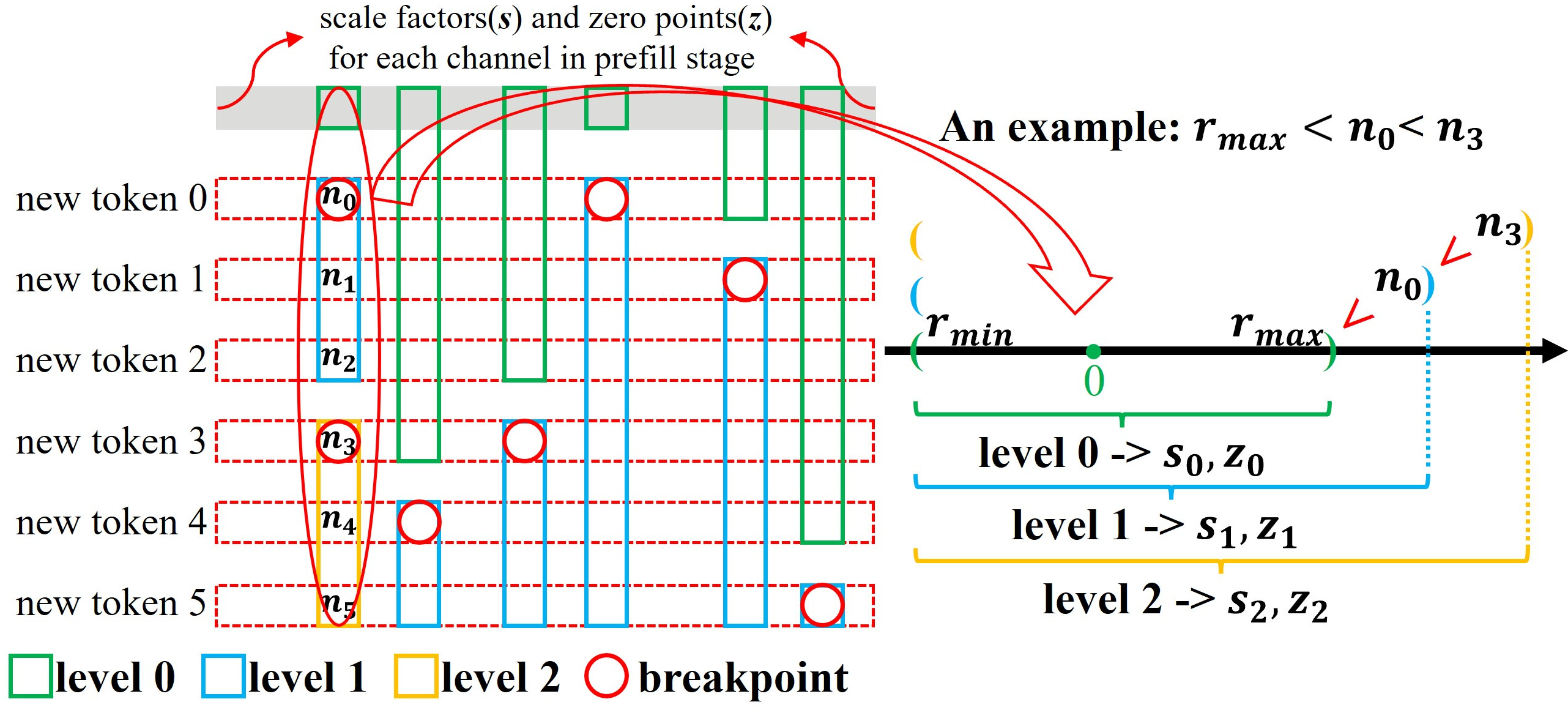
Figure 2: Hierarchical quantization extension strategy.
Hardware Architecture
Titanus Structure
Titanus exploits a Compute-in-Memory (CIM) design to hold static weights and processes using Digital CIM macros. The architecture integrates innovative units for pruning and quantization, which dynamically manage KV cache elements to efficiently leverage sparsity and reduce unnecessary data movement.
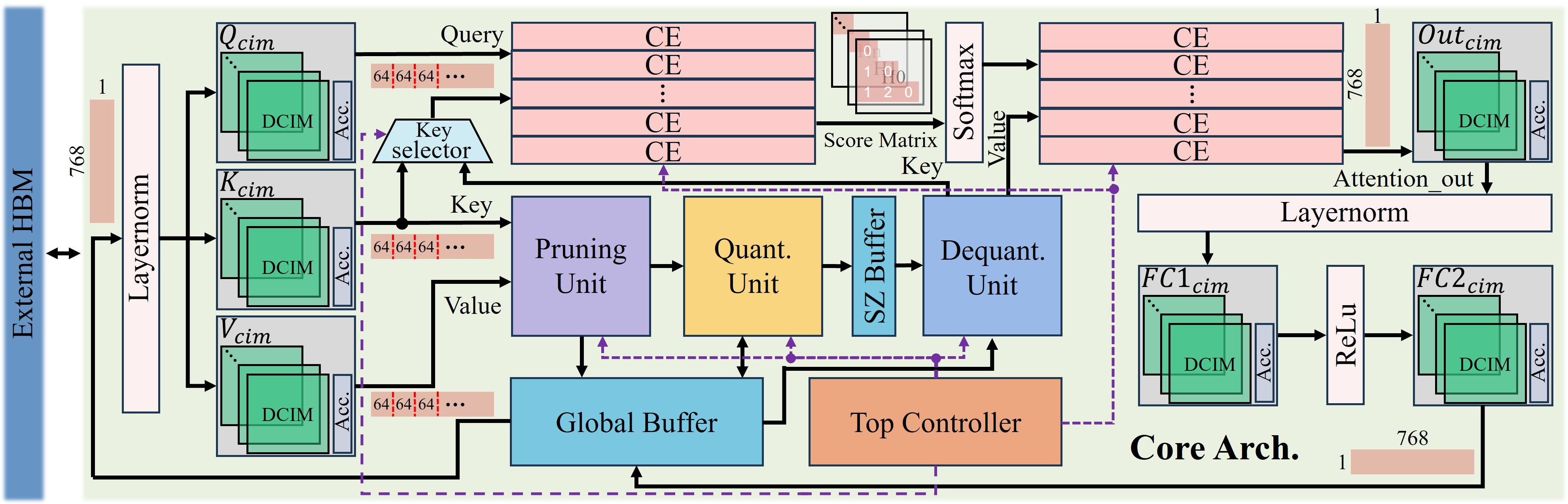
Figure 3: Titanus core-level overall architecture. CE and SZ denote the computing engine and scale-zero buffer, respectively.
Computing Engine and Pruning Unit
The Computing Engine features a zero-detection mechanism to skip redundant computations on sparse data, while the Pruning Unit selectively processes non-zero KV cache elements, directly supporting the CPQ method.
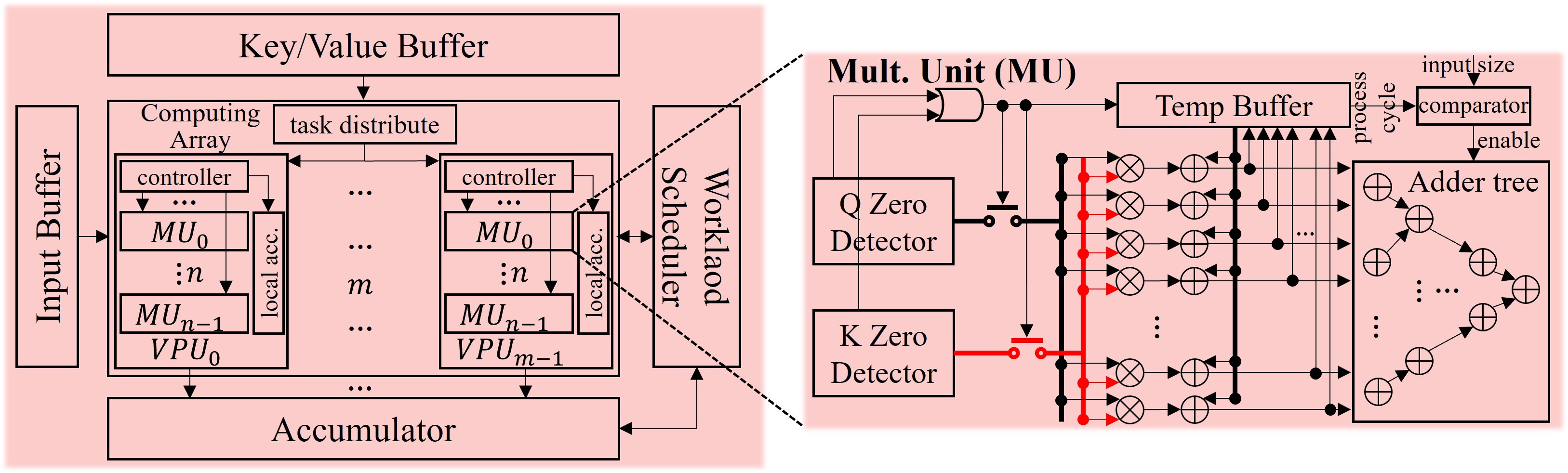
Figure 4: Computing engine design for dot-product attention with zero detection functionality.
Experimental Results
Empirical evaluation of Titanus demonstrated substantial improvements in both energy efficiency and throughput, attaining 159.9× energy efficiency and 34.8× throughput improvements over traditional configurations using Nvidia A100 GPUs. The CPQ method significantly reduced KV cache movements by 58.9%.
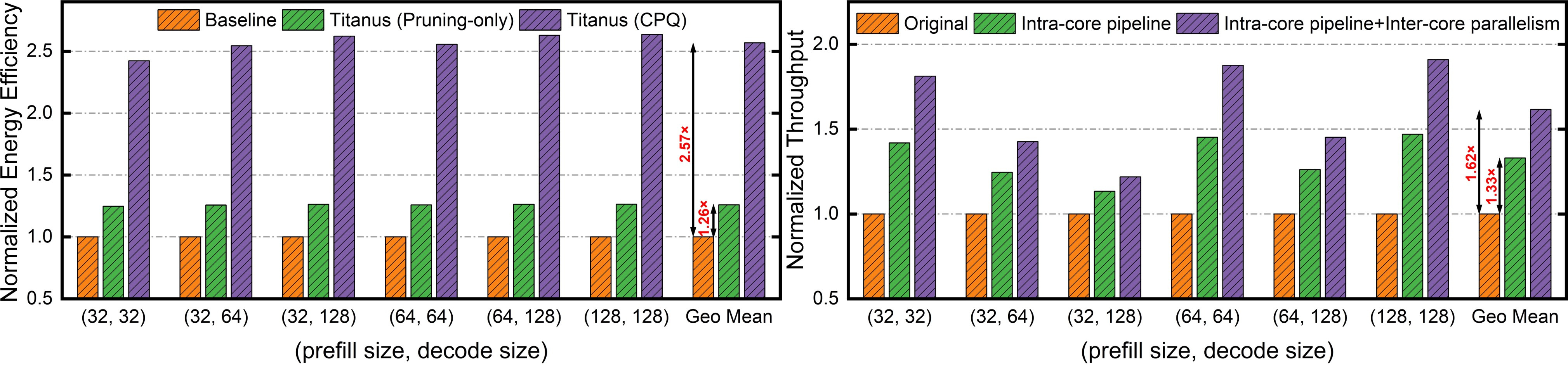
Figure 5: Energy efficiency~(Token/J) and throughput~(Token/s) improvement.
Conclusion
Titanus offers a robust framework for accelerating LLMs through strategic KV cache optimization, leveraging hardware-specific designs to maximize performance gains. The integration of algorithmic pruning and dynamic quantization represents a practical solution to the computational challenges posed by large-scale LLM inference, paving the way for more efficient deployment of LLMs across diverse applications.