- The paper demonstrates that mixing knowledge-dense data with web scrapes causes sudden, phase-transition-like improvements in learning based on model size.
- It reveals that beyond a critical mixing ratio or model size threshold, LLMs rapidly shift from minimal to substantial memory recall of dense datasets.
- The study validates a power-law relationship and proposes mitigation strategies like random subsampling and CKM to boost knowledge acquisition under low mixing ratios.
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
LLMs are typically trained using data mixtures composed of large-scale web scrapes and smaller, highly curated datasets containing dense domain-specific knowledge. The paper "Data Mixing Can Induce Phase Transitions in Knowledge Acquisition" investigates how these mixtures affect knowledge acquisition and reveals that, unlike when training exclusively on knowledge-dense data, knowledge acquisition from such mixtures can exhibit phase transitions with respect to the mixing ratio and model size.
Phase Transitions in Knowledge Acquisition
Phase Transition in Model Size
The study shows that as the model size increases beyond a certain threshold, the model rapidly transitions from memorizing few to most of the biographies in a synthetic dataset mixed with web data. Below the threshold, the model memorizes almost nothing, implying a sudden change in knowledge acquisition capability once this threshold is surpassed.
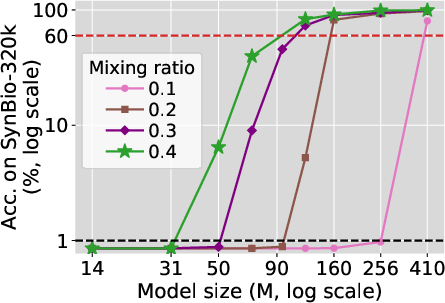
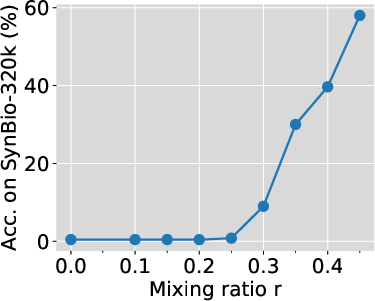
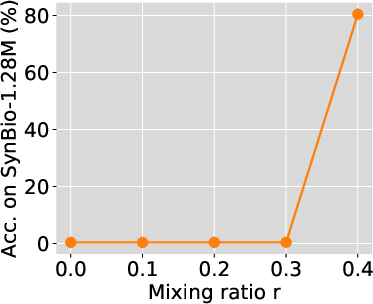
Figure 1: Phase transition in model size. For each mixing ratio, as model size increases, accuracy initially remains zero. Once model size surpasses some threshold, accuracy rapidly grows to over 60\%.
Phase Transition in Mixing Ratio
Similarly, fixing the model size, as the mixing ratio increases beyond a critical value, the model's ability to memorize the dataset dramatically improves. Below this critical mixing ratio, extensive training does not help, and models memorize almost nothing regardless of the number of training iterations.
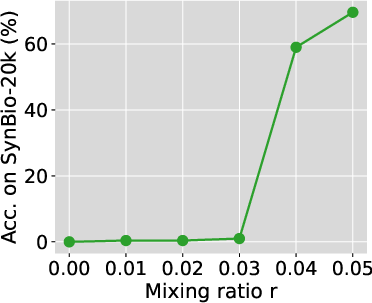
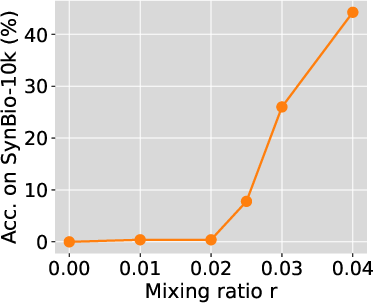
Figure 2: Phase transition in mixing ratio persists for larger models. We train Pythia-2.8B and 6.9B with 2B and 1B total training tokens, respectively. Smaller SynBio datasets mixed with FineWeb-Edu were used to ensure adequate exposure.
Theoretical Insights
The paper attributes these phase transitions to a capacity allocation phenomenon, which resembles solving a knapsack problem. The theoretical analysis suggests that a model with bounded capacity must allocate its resources optimally across different datasets to minimize overall test loss. The optimal distribution changes discontinuously as model size or mixing ratio varies. These transitions were found to follow a predictable pattern, governed by a power-law relationship between model size and mixing ratio.

Figure 3: An illustration of the intuition behind our theory.
Experimental Validation and Strategies
Power-Law Relationship in Threshold Frequency
Experiments validate a power-law relationship where the threshold frequency, above which a fact is learned, decreases as model size increases, approximately following a power-law exponent that relates to the model scaling exponent plus one.
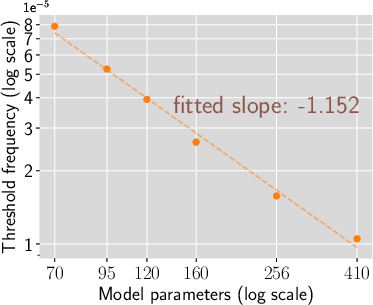
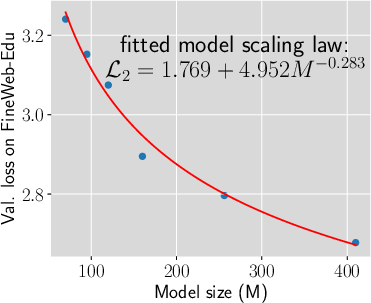
Figure 4: Validating the power-law relationship of threshold Frequency and model size.
Mitigation Strategies
Two strategies are proposed to boost knowledge acquisition, especially under low mixing ratios:
- Random Subsampling: Randomly subsample the knowledge-dense dataset to increase exposure frequency.
- Compact Knowledge Mixing (CKM): Rephrase knowledge into compact forms and augment the original dataset.
These methods aim to increase the "marginal value" of the dense dataset within the mixture, resulting in significant improvements in knowledge recall without compromising general model performance.
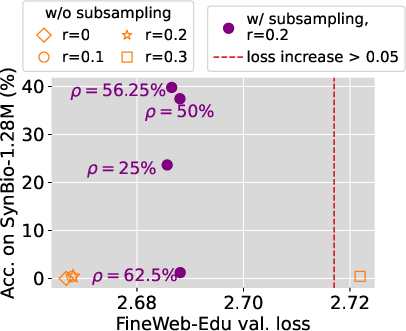
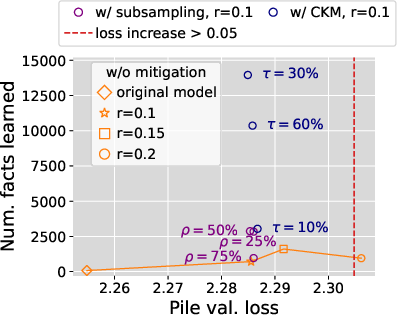
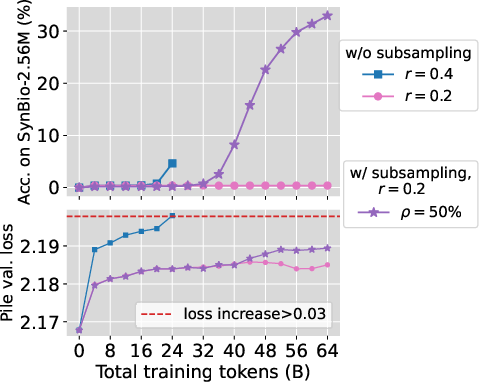
Figure 5: Our proposed strategies significantly boost knowledge acquisition under low mixing ratios while preserving models' general capability.
Conclusion
The paper "Data Mixing Can Induce Phase Transitions in Knowledge Acquisition" provides valuable insights into the training dynamics of LLMs when using mixed datasets. Phase transitions observed in model size and mixing ratios challenge the conventional understanding that larger models necessarily acquire more knowledge linearly. These findings highlight the importance of carefully configuring data mixtures to optimize LLM training and suggest that strategies like subsampling and compact knowledge mixing may offer substantial benefits. Future AI applications involving LLMs could leverage these insights to refine training methodologies, thereby enhancing model performance across various tasks.