- The paper introduces a cascaded generative pipeline combining audio compression, extraction, and correction to achieve superior target speech extraction.
- It leverages a variational autoencoder for effective compression and a latent diffusion model for accurate extraction, yielding high SI-SNR and DNSMOS scores.
- The results confirm robust generalization on both in-domain and real-world datasets, setting a new benchmark in audio processing.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
Introduction
Target Speech Extraction (TSE) is a sophisticated field of study aiming to isolate a desired speaker's voice amidst multiple speakers and background noise, leveraging speaker-specific cues. Traditional TSE methods, primarily employing discriminative models, often yield high perceptual quality but are susceptible to unwanted artifacts and environmental discrepancies. Generative models, while robust in unforeseen scenarios, historically lag in audio quality and intelligibility. The paper proposes SoloSpeech, a novel generative pipeline integrating compression, extraction, reconstruction, and correction processes, evaluated on the Libri2Mix dataset, setting a new standard for intelligibility and quality.
SoloSpeech Pipeline
SoloSpeech comprises three key components: a generative audio compressor, a generative target extractor, and a generative corrector.
The audio compressor employs a time-frequency domain variational autoencoder (VAE) to translate audio waveforms into latent representations, ensuring effective compression and reconstruction of speech signals (Figure 1).
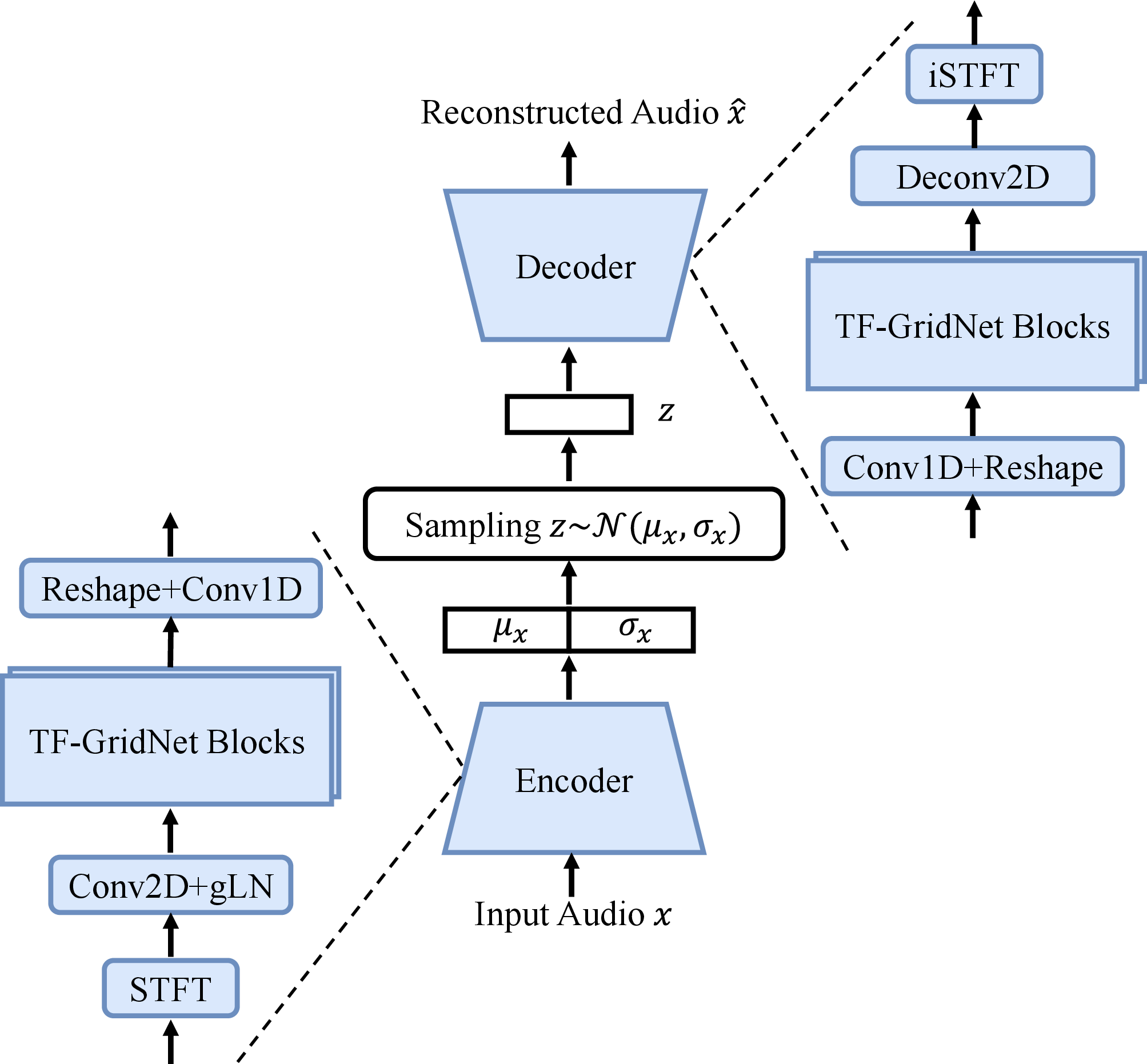
Figure 1: The audio compressor architecture.
The target extractor utilizes a latent diffusion model to predict the latent representation of the target signal. It operates without speaker embeddings, fusing the mixture and cue audio in a shared latent space using cross-attention mechanisms (Figure 2).
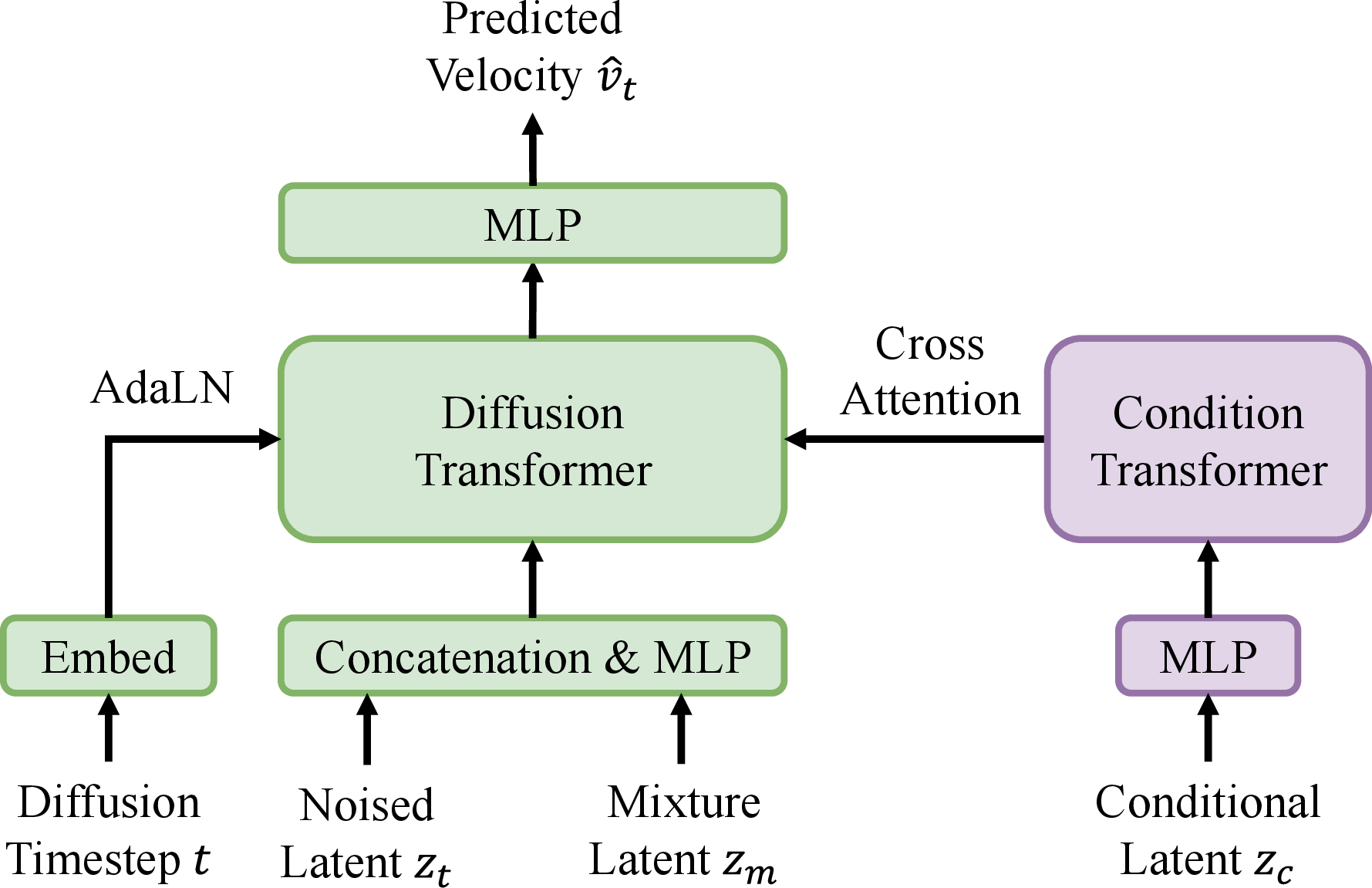
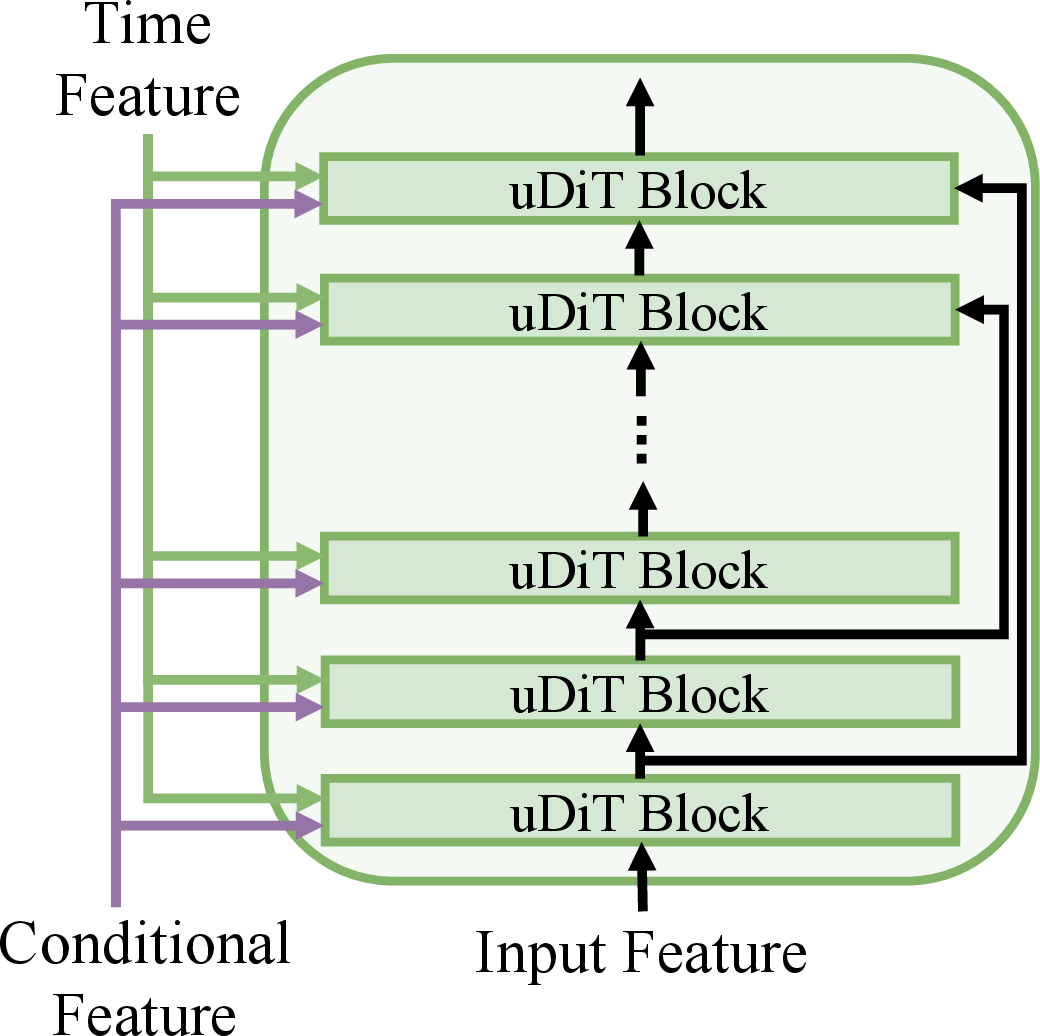
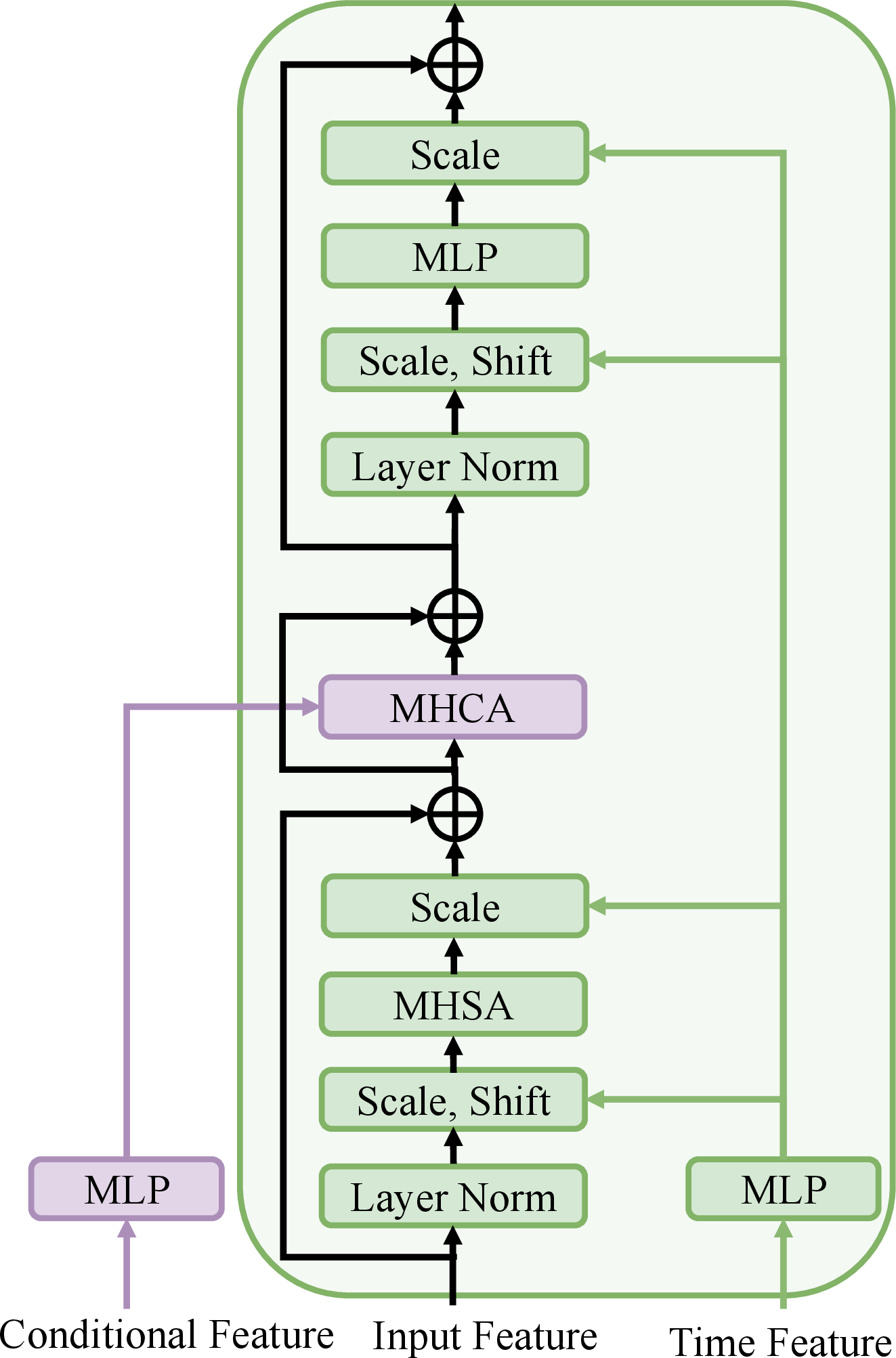
Figure 2: Architectures of the target extractor (a), Diffusion Transformer backbone (b) and uDiT block (c).
The corrector refines the extracted audio by addressing artifacts introduced by the target extractor. Inspired by recent advances in generative error correction models, SoloSpeech integrates conditional features effectively, significantly enhancing overall signal quality and intelligibility.
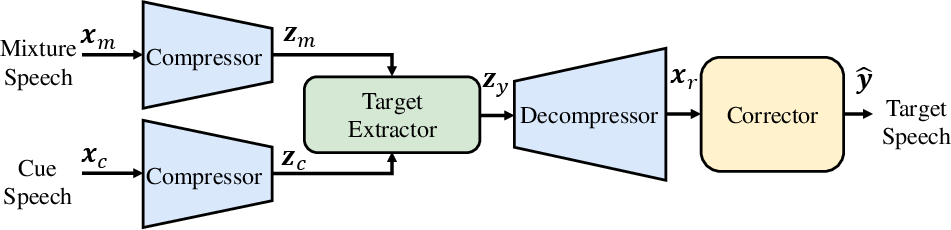
Figure 3: Overall pipeline of SoloSpeech.
Experimental Results
SoloSpeech was evaluated both on in-domain (Libri2Mix) and out-of-domain datasets, including real-world scenarios such as CHiME-5 and RealSEP. It consistently outperformed existing methods in terms of perceptual quality, naturalness, and intelligibility, evidenced by improved metrics such as PESQ, ESTOI, SI-SNR, and lower WER.
In-Domain Evaluation
On the Libri2Mix dataset, SoloSpeech surpassed conventional methods, yielding the highest SI-SNR and DNSMOS scores, indicative of superior audio clarity and speech naturalness. The pipeline demonstrated resilience in maintaining high intelligibility across various environmental conditions.
Out-of-Domain and Real-World Application
SoloSpeech exhibited robust generalization on out-of-domain data, significantly outperforming established methods in unseen conditions. Its application on real-world datasets demonstrated profound robustness to challenging acoustic scenarios, including expressive speech and moving sound sources.
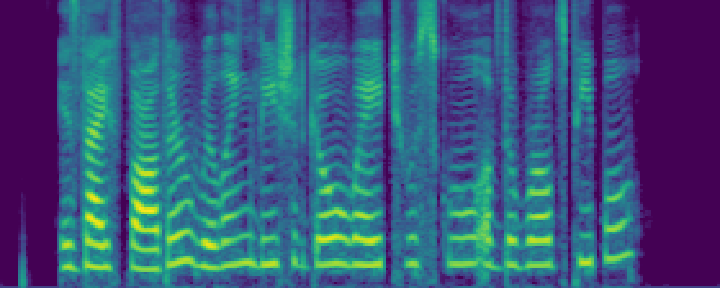
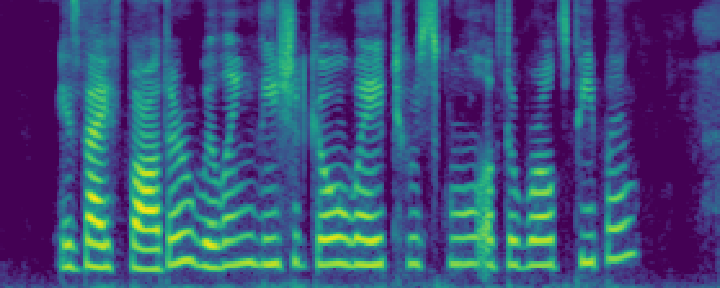
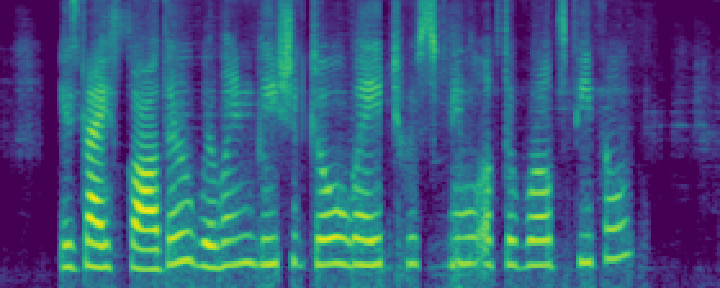
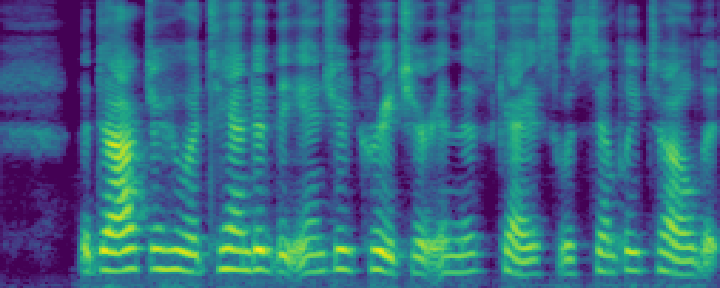
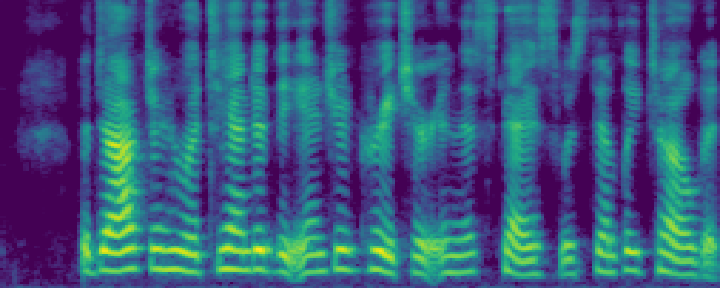
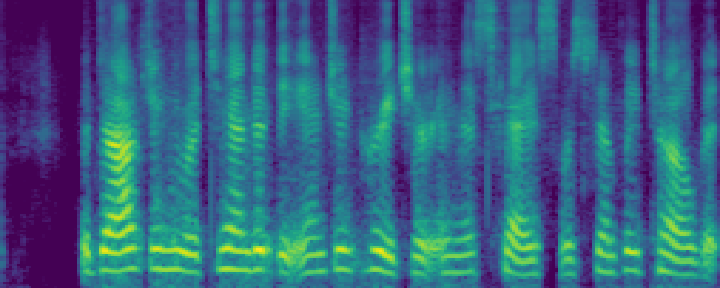
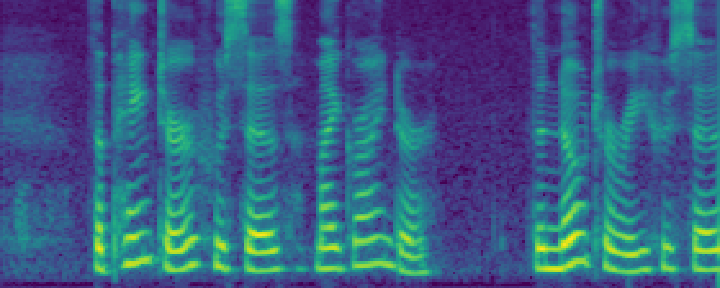
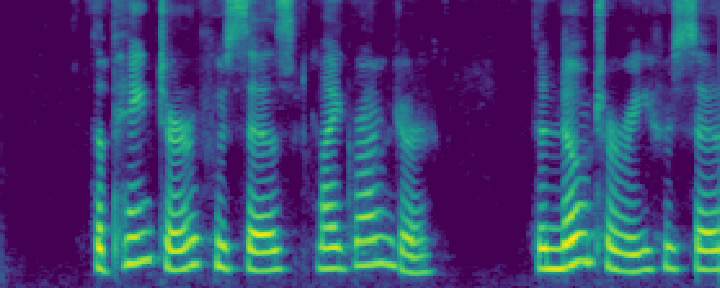
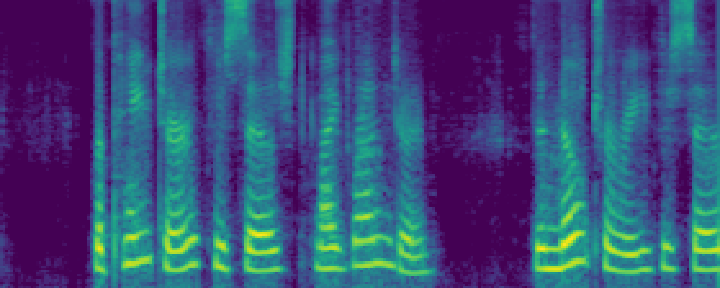
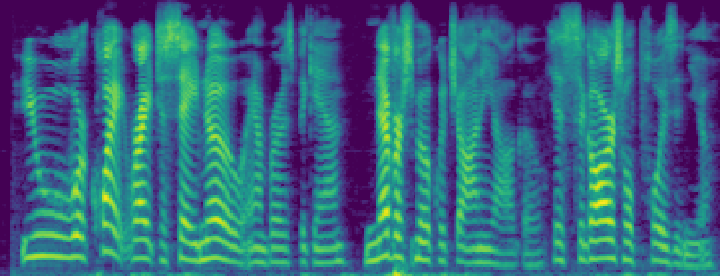
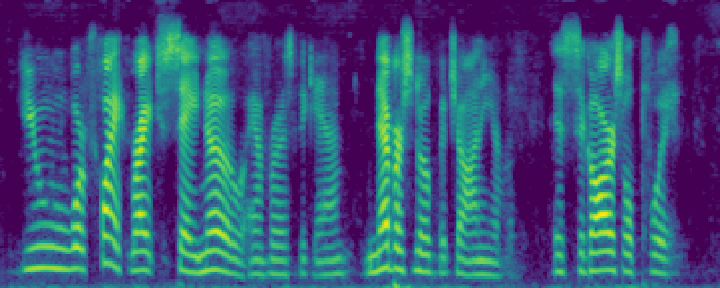
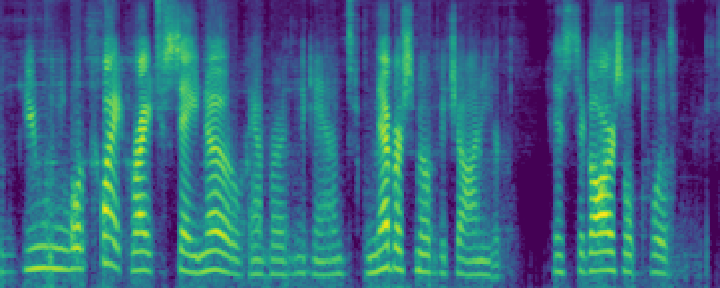
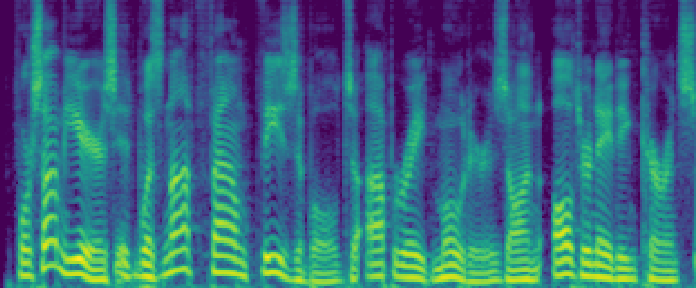
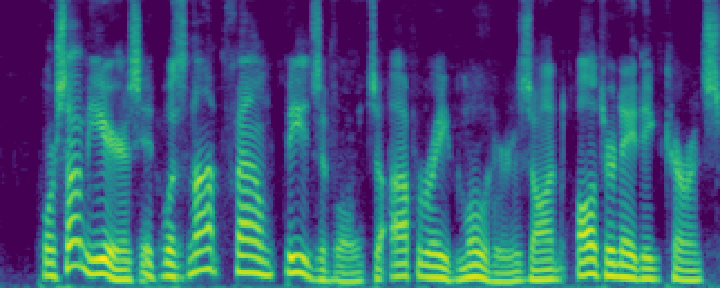
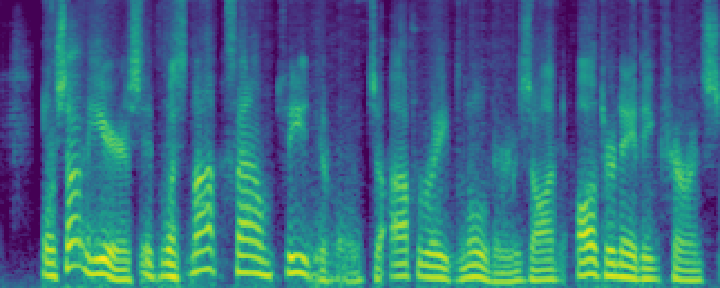
Figure 4: Comparison of the spectrograms of the ground truth, audio extracted by SoloSpeech, and by USEF-TSE. Rows: Sample I--V. Columns: (a,d,g,j,m) Ground truth, (b,e,h,k,n) audio extracted by SoloSpeech, (c,f,i,l,o) audio extracted by USEF-TSE.
Implications and Future Directions
SoloSpeech sets a new benchmark for generative models in TSE, combining high intelligibility and perceptual quality with robust generalization capabilities. The modular design of SoloSpeech components offers scalability, encouraging further exploration of generative architectures for audio processing tasks. Future research could focus on optimizing computational efficiency and addressing challenges in environments with significant reverberation and dynamic sound sources.
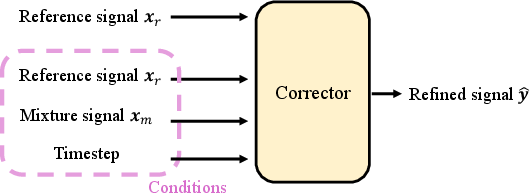
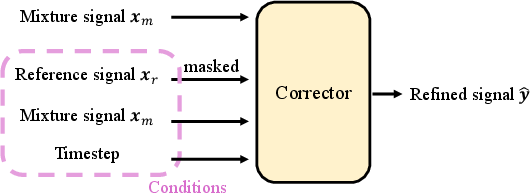
Figure 5: Diagrams of Fast-GeCo corrector (a) and SoloSpeech corrector (b).
Conclusion
SoloSpeech's cascaded generative pipeline marks a significant advancement in target speech extraction by combining high intelligibility and perceptual quality with robust generalization capabilities. Its strategic integration of compression, extraction, and correction components underscores the potential of generative models to surpass traditional discriminative approaches, paving the way for future innovations in AI-driven audio processing.