- The paper introduces an explicit style encoder and a style-controlled generator that conditions code generation on a 34-dimensional style vector.
- The methodology uses dual-modal contrastive learning, achieving a 1450% BLEU-4 improvement and superior ROUGE scores over baseline models.
- The framework enhances code maintainability and adherence to coding guidelines, though its current validation is limited to Python.
Style2Code: Dual-Modal Contrastive Learning for Style-Controllable Code Generation
Introduction and Motivation
Style2Code introduces a robust framework targeting the challenge of controllable code generation: producing source code that strictly adheres to user-specified stylistic patterns while preserving semantic correctness. The motivation stems from practical needs in professional software development, where stylistic consistency—spanning naming conventions, indentation schemes, structural layout, and formatting—directly impacts readability, maintainability, and collaborative efficiency. Existing methods, such as multi-model collaborative training or implicit style matching, increase deployment complexity and limit scalability. Style2Code circumvents these limitations through explicit style encoding and dual-modal contrastive learning, enabling fine-grained style conditioning within a single generative model.
Framework Architecture
The Style2Code framework operationalizes style control via a two-component architecture: (1) a Style Encoder that distills a 34-dimensional explicit style vector from reference code, and (2) a Style-Controlled Generator (built upon Flan-T5-Large) that synthesizes code conditioned on both source semantics and style embeddings.
Figure 1: Overall architecture of the Style2Code framework, highlighting the Style Encoder and Style-Controlled Generator.
The style vector captures features in three orthogonal dimensions:
- Naming conventions (14-dim): Statistical and categorical properties (e.g., snake_case ratio, digit usage, naming consistency).
- Spacing and layout (9-dim): Including whitespace, indentation depth, and comment density.
- Structural complexity (11-dim): Quantifying function call depth, branching, redundancy, and control-flow constructs.
The Style Encoder employs a four-layer MLP (with residual connections) to project these vectors to a 1024-dimensional latent space compatible with the generative backbone.
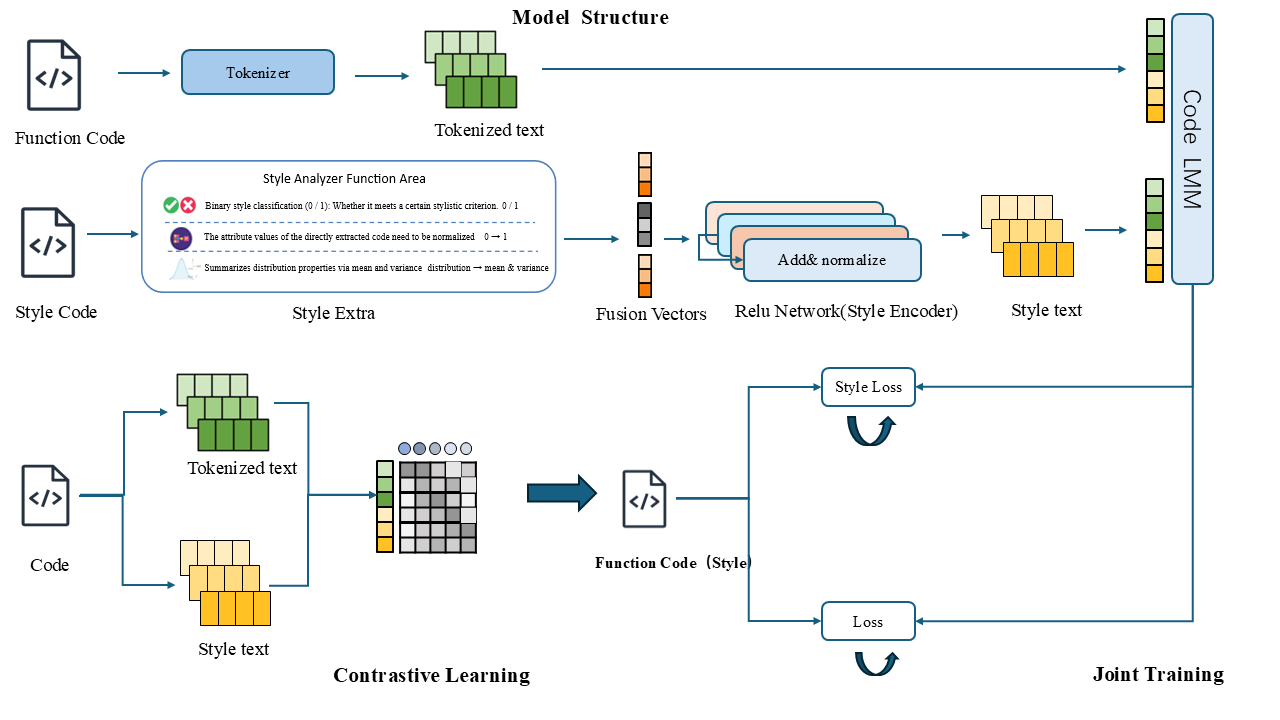
Figure 2: Architecture of the Style Encoder, projecting explicit style features to a high-dimensional latent space.
Training Procedure and Contrastive Objective
Style2Code utilizes a two-stage training paradigm. Initially, the Style Encoder is trained independently through self-supervised contrastive learning on style-differentiated code pairs. Positive pairs share style (from the same author or file), while negative pairs are drawn from distinct authors/files. InfoNCE loss facilitates clustering stylistically similar codes in the embedding space, enhancing discriminative power for style representation.
In the second stage, the full model (including the Style-Controlled Generator) is jointly fine-tuned. The decoding process is supervised not only for semantic accuracy (cross-entropy loss) but also for style fidelity (mean squared error between generated and target style vectors). This decoupled approach stabilizes training and promotes generalization across unseen styles.
Experimental Evaluation
Evaluation employs four metrics: BLEU-4 (token-level similarity), ROUGE (unigram, bigram, and sequence similarity), CSS (Code Style Similarity), and an AI-based evaluator simulating human judgment for style fidelity.
BLEU-4: Style2Code achieves a score of 0.317, exhibiting a marked 1450% improvement over the baseline Flan-T5 (0.020) and an 8.8% gain over DeepSeek (0.285). This underscores the efficacy of explicit style conditioning.
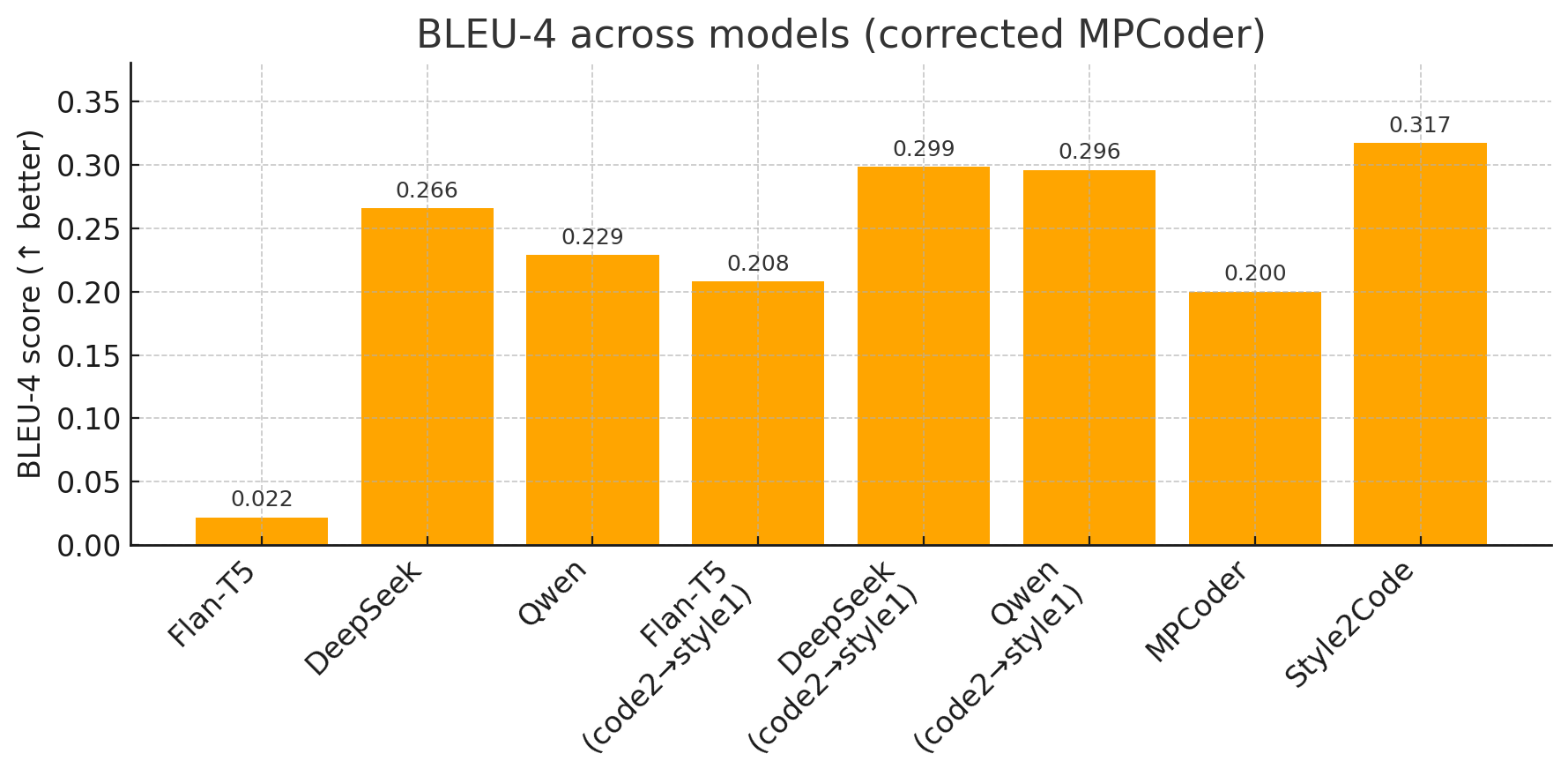
Figure 3: BLEU-4 performance comparison; Style2Code outperforms all competitors on n-gram similarity.
ROUGE: Style2Code leads across all ROUGE sub-metrics (ROUGE-1: 0.448, ROUGE-2: 0.167, ROUGE-L: 0.401), surpassing the strong SOTA reference MPCoder and all other baselines.
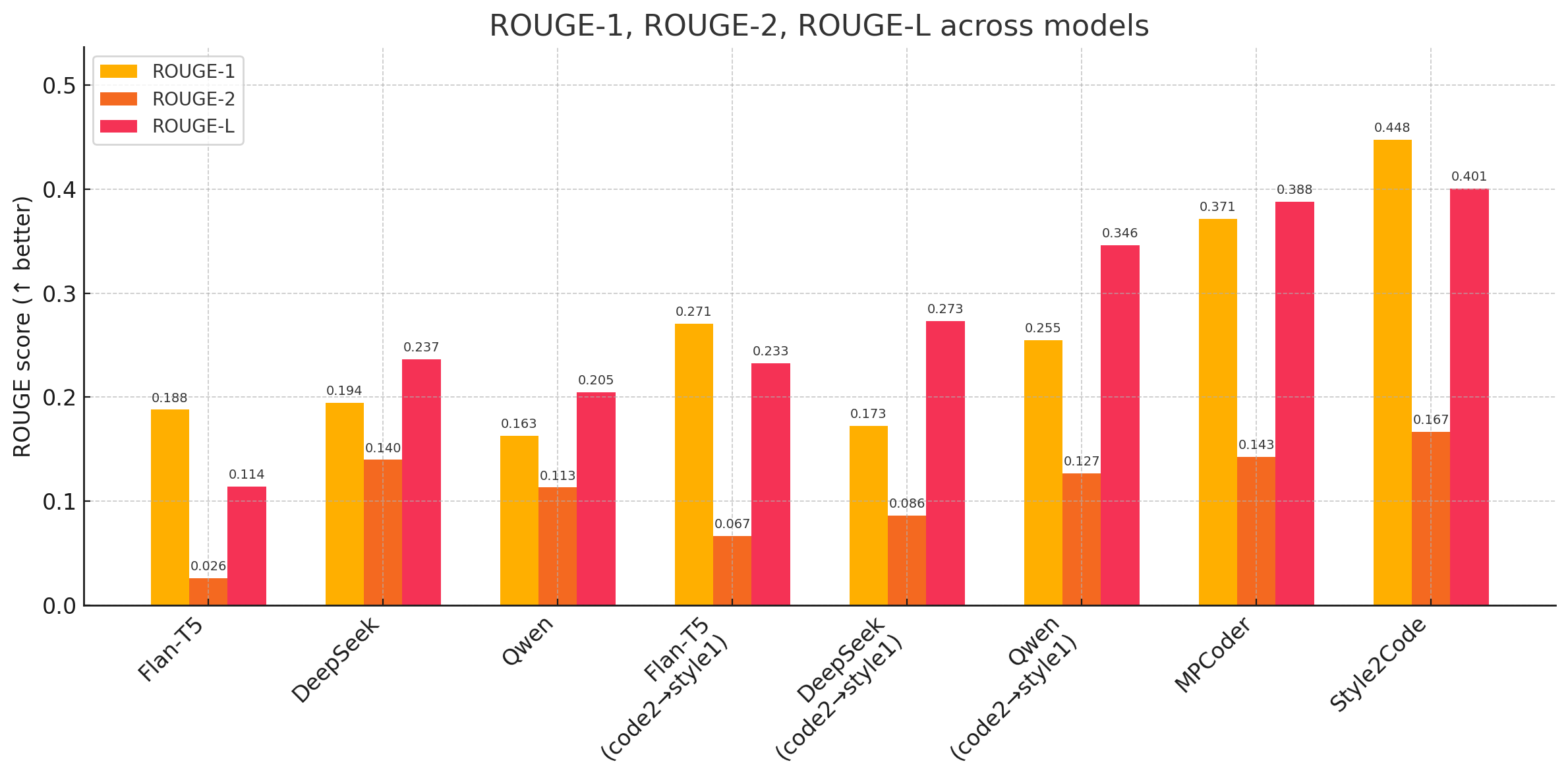
Figure 4: ROUGE metric comparison; Style2Code demonstrates superior sequence and phrase-level alignment.
CSS: With a CSS score of 0.196, Style2Code ranks third behind Qwen (0.222) and MPCoder (0.214), but provides a 96% improvement over Flan-T5, indicating substantial gains in explicit style matching while remaining competitive with implicit style-aware generators.
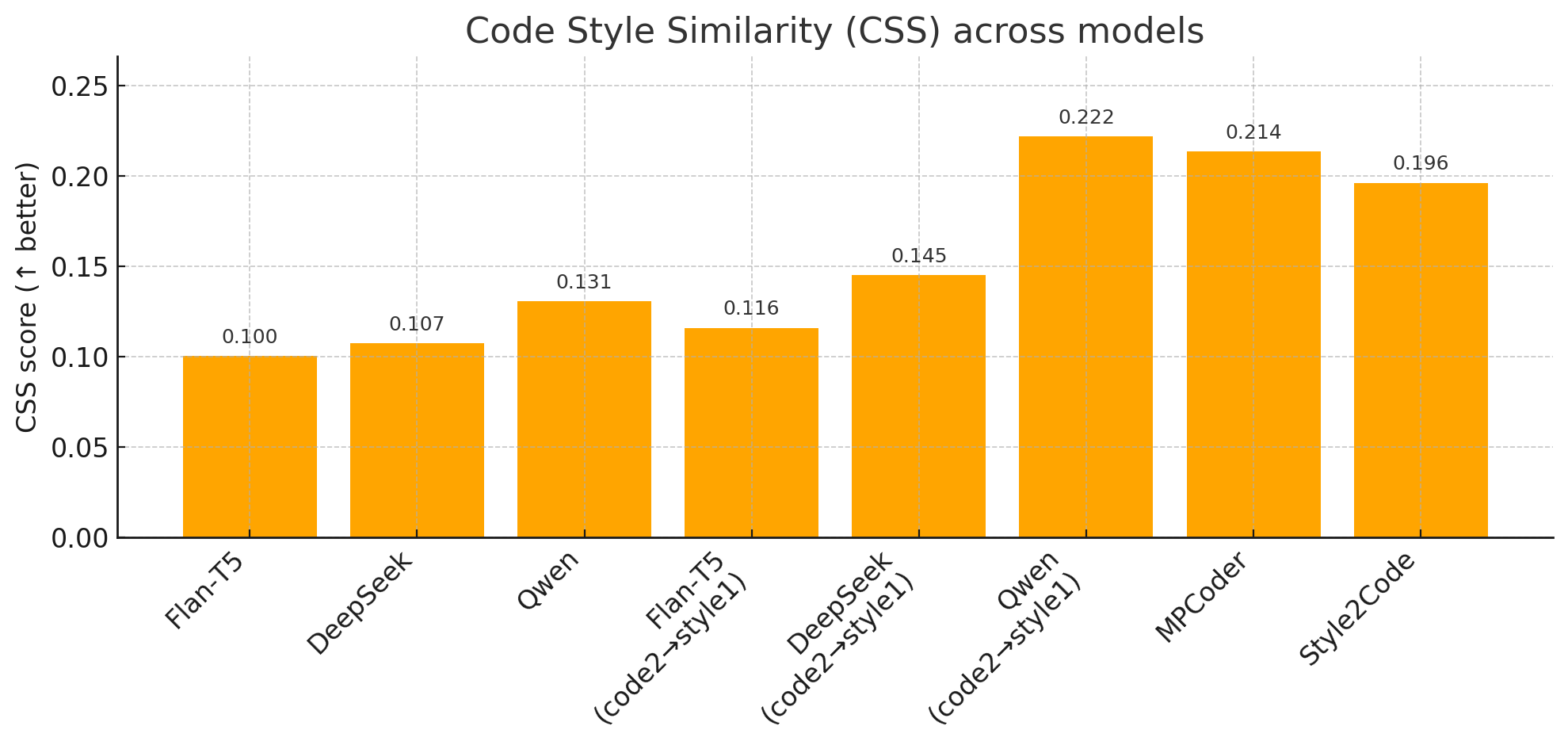
Figure 5: CSS score comparison; Style2Code achieves significant gains over baseline models in naming convention alignment.
AI-Based Evaluation: Style2Code scores 0.115, considerably higher than Flan-T5 (close to 0), ranking competitively among advanced models.
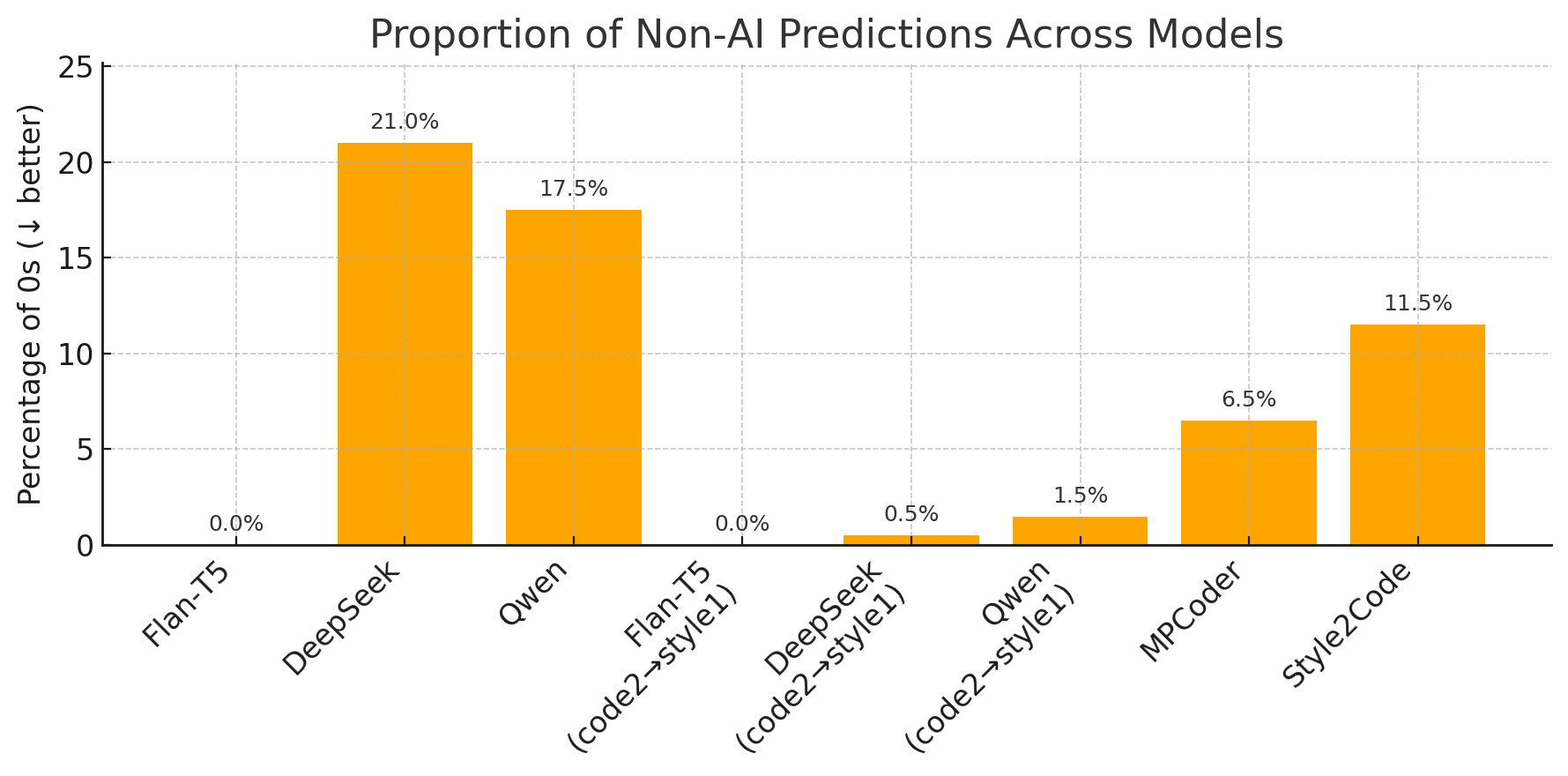
Figure 6: AI-based style evaluation; Style2Code demonstrates strong model-judged style fidelity.
Theoretical and Practical Implications
Style2Code advances modality-aware code generation by introducing explicit, interpretable style conditioning via vector embeddings. The contrastive learning stage abstracts style representation from semantic content, helping resolve cold-start and clustering issues prevalent in prior personalized code generators. As style is treated as a continuous, learnable modality, the framework moves towards generalizable dual-modal learning—promoting adaptation to individual or project-specific standards.
Practical implications include reduced code maintenance burden, improved integration with established coding guidelines (PEP8, Google Style Guide, etc.), and enhanced trustworthiness for human-in-the-loop programming assistants. The model's scalability (850M parameters) and ability to generalize across diverse style exemplars make it suitable for real-world deployment.
Limitations and Future Directions
Despite strengths, Style2Code's explicit style vector may not encapsulate deeper, implicit stylistic or architectural preferences. Reliance on SOTA code generation models for dataset construction introduces model bias. Current validation is limited to Python, necessitating cross-language extensions.
Future research trajectories involve: augmenting style representation with hybrid explicit-implicit features; expanding to polyglot codebases; enabling feedback-driven (interactive) style control during generation; and integrating style control with, e.g., readability and maintainability assurance.
Conclusion
Style2Code demonstrates a methodologically sound approach for explicit, user-controllable code style transfer via dual-modal contrastive learning. Quantitative evaluation affirms its superiority in token-level and style matching, competitive performance on structural metrics, and practical scalability. Its architectural and training innovations lay groundwork for multilingually personalized, modality-aware code synthesis—addressing a critical challenge in developer-facing AI systems. Further enhancements in implicit style modeling and language coverage remain key for broader impact.
(2505.19442)