- The paper introduces KnowTrace as a novel framework that restructures iterative retrieval by organizing external data into knowledge graphs for improved multi-hop reasoning.
- It employs a dual-phase strategy of knowledge exploration and completion, effectively reducing context overload and filtering non-contributive reasoning steps.
- Experimental results on benchmarks like HotpotQA and 2Wiki demonstrate that KnowTrace outperforms existing RAG systems in both accuracy and computational efficiency.
Introduction to "KnowTrace: Bootstrapping Iterative Retrieval-Augmented Generation with Structured Knowledge Tracing"
The paper "KnowTrace: Bootstrapping Iterative Retrieval-Augmented Generation with Structured Knowledge Tracing" explores retrieval-augmented generation (RAG) systems to enhance the efficacy of LLMs in handling complex multi-hop questions. By proposing the KnowTrace framework, the research addresses context overload and improves multi-step reasoning through structured knowledge tracing, leveraging knowledge graphs as intermediaries for information structuring and reasoning.
Iterative Retrieval-Augmented Generation
RAG systems empower LLMs by allowing them to fetch relevant external information iteratively, enabling effective multi-step reasoning. However, traditional RAG approaches suffer from context overload and non-contributive reasoning steps, which limit their efficiency. KnowTrace mitigates these challenges by restructuring the workflow to organize retrieved data into knowledge graphs (KGs) that are relevant to the input question, reducing cognitive load and highlighting critical information for LLM inference.
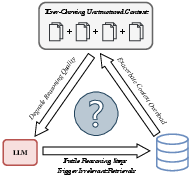
Figure 1: Two challenges of iterative RAG systems: ever-growing LLM context and non-contributive reasoning steps.
KnowTrace Framework Overview
The KnowTrace framework introduces a dual-phase process of knowledge exploration and completion. During the exploration phase, the system decides whether additional information is required or if the collected knowledge suffices for answering the question. If further retrieval is needed, it identifies key entities and relations as expansion points. The completion phase leverages these expansion points to retrieve specific bits of knowledge and update the current KG context.
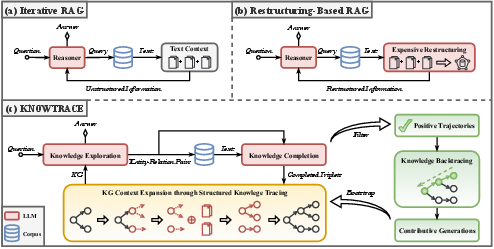
Figure 2: An overview of two representative workflows (a-b) and our KnowTrace framework (c).
Methodology
Structured Knowledge Tracing for Inference
KnowTrace advances current iterative RAG methods by embedding the knowledge triplets into KGs, using them as structured contexts for LLM reasoning. This framework adopts an adaptive approach to trace and expand KGs incrementally until the LLM can confidently generate a final prediction.
Knowledge Backtracing and Self-Training
This paper also introduces a novel knowledge backtracing mechanism, enabling the self-retraining of LLMs on high-quality examples derived from positive reasoning trajectories. By filtering out non-contributive components retrospectively, KnowTrace enhances the multi-step reasoning processes through proficient self-training, aligning LLM predictions with verified answers.
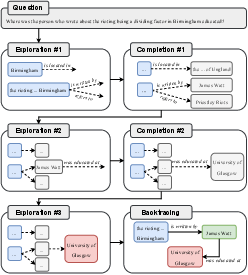
Figure 3: An example of KnowTrace's inference and backtracing process. The generated texts are included in Appendix \ref{app_case}.
Comparison and Results
Experimentation on diverse benchmarks—HotpotQA, 2Wiki, and MuSiQue—shows that KnowTrace surpasses existing methods in performance and efficiency. The framework effectively retains only crucial data for reasoning, improving answer accuracy without increasing processing burdens. Notably, under configurations with LLMs like LLaMA3-8B-Instruct and GPT-3.5-Turbo-Instruct, KnowTrace consistently outperforms others across multiple datasets.
Practical Implications
KnowTrace exhibits compatibility with various retrieval backends like BM25, DPR, and Contriever. Despite variations in datasets and retrieval strategies, the framework shows robust performance gains while managing computational overhead efficiently.
Conclusion
KnowTrace advances the field of RAG systems by offering a structured, KG-based approach to mitigate context overload and enhance reasoning through reflective knowledge backtracing. This synergy between structured knowledge tracing and effective self-bootstrapping presents a compelling path forward for complex multi-hop QA tasks. Future work could further explore its adaptability to other reasoning-centric domains, reinforcing its applicability beyond MHQA tasks.