- The paper presents an automated pipeline that collects, verifies, and evaluates software engineering tasks from diverse GitHub repositories.
- The methodology integrates LLM-driven installation configuration with execution-based verification to ensure task solvability and consistent evaluation.
- Benchmark results reveal model performance variabilities and contamination effects, guiding future improvements in LLM-based software engineering agents.
SWE-rebench: A Pipeline for Task Collection and Evaluation of SWE Agents
The development and evaluation of LLM-based agents for software engineering tasks face significant challenges, primarily due to limitations in high-quality, real-world interactive data. "SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents" introduces a scalable and fully automated system to continuously extract software engineering tasks from diverse GitHub repositories, aiming to address these issues.
Automated Pipeline Overview
The pipeline consists of four main stages designed to collect, verify, and evaluate tasks from GitHub repositories:
- Preliminary Task Collection: This stage leverages GitHub Archive and direct repository clones to gather detailed information about issues and linked pull requests. Filtering criteria target resolved issues with permissive licenses, focusing on repositories with primarily Python code.
- Automated Installation Instructions Configuration: Using agentless LLM-driven approaches, candidate environment setup instructions are generated and refined when errors occur. This method relies on extracting installation information from repository files.
- Execution-Based Installation Verification: Tasks are verified by executing tests to confirm their solvability. A distributed platform handles the computational load of verifying numerous task instances in isolated container environments.
- Automated Instance Quality Assessment: Utilizing fine-tuned LLMs, tasks are evaluated for issue clarity, complexity, and test correctness to support their use in reinforcement learning setups.
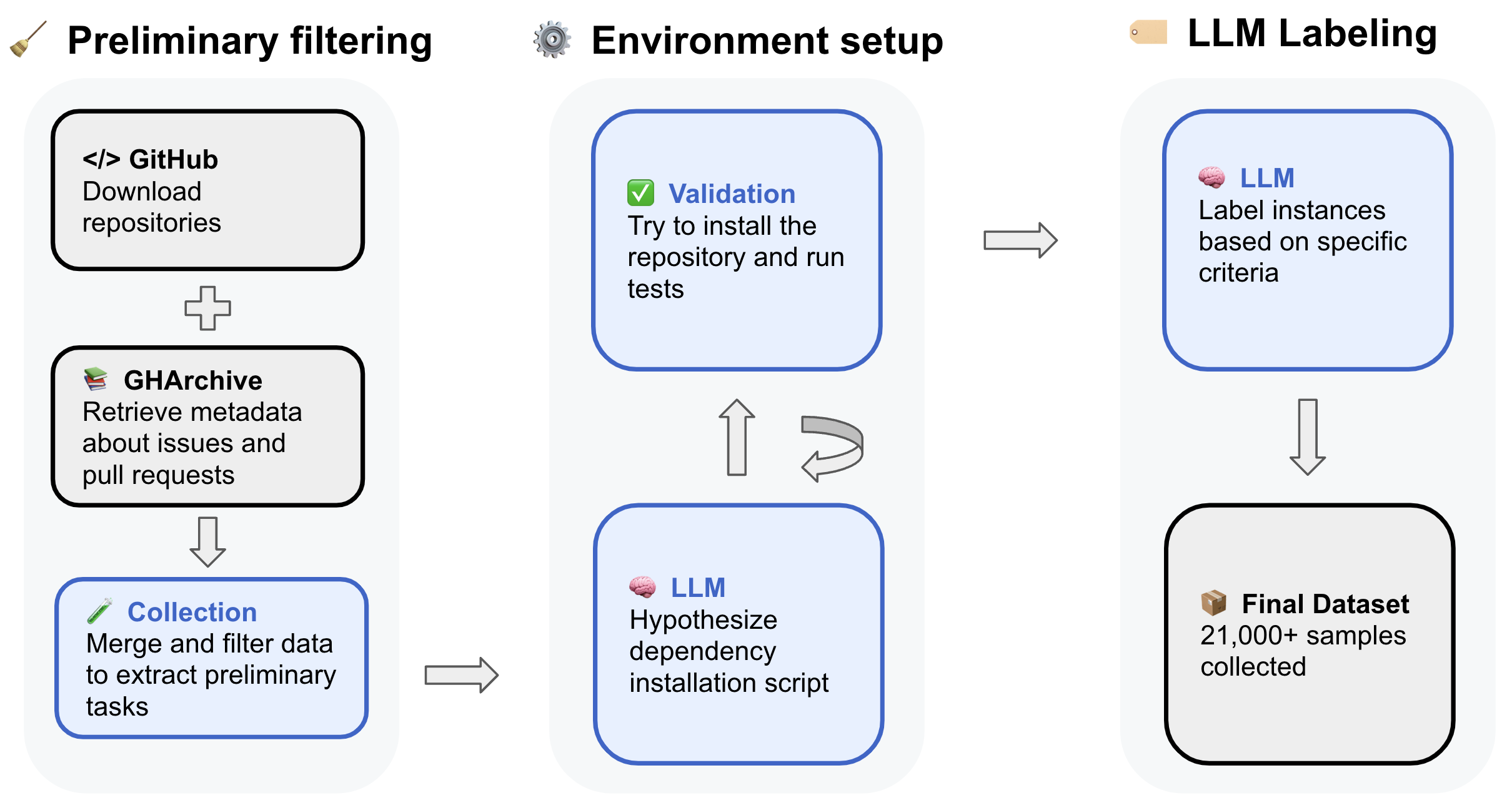
Figure 1: Overview of the automated pipeline for collecting software engineering data.
SWE-rebench Benchmark
The benchmark constructed using the pipeline aims to provide a standardized, contamination-free evaluation framework for LLM-based software engineering agents. It addresses key issues found in existing benchmarks, including potential data contamination and variability in evaluation methods.
Core Principles
- Standardized Evaluation Framework: All models are assessed using a consistent scaffolding and agentic framework. This ensures equal conditions and comparability across different models.
- Continuous Dataset Updates: The pipeline regularly provides fresh instances to keep the benchmark relevant and contamination-free. Transparent labeling marks potential data leakage where model release dates coincide with task creation dates.
- Accounting for Stochasticity: Multiple runs are conducted for each model to account for variability in performance. Metrics such as standard errors of mean are reported for robustness.
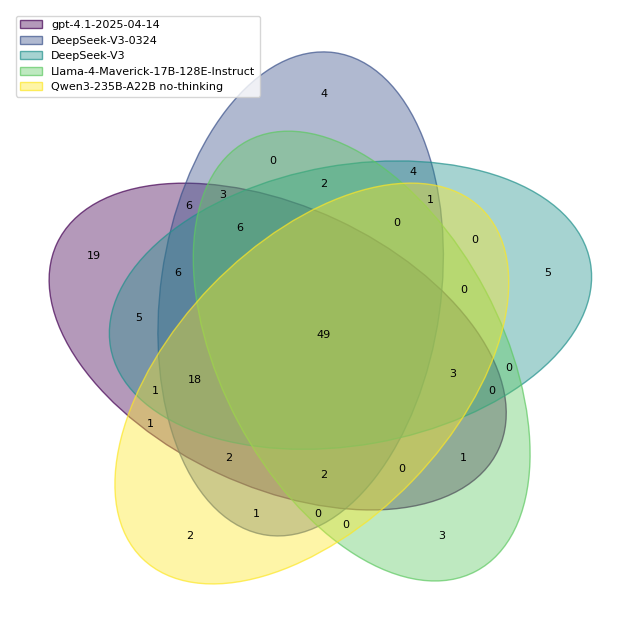
Figure 2: Overlap of solved tasks across selected models.
Result Analysis
Evaluations on SWE-rebench reveal performance trends and potential contamination effects seen in prior benchmarks. Key observations include:
- Improvements in pass@5 metrics highlight that models often solve complex tasks, albeit inconsistently across runs.
- Specific models outperform others due to their robustness to changes in task distribution, as demonstrated by the DeepSeek models.
This analysis provides insights into model strengths and weaknesses, facilitating refined development and evaluation methodologies.
Discussion and Limitations
Despite its advantages, the pipeline comes with inherent limitations:
- Automated Task Quality Assessment: While scalable, relying solely on automated assessments may include imperfect tasks.
- Language Exclusivity: Initial datasets focus on Python, necessitating extensions for other programming languages to enhance diversity.
By aligning scalable automation with rigorous benchmarking, SWE-rebench serves as a critical foundation for developing and evaluating next-generation LLM-based agents capable of addressing real-world software engineering challenges.
Conclusion
"SWE-rebench" offers a powerful resource to advance open-source research and enhance LLM-based agents' reliability. Future work should focus on broadening data collection methods, supporting additional languages, and refining the quality assessment pipeline. This approach will further stimulate progress in the field of AI in software engineering, enabling more sophisticated and capable agents.