- The paper demonstrates that SWE-RL significantly enhances LLM reasoning by training on extensive open-source software evolution data.
- The methodology uses a curated GitHub PR dataset with rule-based rewards and GRPO optimization, achieving a 41.0% solve rate for GitHub issues.
- The framework not only excels in domain-specific tasks but also improves generalization across diverse OOD challenges, highlighting its scalability.
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Introduction
The paper "SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution" presents SWE-RL, an innovative RL approach aimed at improving the reasoning capabilities of LLMs specifically for software engineering tasks. SWE-RL capitalizes on extensive open-source software evolution data, employing rule-based rewards to guide the enhancement of LLM reasoning abilities. Through the application of SWE-RL, the model, referred to as \ours[70], showcases significant performance improvements on SWE-bench Verified, achieving a 41.0% solve rate with medium-sized LLMs for real-world GitHub issue resolution.
SWE-RL Methodology
The SWE-RL framework is built upon a curated dataset of GitHub PRs, transforming this raw data into a seed RL dataset comprising issue descriptions, code context, and oracle patches (Figure 1).
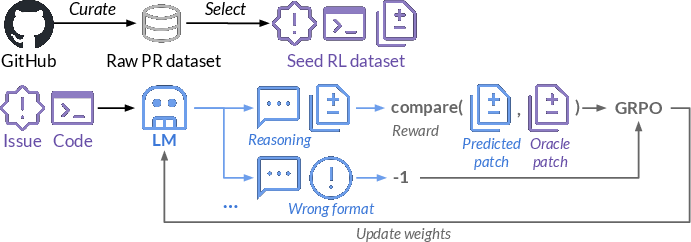
Figure 1: Overview of SWE-RL. We create a seed RL dataset from GitHub PR data, including issue descriptions, code context, and oracle patches.
The model applies a reward function that assigns negative penalties for incorrectly formatted responses and scales positive rewards based on the similarity between predicted and oracle patches. GRPO is utilized for policy optimization, aiding in refining the decision-making policies of LLMs during the iterative training process. The curated data undergoes thorough processing stages, including decontamination, prediction of relevant files, and filtration, to ensure the quality and relevancy of the training dataset (Figure 2).

Figure 2: Overview of SWE-RL's raw pull request data curation process.
Training and Evaluation
The training framework leverages GRPO, enhancing the LLM's ability to locate precise fault locations and generating effective repair suggestions (Equation 1). The approach contrasts with traditional SFT by focusing exclusively on RL strategies to improve model capabilities, avoiding reliance on large-scale, proprietary datasets.
To validate the model's effectiveness, SWE-RL demonstrates superior results not only within the task domain (SWE-bench Verified) but also across a spectrum of OOD contexts such as code reasoning, mathematics, and general language tasks. The emergent reasoning capabilities of \ours[70] reflect the adaptability and robustness of the RL-enhanced methodology, marking it as a state-of-the-art advancement for medium-sized LLMs in software engineering (Figure 3).

Figure 3: Reasoning skills emerged from \ours[70] following the application of SWE-RL.
Comparative Analysis
The research presents a comprehensive comparison of reward mechanisms and their impact on model performance - contrasting continuous with discrete reward functions. Results indicate the supremacy of continuous rewards in delivering nuanced feedback that is instrumental in refining LLM behavior, whereas discrete rewards fail to account for the diverse nature of patch matching in real-world applications (Figure 4).
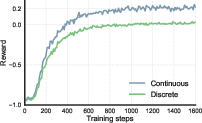
Figure 4: Ablation on SWE-RL's reward functions and their training dynamics.
Scaling and Generalization
The scaling analysis reveals that increasing the number of repair and test samples proportionally benefits model performance, indicating the scalability of the SWE-RL framework (Figure 5).
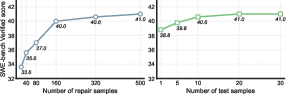
Figure 5: Scaling analysis with more repair samples and more reproduction tests.
Crucially, the generalization experiment asserts that training with SWE-RL extends the model's capabilities to OOD tasks, a feat the SFT baseline could not achieve as effectively. This capability is central to advancing the utility and versatility of LLMs across diverse domains (Figure 6).
Figure 6: Data packing design for midtraining.
Conclusion
SWE-RL introduces a strategic RL methodology that significantly enhances LLM reasoning capabilities by leveraging comprehensive software evolution data. The findings underscore the potential of RL in producing versatile, high-performance models with reduced dependence on large-scale proprietary datasets. Future research will aim to integrate agentic RL methodologies and explore execution interaction with repository environments to further augment the applicability of SWE-RL in real-world software engineering contexts.