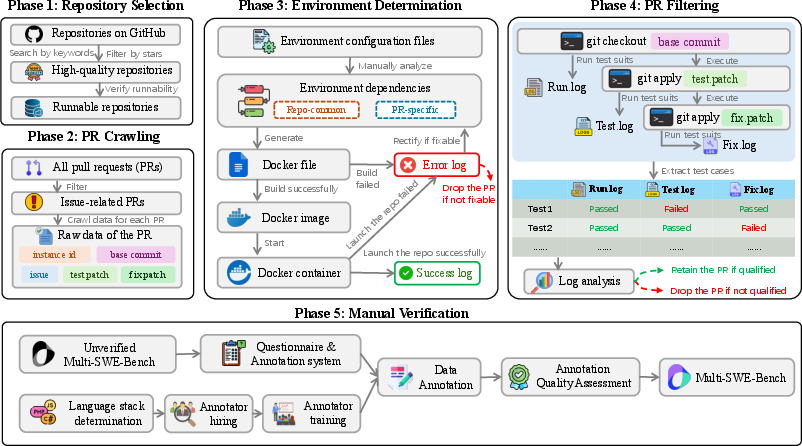
- The paper introduces a multilingual benchmark that evaluates LLMs on issue resolving using 1,632 expertly curated instances.
- It details a systematic pipeline from repository selection to manual verification, comparing methods like Agentless, SWE-agent, and OpenHands.
- The study highlights key factors such as issue type, description length, and patch characteristics that influence LLM performance.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Introduction
The paper "Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving" (2504.02605) addresses the challenge of evaluating LLMs on software engineering tasks, particularly issue resolving, across multiple programming languages. The current benchmarks, like SWE-bench, focus primarily on Python, limiting their effectiveness in assessing LLMs in diverse software ecosystems. Multi-SWE-bench expands this to include languages such as Java, TypeScript, JavaScript, Go, Rust, C, and C++, providing a comprehensive evaluation framework.
To build Multi-SWE-bench, the authors curated 1,632 high-quality instances from 2,456 candidates, annotated by 68 expert annotators. The benchmark is designed to evaluate state-of-the-art LLMs using varied methods like Agentless, SWE-agent, and OpenHands, with a focus on generalizability across languages. Additionally, the paper introduces the Multi-SWE-RL community for creating large-scale reinforcement learning datasets aimed at enhancing issue resolving capabilities.
Benchmark Construction
The construction of Multi-SWE-bench involves a systematic pipeline comprising five phases, from repository selection to manual verification.
Evaluation and Results
The evaluation of Multi-SWE-bench involved testing nine LLMs across three methods, offering insights into their language-specific performance, methodological effectiveness, and repository characteristics.
- Language-Specific Performance: While Python issues were resolved effectively, other languages posed challenges due to their unique paradigms and complexities.
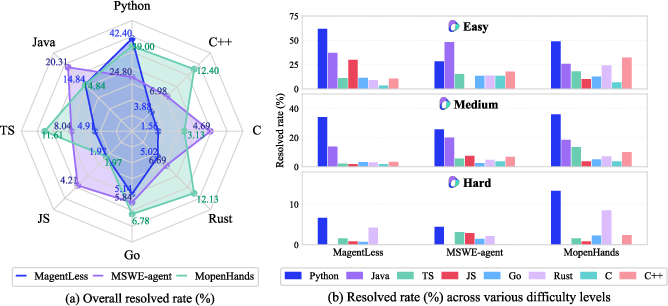
Figure 2: Resolved rate (\%) on Multi-SWE-bench (Claude-3.5-Sonnet).
- Methodological Comparison: MopenHands generally outperformed MagentLess and MSWE-agent, highlighting the benefits of flexible workflows.
- Repository Characteristics: Higher resolved rates correlated with metrics indicating repository activity and engagement, such as stars and forks.
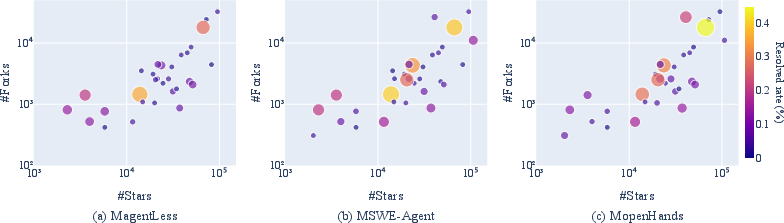
Figure 3: Relationship between resolved rate and the number of stars and forks of a repository.
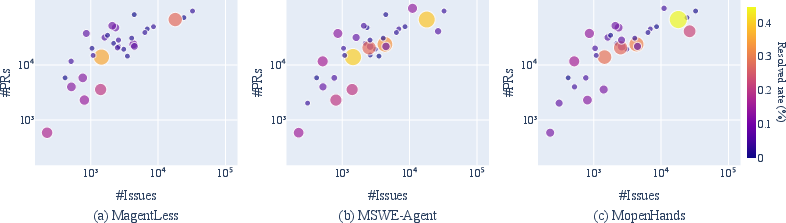
Figure 4: Relationship between resolved rate and the number of issues and PRs of a repository.
Influencing Factors
The paper identifies several factors influencing the resolving performance:
- Issue Type: Bug fixes were addressed more effectively than new features or optimizations, underscoring LLMs' limitations in handling semantically complex tasks.
- Description Length: The length of issue descriptions impacted performance variably, depending on whether descriptions were detailed or indicative of complexity.
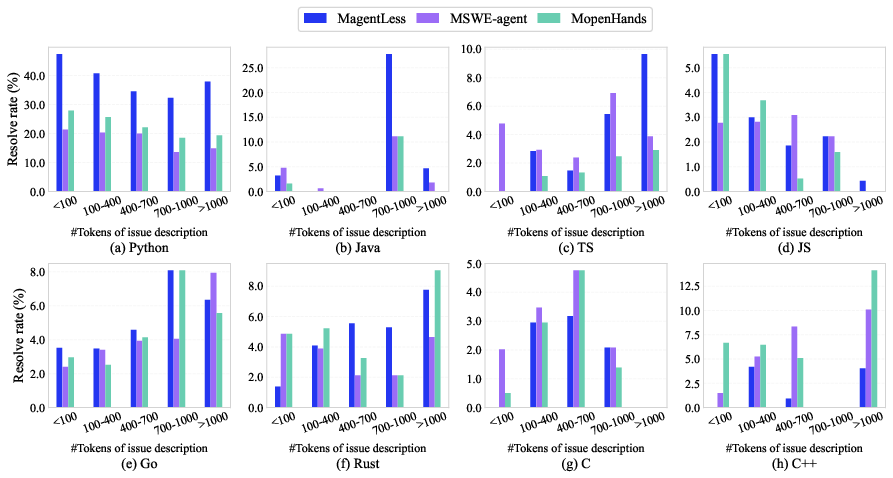
Figure 5: Influence of issue description length on resolved rate.
- Fix Patch Characteristics: Longer patches or those involving multiple files proved more challenging for existing methodologies.
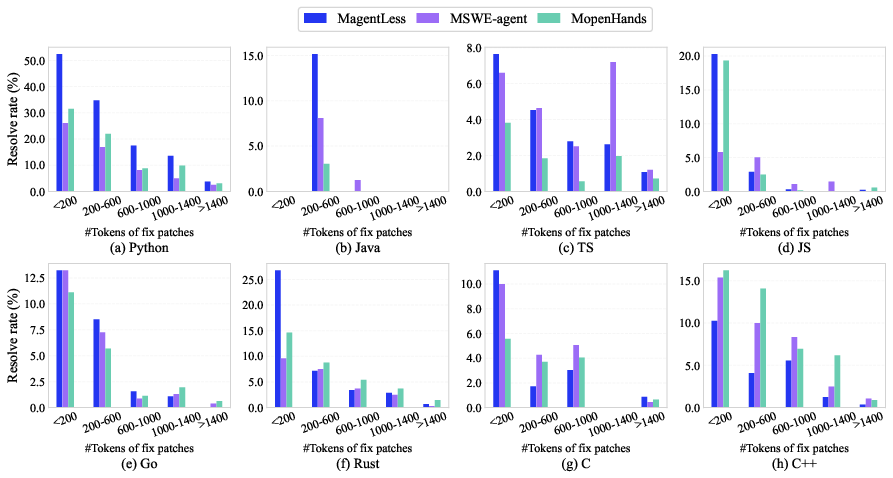
Figure 6: Influence of fix patch length on resolved rate.
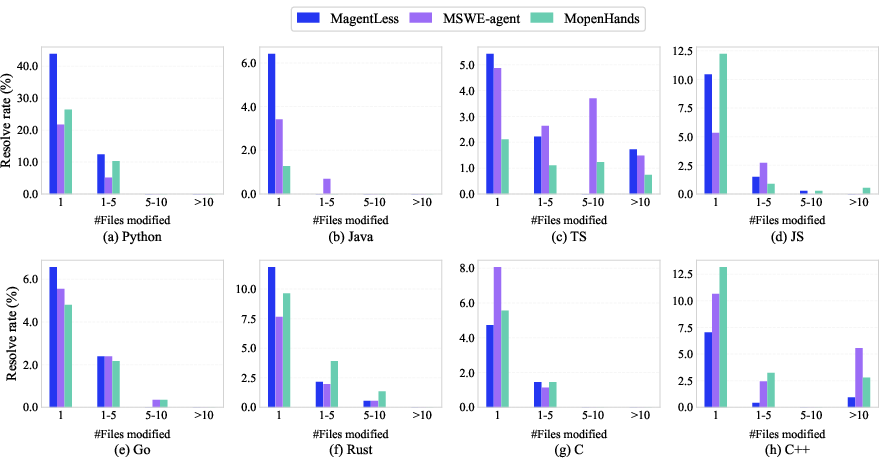
Figure 7: Influence of the number of files modified by fix patches on resolved rate.
The Multi-SWE-RL community is established to foster collaborative contributions and expand the dataset for scalable RL environments. The initial release includes containerized instances across multiple languages, encouraging community involvement in enhancing data quality and breadth.
Conclusion
Multi-SWE-bench and the associated initiatives provide a robust framework for evaluating LLMs in multilingual issue resolving scenarios. The study emphasizes extending benchmarks to cover diverse languages and tasks, advocating for scalable RL environments. Future works may incorporate broader software engineering challenges, setting the stage for holistic AGI advancements.