- The paper presents a process-oriented error analysis of AI-driven software development agents during real-world GitHub issue resolution.
- The study employs detailed logging from 500 GitHub issues across 12 Python repositories to identify recurring errors such as ModuleNotFoundError and TypeError.
- The findings suggest proactive measures, including dependency checks and static analysis, to enhance agents’ error-handling capabilities in dynamic software engineering tasks.
"Beyond Final Code: A Process-Oriented Error Analysis of Software Development Agents in Real-World GitHub Scenarios" (2503.12374)
Overview
The paper focuses on analyzing errors encountered by AI-driven software development agents, particularly those that employ LLMs, during real-world GitHub issue resolution tasks. It emphasizes understanding dynamic problem-solving processes rather than simply evaluating the final code outputs, thus providing a deeper insight into the agents' abilities and limitations in practical software engineering scenarios.
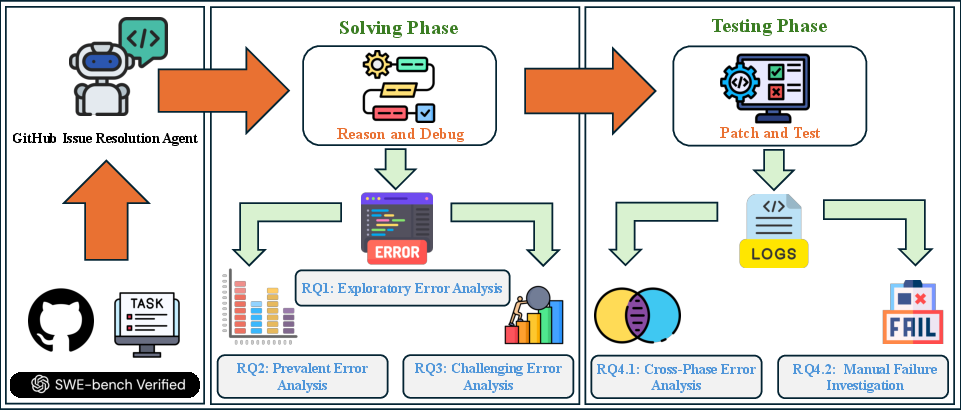
Figure 1: Study overview: solving-phase trajectories inform analyses of unexpected-error impact (RQ1), common-error prevalence (RQ2), and challenging-error identification (RQ3); testing-phase logs reveal testing errors and failures (RQ4).
Study Design
The study utilizes data from SWE-Bench Verified, which comprises 500 GitHub issues across 12 Python repositories. These issues were validated by professional engineers, ensuring the benchmark's effectiveness in representing real-world challenges. Eight agents are selected based on their capability to capture detailed execution outputs, observation delineation, and unmodified contents. This detailed logging enables in-depth error analysis over resolving phases.
Exploratory Error Analysis
The paper begins with a comprehensive exploratory analysis of execution errors during the solving phase. It demonstrates that Python execution failures correlate with increased reasoning steps and lower resolution rates. Errors like ModuleNotFoundError, TypeError, and AttributeError are identified as prevalent, highlighting dependencies and type management as significant challenges.
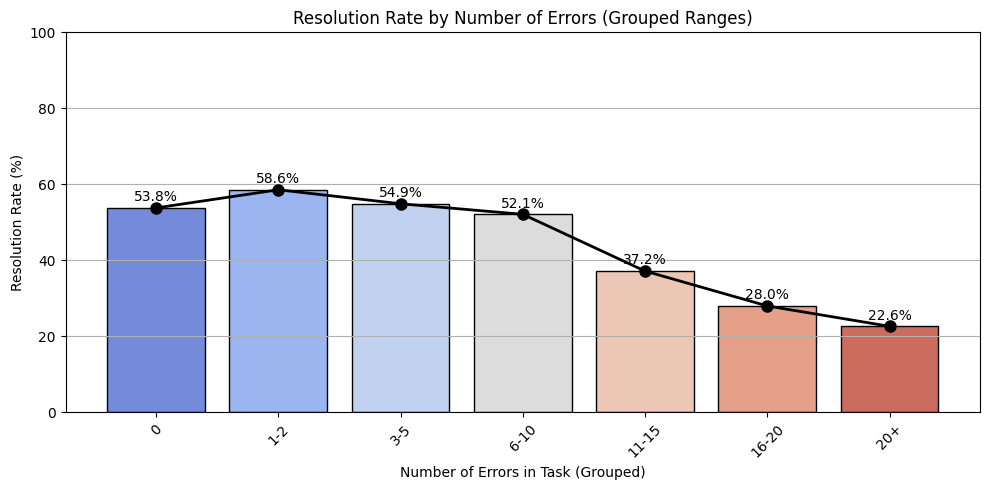
Figure 2: Resolution Rate by Error Frequency
Prevalent and Challenging Errors
The analysis identifies prevalent error types and categorizes them into Python built-in errors and custom-defined exceptions. Errors such as ModuleNotFoundError and TypeError are frequent, underscoring dependency and type-checking issues. Challenging errors, which recur during a task, are analyzed to understand their impact. Errors like OSError exhibit high recurrence ratios, indicating difficulties in resolving them due to system operation challenges.
Testing Phase and Cross-Phase Errors
Testing phase analysis reveals that unresolved tasks primarily stem from Python execution failures. The paper identifies cross-phase errors—errors that persist from the solving phase to testing—highlighting stealthy errors like TypeError as persistent challenges. Additionally, manual investigation reveals failures not explicitly linked to Python errors, pointing to potential issues in the evaluation platform.
Implications and Future Work
The research suggests various directions for future work, such as:
- Developing error-prone benchmarks that focus on scenarios like database integrity and dependency challenges.
- Enhancing agents' workflows with proactive error avoidance measures, like early dependency checks and static analysis tools.
- Integrating retrieval-augmented generation approaches to improve error detection and recovery mechanisms.
- Encouraging greener AI-driven software development by quantifying and optimizing energy costs of prolonged error resolution phases.
- Cross-benchmark exploration to validate findings across diverse tasks beyond GitHub issue resolution.
Conclusion
The paper provides a process-oriented error analysis that reveals current challenges faced by software development agents and offers insights into improving their error-handling capabilities. By highlighting recurring errors and proposing proactive solutions, it aims to enhance agents' performance, reduce computational overhead, and promote sustainable software development practices. The study also identifies three bugs in the SWE-Bench platform, further underscoring the need for reliable and accurate evaluation frameworks.