- The paper introduces SWE-Synth, a framework that synthesizes verifiable bug-fix data to enhance LLM-driven automated program repair.
- It employs an LLM-based reimplementation process with automated test-case filtration to generate realistic bug-fix pairs with intermediate repair traces.
- Empirical results show a 2.3% accuracy improvement over traditional datasets, indicating significant scalability and efficacy in real-world debugging tasks.
Synthesis of Verifiable Bug-Fix Data for Enhancing LLM APR Capabilities
The paper discusses SWE-Synth, a proposed framework designed to synthesize realistic and verifiable bug-fix data aimed at advancing the performance of LLMs in Automated Program Repair (APR). The framework introduces a scalable approach, leveraging LLM agents for debugging workflows, thereby enabling the generation of extensive, process-aware datasets. The synthesized data enhances the training of LLMs, improving the effectiveness in localizing bugs, generating patches, and validating fixes, all while maintaining rich contextual fidelity and correctness.
Introduction to SWE-Synth
The motivation behind SWE-Synth stems from the gaps in current APR datasets. Many existing datasets, derived from open-source repositories, lack the intermediate reasoning traces and test-case verifiability, which are crucial for training efficient LLM-driven APR systems. SWE-Synth addresses these gaps by offering a scalable mechanism that simulates realistic debugging processes. Through LLM agents, SWE-Synth generates both bug-fix pairs and comprehensive test logs that facilitate robust training environments. This approach allows for the efficient scaling of dataset creation with minimal human intervention, thus enabling open-source models to close the performance gap with commercial alternatives.
Methodology and Framework Components
SWE-Synth's framework is centered on three critical phases: component selection, reimplementation via LLMs, and test-case-based variant filtration. The component selection utilizes a coverage-based strategy to identify key areas within codebases that are integral to the program's functionality. This strategy ensures that the synthesized bugs are realistic and representative of typical developer errors.
A key novelty in this work is the LLM-based reimplementation process, where selected components are masked and re-implemented by LLMs, creating diverse program variants. These variants are then subjected to automated testing; only those that fail certain test cases are retained, thus ensuring their verifiability. This methodology ensures not only the generation of human-like bugs but also the inclusion of intermediate repair traces, which are invaluable for training models to learn iterative reasoning processes (Figure 1).

Figure 1: Illustrating Example of LLM-Generated Code
Empirical Results and Evaluation
The experiments conducted exhibit the robustness of SWE-Synth. Models trained on the synthesized dataset outperformed those trained on real-world datasets from SWE-Bench Lite by exhibiting a 2.3% higher accuracy in bug fixing tasks. These results underscore the framework's ability to generate useful training data that can not only rival but in some cases surpass traditional datasets in bringing about performance improvements.
Moreover, the study included human assessments, where synthetic bugs were challenging to distinguish from real ones, further validating the realism incorporated into synthesized datasets. The framework's scaling capability significantly enhances the efficiency of generating extensive data, facilitating its use in varied programming environments and by diverse LLM architectures.
Implications and Future Directions
The introduction of SWE-Synth marks a considerable step towards establishing high-quality training datasets for open model LLMs in APR. Its ability to synthesize realistic and verifiable data paves the way for further research and development in APR technologies, potentially leading to more autonomous systems capable of tackling complex software maintenance tasks. The framework highlights the strategic importance of integrating automated data generation mechanisms in developing scalable research methodologies.
Looking forward, SWE-Synth's framework could be expanded to include more programming languages and applied to other domains such as security vulnerability detection and domain-specific software maintenance. Future research might involve exploring adaptive synthesis techniques that cater to specific programming paradigms or incorporating adversarial bug creation to further stress test APR models.
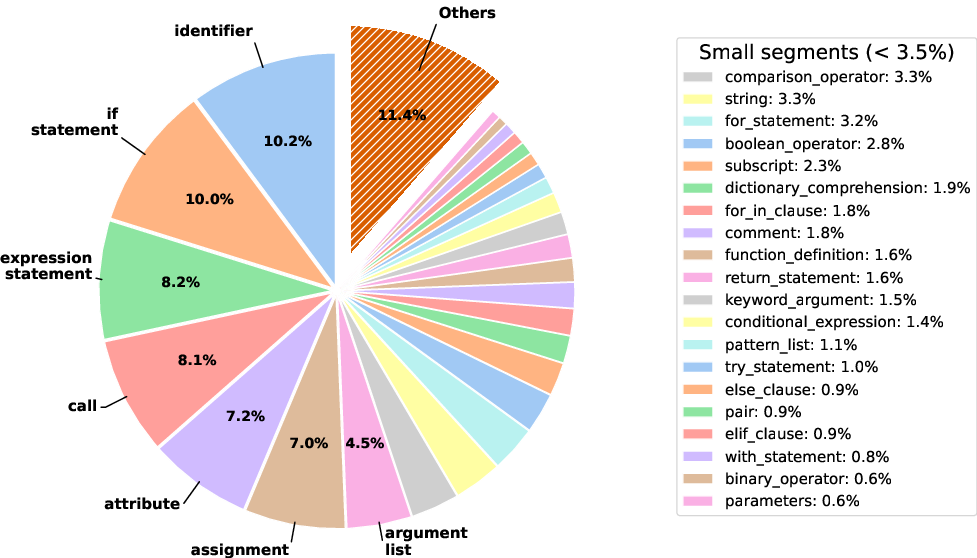
Figure 2: Diversity of Fixing Locations in SWE-Synth
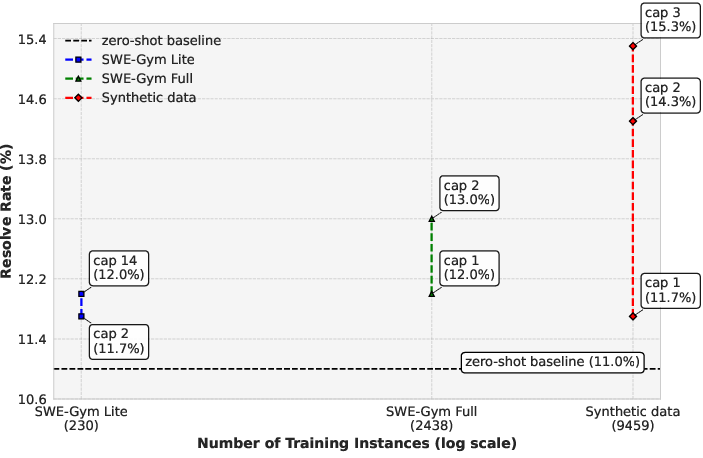
Figure 3: APR performance of models trained on synthetic vs real-world bugs evaluated on SWE-Bench Lite logs, fine-tuned in Moatless settings with Qwen2.5-Coder-14B Instruct (RQ2)
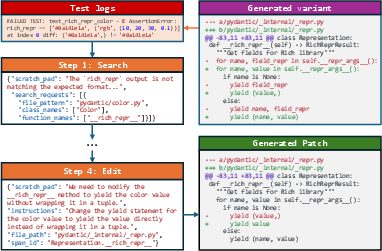
Figure 4: A generated fix with intermediate steps
Conclusion
By addressing core bottlenecks in dataset availability and verifiability, SWE-Synth provides a sophisticated tool for enhancing the training and evaluation of LLM-driven APR systems. The empirical evidence demonstrates its effectiveness, making it a promising foundation for further advancements in the automation of software engineering tasks.
