- The paper presents a multi-agent framework that splits reasoning across three specialized agents, enhancing interpretability and accuracy.
- The methodology extracts modality-specific insights, synthesizes cross-modal information, and aggregates coherent responses via dedicated agents.
- Experimental results outperform existing baselines on MMQA benchmarks, demonstrating robust performance even under input perturbations.
The paper explores a novel architecture for multimodal question answering (MMQA) by introducing a multi-agent framework, facilitating enhanced interpretability and accuracy. This approach addresses the limitations of current models that utilize a singular reasoning strategy, which often neglects the unique characteristics and semantics of individual modalities, resulting in decreased efficacy and interpretability.
Introduction to the Multi-Agent Framework
The research introduces a framework consisting of three distinct agents: a Modality Expert, a Cross-Modal Synthesis Agent, and an Aggregator Agent. Each agent is designed to specialize in handling specific aspects of the multimodal data, thus allowing for a more structured and transparent approach to question answering.
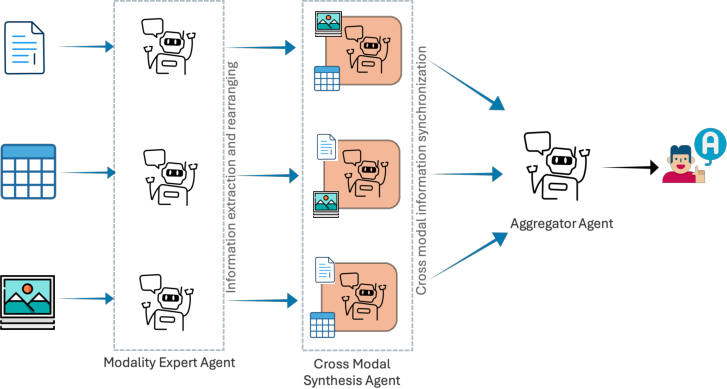
Figure 1: The architecture of the proposed framework, featuring three types of agents responsible for modality-specific insight extraction, cross-modal synchronization, and grounding the final answer.
Modality Expert Agent
The Modality Expert agent operates at the initial stage, tasked with extracting modality-specific insights without delivering any answers itself. This is essential for identifying and preserving the unique structures within text, tables, or images that are crucial for accurate interpretation.

Figure 2: Modality Expert Agent Prompt.
Cross-Modal Synthesis Agent
Following the extraction phase, the Cross-Modal Synthesis Agent synthesizes information across the various modalities. This agent integrates insights with a focus on a primary modality, ensuring consistency and reducing errors that arise from ambiguous inputs.

Figure 3: Cross Modality Agent Prompt.
Aggregator Agent
Finally, the Aggregator Agent consolidates the synthesized information to produce a cohesive and justified answer. This stage emphasizes evidence-grounded reasoning, assisting in delivering transparent and verifiable conclusions.

Figure 4: Aggregator Prompt.
Experimental Evaluation
The framework's performance was rigorously tested on MMQA benchmark datasets like MultiModalQA and ManyModalQA.
Results
Quantitatively, the framework surpassed existing baselines such as CoT, CapCoT, and ToT across various settings, notably achieving significant gains in robustness and accuracy, especially in cross-modal tasks where integration of multimodal data is crucial.
(Tables are referenced here for quantitative results presented in the full paper.)
Robustness
Beyond performance, the architecture demonstrated robustness under various perturbations, showcasing resilience against potential input inconsistencies and irrelevant information. The system's modular design facilitated adaptability and stability, marking a significant improvement over monolithic models.
Practical Implications and Future Directions
Implementation of this framework in real-world applications suggests enhanced accuracy and interpretability in areas like scientific research, business analytics, and educational tools. The multi-agent system allows explicit tracing of reasoning steps, which is critical for applications requiring high confidence and verifiable results.
Moving forward, further research may explore extending the framework beyond text, tables, and images to include audio and video modalities. Additionally, optimizing inference latency and resource consumption will be crucial for broader applications, particularly in environments with resource constraints.
Conclusion
The presented multi-agent framework signifies a promising advancement in multimodal question answering, providing a structured, transparent, and high-performing alternative to existing methodologies. By compartmentalizing the reasoning process and capitalizing on modality-specific strengths, it lays the groundwork for future innovations that prioritize interpretability alongside performance.