- The paper introduces MEXA, a novel training-free framework that dynamically selects and aggregates pre-trained experts for scalable multimodal reasoning.
- It leverages a multimodal LLM router to choose modality-specific experts and uses a long-context reasoning model to integrate outputs for precise answers.
- Experimental results demonstrate superior performance with accuracy gains in video, audio, 3D, and medical imaging benchmarks compared to state-of-the-art models.
MEXA: Towards General Multimodal Reasoning with Dynamic Multi-Expert Aggregation
The paper presents MEXA (Multimodal Expert Aggregator), a novel framework designed to address the challenges of scalable multimodal reasoning by aggregating multiple pre-trained expert models. It focuses on efficient reasoning across diverse domains such as video, audio, 3D, and medical imaging by introducing a training-free framework that dynamically selects and aggregates expert models based on input modalities and task-specific demands. Herein, MEXA is positioned as an innovative approach that leverages modular and interpretable reasoning without additional training overhead.
Framework Design
Dynamic Multi-Expert Aggregation
MEXA operates by dynamically coordinating a suite of specialized experts, each designed to handle distinct modality-task pairs. The approach involves:
- Expert Selection: MEXA employs a Multimodal LLM (MLLM) as a router to select relevant expert models based on the input modality and reasoning demands. This enables the activation of only the most appropriate expert models for a given input, ensuring effective aggregation of outputs for multimodal reasoning.
- Aggregation through Large Reasoning Models (LRM): Selected expert outputs are aggregated by an LRM that excels in long-context understanding and Complex Chain of Thought (CoT) reasoning. This step ensures the integration of complementary outputs from diverse experts to produce precise and contextually appropriate answers.
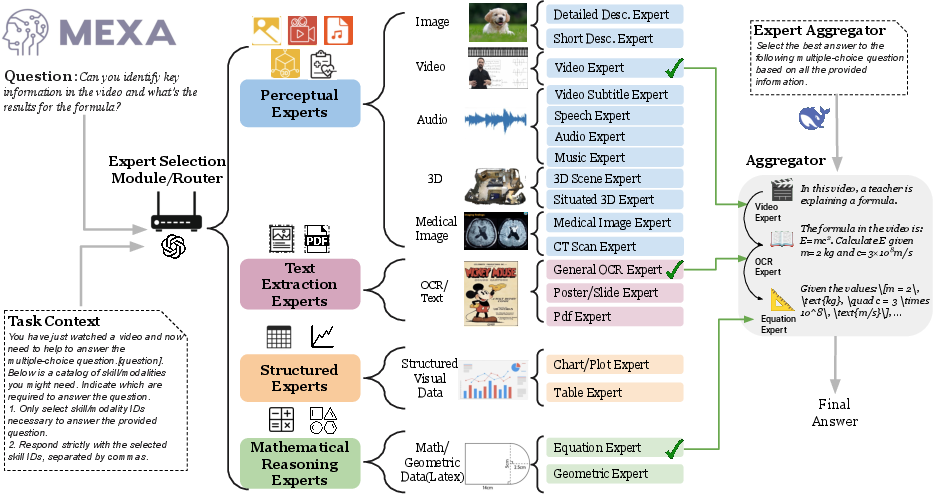
Figure 1: Overview of the MEXA Architecture. Given the input task context and question, MEXA first employs an MLLM router to select the appropriate experts based on input modality and required reasoning skills. The aggregator then reasons over the outputs from the selected experts to generate the final answer.
Expert Module Design Principles
MEXA organizes a diverse pool of expert models with two key design principles:
- Task-Aware and Modality-Sensitive: The experts are categorized into perceptual, textual, structured, and mathematical types, with specific designs ensuring they can address mainstream multimodal challenges effectively. Expertise is further subdivided into fine-grained skills, enabling MEXA to support dynamic, task-specific adaptation.
- Unified Textual Representation: All expert outputs are transformed into a shared textual format, facilitating seamless integration and reasoning by the LRM. This design choice enhances interpretability and the consistent handling of diverse modalities.
Experimental Evaluation
Benchmarks and Metrics
MEXA's efficacy is evaluated across multiple multimodal benchmarks: Video Reasoning (Video-MMMU), Audio QA (MMAU), 3D Understanding (SQA3D), and Medical QA (M3D). The framework consistently demonstrates superior performance over strong baselines, including state-of-the-art multimodal models.
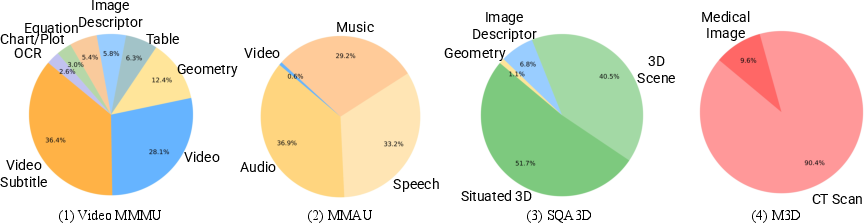
Figure 2: Expert distributions selected by MEXA across different benchmarks, covering video (Video-MMMU), audio (MMAU), 3D (SQA3D), and medical imaging (M3D).
Quantitative Results
Experimental results show notable performance improvements:
- Video-MMMU: MEXA achieved accuracy gains of up to 6% over GPT-4o and performed on par with human experts in complex video reasoning tasks.
- MMAU: It significantly outperformed audio LLMs, demonstrating an average accuracy improvement of 15.6%.
- SQA3D: Achieved robust situated reasoning with clear advantages over unified 3D models.
- M3D: Demonstrated superior 3D medical image analysis capabilities with an improvement of 8.7% over GPT-4o.
The efficient expert-driven aggregation framework is validated through these benchmarks, showcasing its flexibility and robustness.
Conclusion and Implications
In conclusion, MEXA represents a significant advancement in multimodal AI by providing a highly flexible and interpretable framework that facilitates complex cross-modal reasoning without the need for expensive training. The plug-and-play nature of expert modules ensures scalability and adaptability to emerging modalities, indicating potential avenues for future research in general multimodal reasoning frameworks.
The adaptability of MEXA hints at its possible integration into real-world applications, providing a robust solution for tasks requiring complex interaction between varied data types. The use of pre-trained experts and state-of-the-art LLMs positions MEXA as a promising blueprint for future architectures seeking to generalize across increasingly complex multimodal landscapes.