- The paper introduces LGKDE, which learns graph metrics through graph neural networks and maximum mean discrepancy for multi-scale kernel density estimation.
- It demonstrates theoretical consistency with convergence guarantees and minimax-optimal mean integrated squared error rates, ensuring robust performance.
- Empirical results reveal superior accuracy in recovering synthetic graph distributions and detecting anomalies compared to traditional methods.
Learnable Kernel Density Estimation for Graphs
Introduction
The paper "Learnable Kernel Density Estimation for Graphs" (2505.21285) introduces a framework called LGKDE to address the challenge of modeling probability density functions on graph-structured data. Traditional methods relying on graph kernels combined with KDE have limitations due to the fixed and handcrafted nature of graph kernels, which hinder their performance. The proposed LGKDE leverages graph neural networks and maximum mean discrepancy (MMD) to learn graph metrics for multi-scale KDE, while perturbing both node features and graph spectra to enhance density region characterization.
Theoretically, consistency and convergence guarantees are established for LGKDE, including bounds on the mean integrated squared error and robustness. Empirical validation is performed on synthetic graph distributions and benchmark datasets, showing superior performance compared to existing methods.
Methodology
Problem Definition
Graph density estimation involves learning a mapping from graph structures to density values, capturing distribution complexities present in node features, structural variations, and size shifts. The algorithm must also exhibit permutation invariance while being sensitive to anomalies.
LGKDE Framework
LGKDE incorporates a deep graph MMD model to learn adaptive metrics between graphs. The framework consists of a density estimator using multi-scale kernels and a structure-aware sample generation mechanism:
- Node Feature Perturbation: Node features are randomly shuffled using a subset of nodes, helping induce variations in the graph.
- Spectral Perturbation: Singular value decomposition of adjacency matrices enables perturbations via energy-based modifications, providing controlled variations.
The learning objective maximizes densities of normal graphs relative to their perturbed counterparts, ensuring better discrimination in anomaly detection tasks.
Algorithm
The LGKDE framework jointly optimizes graph embeddings and kernel parameters through the maximization of the density contrast, enabling effective capture of graph structural and semantic patterns.
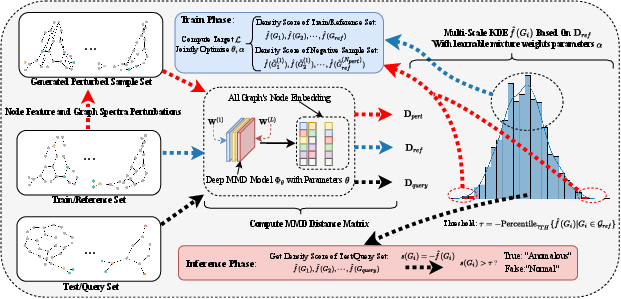
Figure 1: Framework of LGKDE
Theoretical Analysis
LGKDE establishes a foundational consistency theorem ensuring convergence to the true density in L1 norm as the sample size grows. Furthermore, it provides convergence rates showing mean integrated squared error (MISE) matches the minimax optimal rates associated with nonparametric density estimation.
Robustness to graph perturbations and generalization bounds are provided, illuminating that the MMD metric space retains stability against minor perturbations and ensures stable learning despite unsupervised conditions.
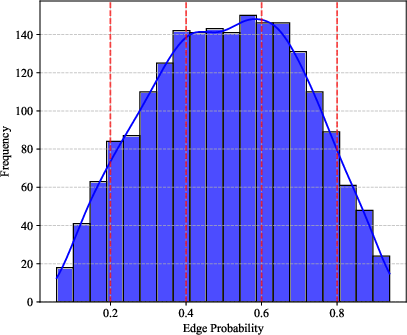
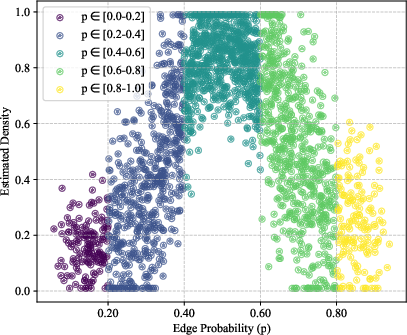
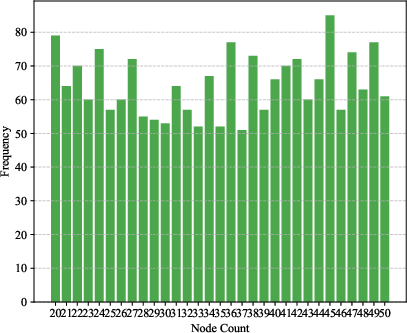
Figure 2: Density estimation results on synthetic Erdős–Rényi graphs. Left: Ground truth Beta(2, 2) distribution for edge probability p. Middle: Learned density estimate shows the expected peak around p=0.5. Right: Uniform distribution of node counts.
Experiments
Synthetic Data
Experiments on synthetic Erdős–Rényi graphs validate LGKDE’s ability to recover underlying graph distributions. LGKDE assigns higher densities to graphs with edge probabilities around 0.5, accurately reflecting the Beta distribution parameters.
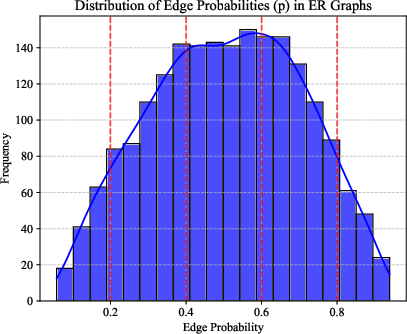
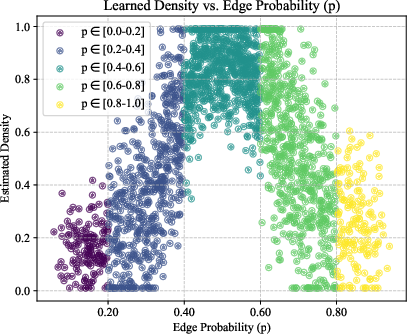
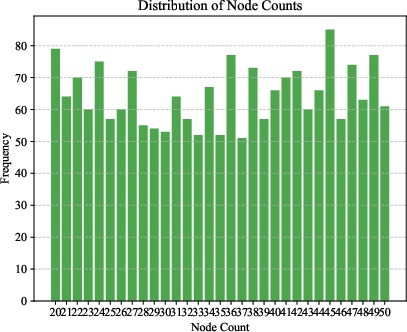
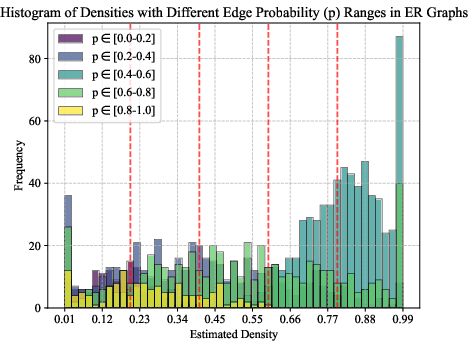
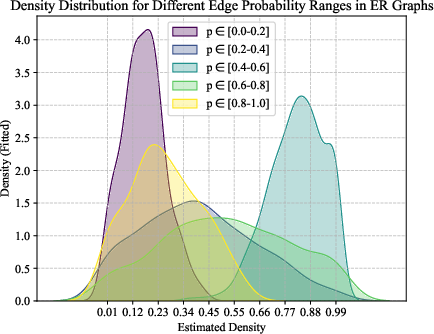
Figure 3: Density estimation results on synthetic Erdős–Rényi graphs.
Graph Anomaly Detection
In benchmark datasets, LGKDE consistently achieves superior AUROC and AUPRC scores compared to traditional graph kernel methods and state-of-the-art GNN-based approaches. The framework demonstrates robust detection of anomalies across varying graph structures and sizes, with competitive runtime performance and general scalability capabilities.
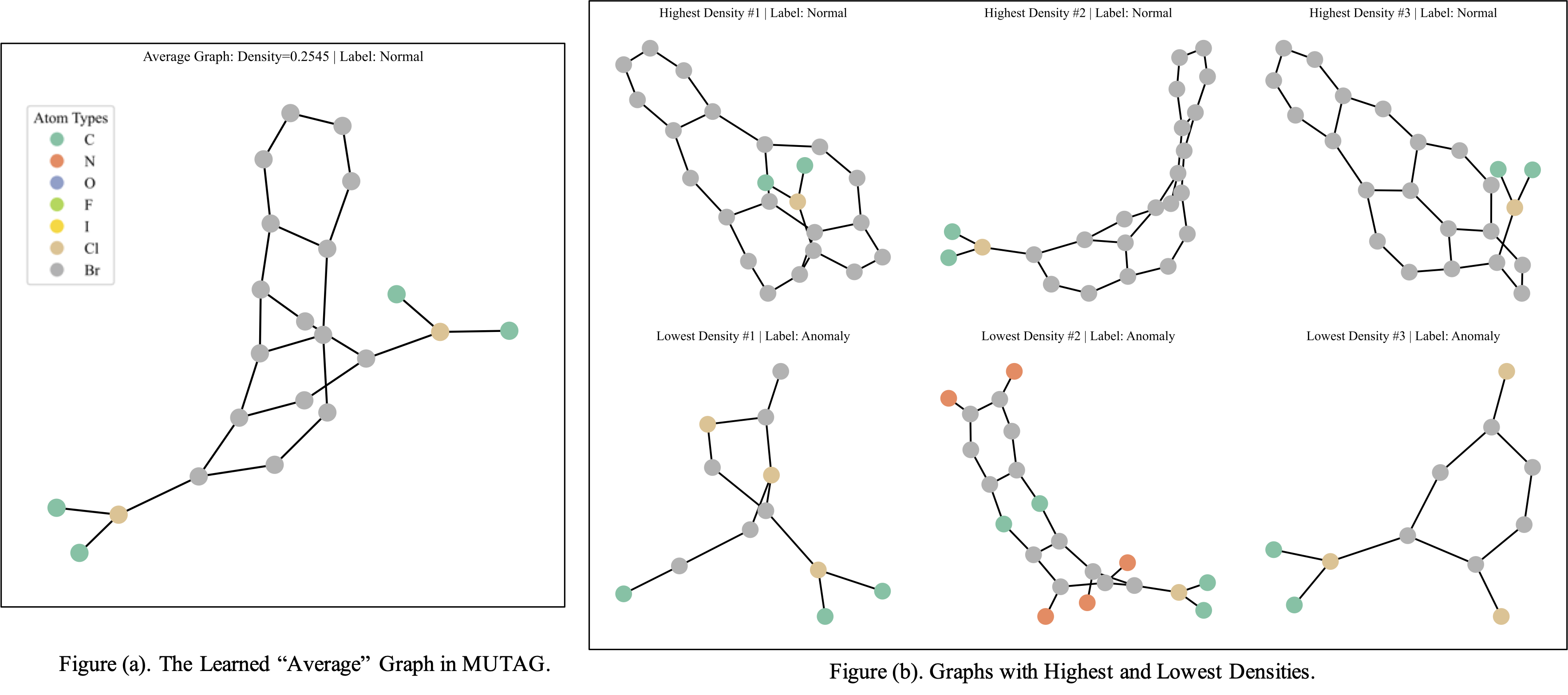
Figure 4: Visualization of MUTAG graphs: examples assigned densities by LGKDE.
Conclusion
LGKDE offers an effective framework for learnable kernel density estimation on graph-structured data, bridging deep representation learning with adaptive KDE methodologies. The comprehensive theoretical analysis alongside extensive empirical evaluations confirms the framework's practical utility in graph density estimation and anomaly detection.
Future research may emphasize scalability enhancements, extend to more diverse graph modalities, and improve interpretability of density results, further solidifying LGKDE's applicability in critical domains involving graph data.