- The paper introduces a unified discrete diffusion model that efficiently generates multimodal outputs while overcoming limitations of autoregressive approaches.
- It employs a MaskGIT-style architecture with continuous-time Markov chains to jointly optimize text and image token reconstruction, improving generation quality.
- The model achieves competitive benchmarks in text-to-image, image-to-text, and visual question answering, offering an order of magnitude faster inference.
Muddit: Liberating Multimodal Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
Muddit is introduced as a unified discrete diffusion transformer for multimodal generation tasks, including text-to-image synthesis, image-to-text transformation, and visual question answering. The model capitalizes on pretrained text-to-image diffusion backbones, fostering alignment between text and image modalities without the efficiency constraints of conventional autoregressive models.
Unified Generative Models
Muddit addresses the dichotomy between autoregressive (AR) and diffusion-based generative models, giving rise to a unified architecture capable of parallel processing across modalities. Traditional AR models are limited by sequential decoding inefficiencies, whereas Muddit leverages a discrete diffusion framework, allowing simultaneous generation of text and image tokens in a more scalable fashion.

Figure 1: Four types of unified generative models. More details can be found in Sec.~\ref{sec:related_work}.
Muddit builds upon discrete diffusion models, which override the inefficiencies of token-by-token generation by initializing its backbone with pretrained models such as Meissonic. By embedding strong visual priors, Muddit enhances the generation quality and maintains competitive performance across varied tasks.
Architecture and Training
Muddit harnesses a MaskGIT-style architecture, utilizing discrete diffusion to obscure tokens progressively, employing continuous-time Markov chains for both text and image modalities. During training, Muddit optimizes via a masked token predictor aiming to reconstruct original token sequences by integrating visual and textual priors into a shared generation space.
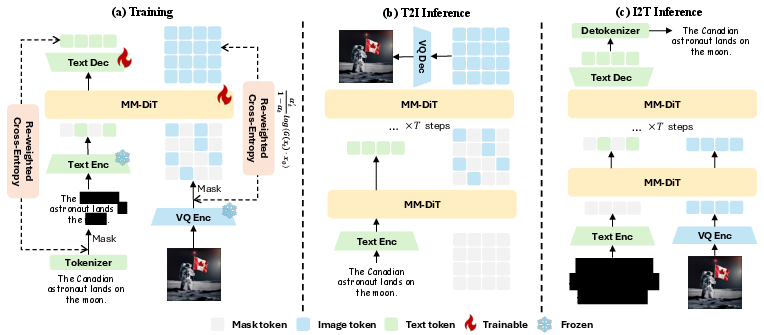
Figure 2: The training and inference architecture of Muddit.
The architecture supports integrated multimodal generation under a unified loss function, ensuring robust training across vision tasks by refining text and image representations simultaneously. The model's adaptability is demonstrated through flexible conditionality in multimodal contexts, from high-resolution image synthesis to comprehensive textual analyses.
Experimental Results
Text-to-Image Generation
Muddit showcases its efficacy on the GenEval benchmark by matching the performance of larger diffusion models despite a smaller parameter footprint. The model's ability to capture intricate compositional details signifies its potential as a scalable solution, unifying multimodal generation within a discrete framework.

Figure 3: Samples of Text-to-Image Generation by Muddit.
Image-to-Text Generation
Muddit's efficiency extends to image-to-text generation, outperforming multimodal models across standard benchmarks like MS-COCO and VQAv2. It effectively utilizes pretrained components to yield coherent captions while maintaining the fidelity of visual information.

Figure 4: Samples of Image-to-Text Generation by Muddit.
Visual Question Answering
In visual question answering, Muddit demonstrates its capability to synthesize answers based on complex image contexts, employing a unified generative strategy to address both visual understanding and textual interpretation.

Figure 5: Samples of Visual Question Answering by Muddit.
Inference Efficiency
Muddit's discrete diffusion mechanism provides substantial speed benefits in generation tasks by enabling parallel processing. Compared to autoregressive models, Muddit achieves an order of magnitude faster inference without sacrificing generative performance.
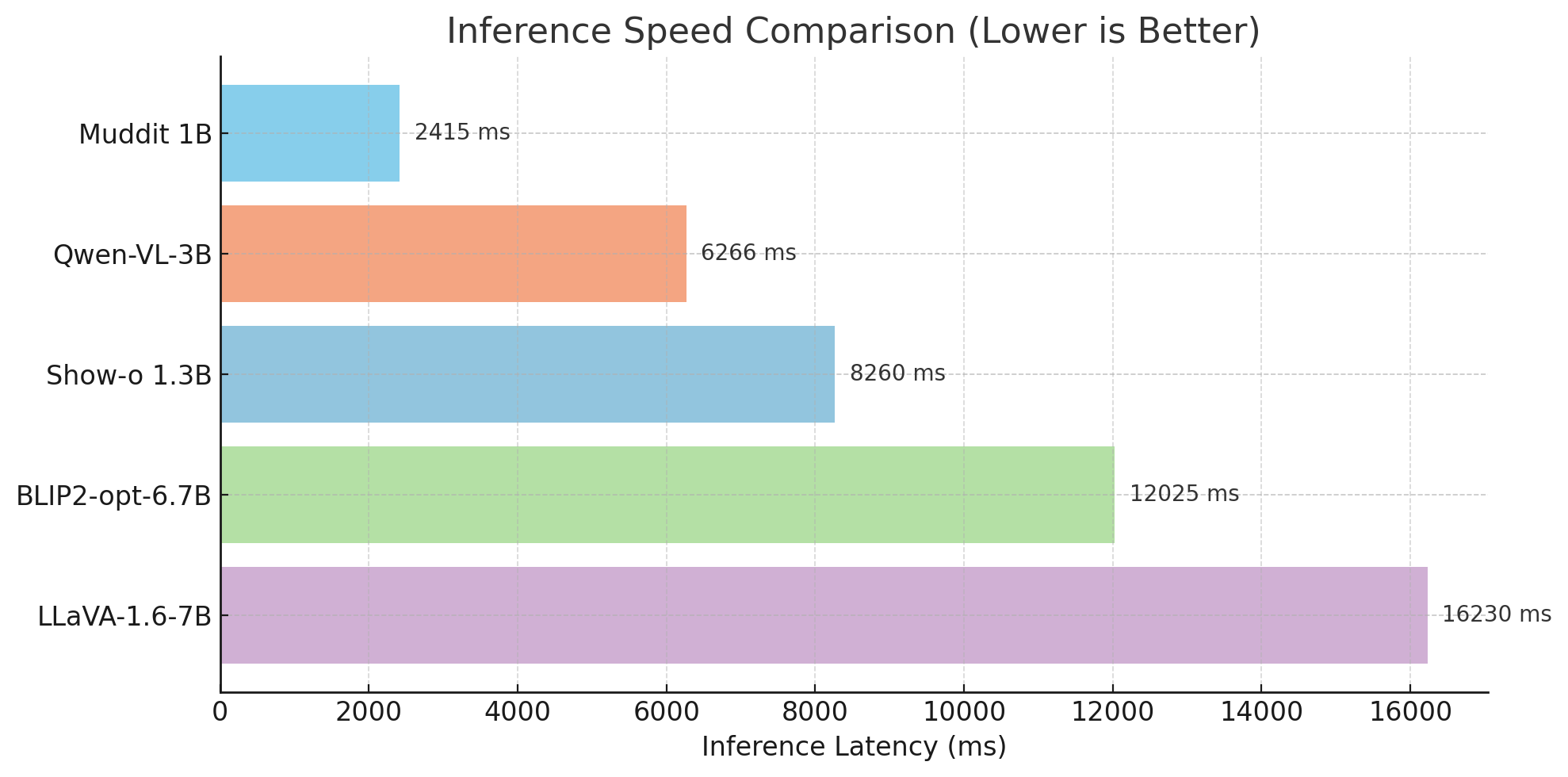
Figure 6: Inference speed comparison.
Although discrete diffusion necessitates innovative strategies like KV-cache development for enhanced efficiency, Muddit's performance evinces a promising direction for real-time multimodal interactions.
Conclusion
Muddit advances the discrete diffusion paradigm by aligning visual and textual inputs in multimodal generation tasks, offering a versatile model capable of leveraging pretrained visual backbones for superior performance. Its unified approach proves effective across varied synthesis tasks, endorsing discrete diffusion as a scalable multimodal strategy. Future developments in discrete diffusion caching could further optimize Muddit’s generative capabilities, promoting its application in complex multimodal environments.

