The Design Space of Tri-Modal Masked Diffusion Models
Abstract: Discrete diffusion models have emerged as strong alternatives to autoregressive LLMs, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper builds a single AI model that can understand and create three kinds of things: text, images, and audio (like speech). It uses a method called “masked diffusion,” which is a way of learning by repeatedly filling in missing pieces. The main idea is to train one unified model from scratch—rather than gluing together separate models—so it can naturally switch between tasks like writing text from a prompt, turning text into an image, turning text into speech, or describing an image.
What questions did the researchers ask?
To guide the design of this tri-modal model, the authors set out to answer a few practical questions:
- How do you build one model that speaks all three “languages” (text, image, audio) using the same training approach?
- What training settings (like batch size, noise levels, and the mix of data types) make the model stable and efficient to train at large scale?
- How do results change as the model gets bigger or sees more data (scaling laws)?
- What are good default settings for how the model “samples” or generates content, and do those settings differ for text, images, and audio?
- Can we remove the annoying step of searching for the “best batch size” by rethinking how the optimizer is set up?
How did they do it?
Think of masked diffusion like a puzzle game:
- You take a sequence (sentence, image tokens, or audio tokens).
- You randomly mask some of the pieces (replace with special “MASK” tokens).
- The model learns to guess the masked pieces from the surrounding context.
- You repeat this, gradually revealing more correct pieces, until the whole sequence is complete.
Here’s how they turned that into a tri-modal system:
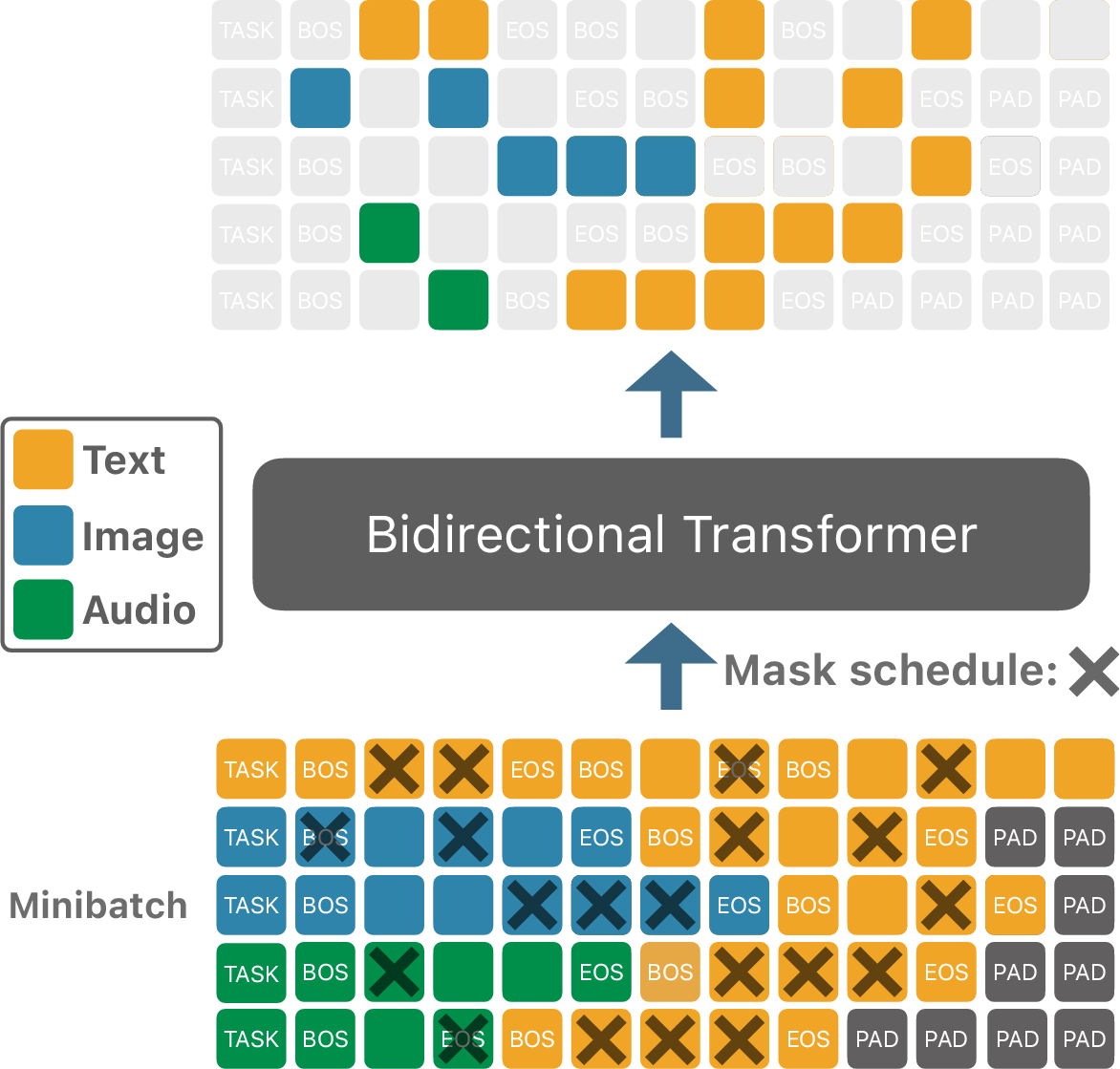
- Unified token stream: Text, image, and audio are all turned into discrete “tokens” (like Lego bricks), with special start/end and MASK tokens for each modality. All tokens live in one shared vocabulary so a single transformer can handle them.
- One backbone, many tasks: The same transformer model is trained on three kinds of samples: text-only, image+text pairs, and audio+text pairs. Special “TASK” tokens tell the model what job to do (e.g., “make an image from text”).
- Continuous masking: At training time, they pick a corruption level (how much to mask) and apply it independently to positions in the sequence. The model learns to predict the original token at masked spots.
- Denoising during generation: To create something (say, an image from a prompt), they start with a sequence full of MASK tokens for the target modality, plus the text prompt. Then they repeatedly “unmask” positions by sampling the model’s guesses, until the result is complete.
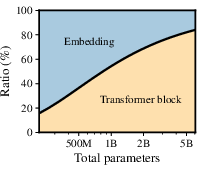
- Practical architecture: They use a standard transformer with well-known parts (RMSNorm, SwiGLU, RoPE, and attention tweaks), plus efficient loss tricks so training is fast even with a huge vocabulary. Images and audio are tokenized with specialized encoders (so the model deals with compact tokens rather than raw pixels or waveforms).
An important training trick:
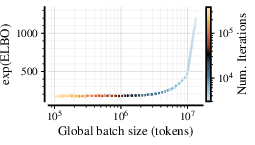
- Batch size is how many examples the model processes at once. Usually, changing batch size changes how training behaves, so people search for an “optimal batch size.” The authors use an SDE-based reparameterization (a way of tying optimizer settings to batch size) that makes training behave almost the same across a wide range of batch sizes—up to a safe threshold. This separates:
- Physical batch size: chosen to make the GPUs run efficiently.
- Logical batch size: chosen to keep gradient noise balanced.
- In short, they reduce the need for batch-size tuning.
What did they find?
Here are the key results and why they matter:
- First tri-modal masked diffusion model trained from scratch: One model, one vocabulary, three modalities. It can handle text generation, text-to-image (T2I), text-to-speech (T2S), image captioning, and speech recognition (ASR) without extra adapters or separate heads.
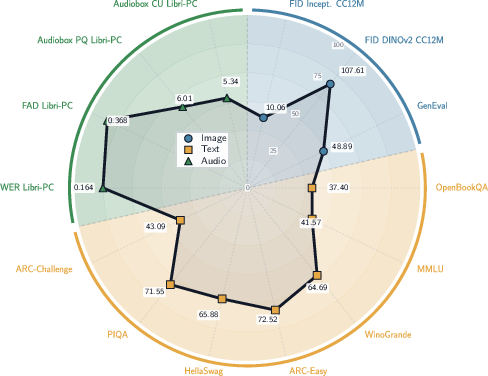
- Strong performance at scale: A 3B-parameter model trained on about 6.4 trillion tokens shows high-quality results across text, images, and audio. Image samples demonstrate good adherence to prompts and fine visual details (lighting, texture, composition).
- Batch size breakthrough: Their SDE reparameterization makes the training loss almost independent of batch size (until a “critical” threshold). That means teams can pick batch sizes for practical GPU reasons without hurting quality, and skip expensive “what batch size is best?” sweeps.
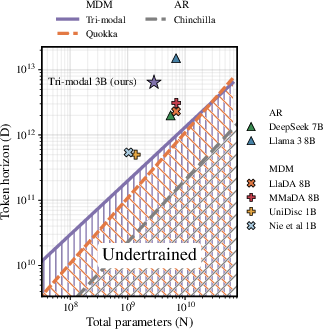
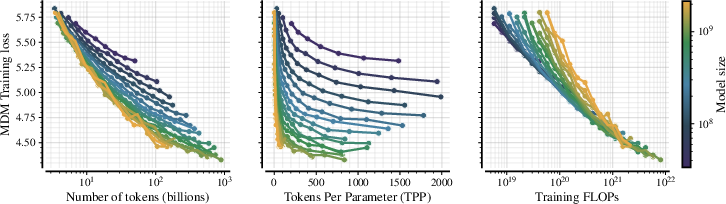
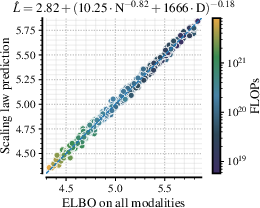
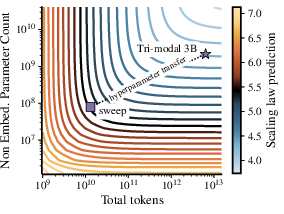
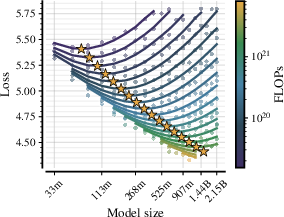
- Clear multimodal scaling laws: They measured how validation loss changes with model size (N) and data size (D) and fit a reliable law. The compute-optimal data for masked diffusion grows sub-linearly with model size—meaning larger models become more data-efficient per parameter than you might expect from typical autoregressive LLMs. A rough rule they found is:
- Optimal tokens D* scale like D* ≈ 7754 × N0.84
- Translation: As you make the model bigger, you still need a lot of data, but not proportionally more, and masked diffusion benefits from this trend.
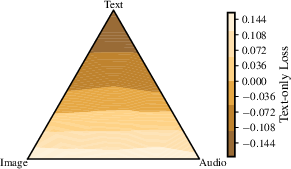
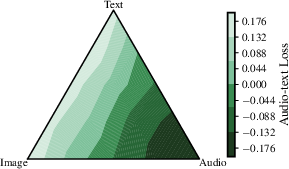
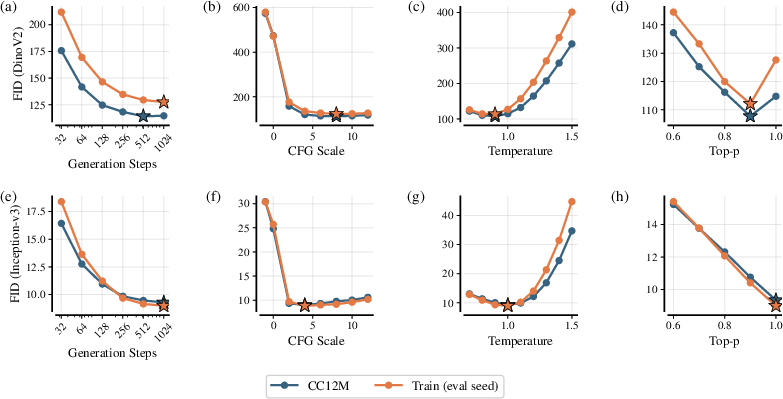
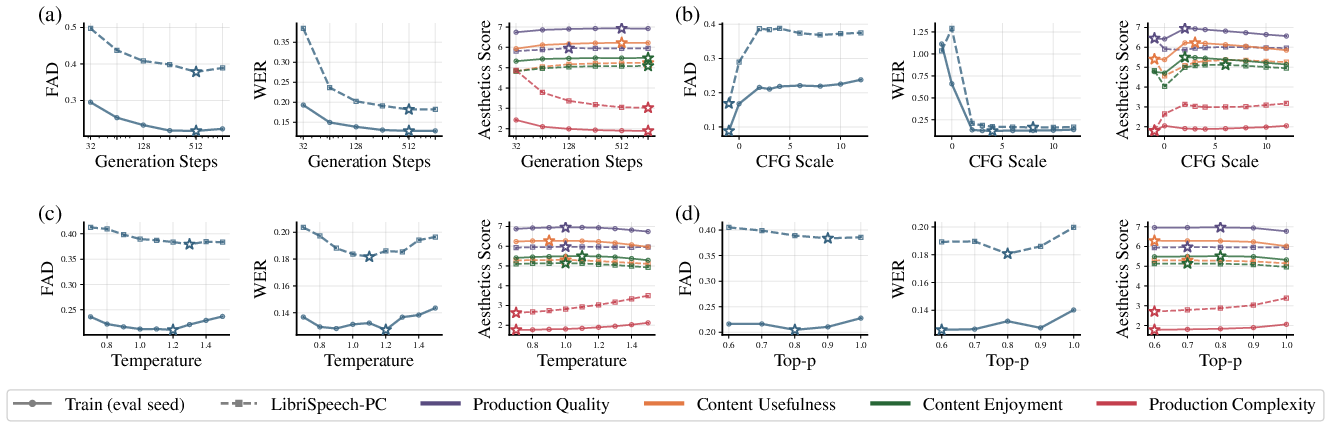
- Modality-specific generation settings: Text, images, and audio prefer different noise schedules and sampling parameters (like guidance and temperature). The paper gives tuned defaults per modality for better generations.
Why does this matter?
- Unification: Instead of juggling separate models for text, images, and audio, this work shows you can train one model that does them all. That simplifies building multimodal AI systems and opens the door to more flexible “any-to-any” tasks.
- Practical training recipes: By taking batch-size tuning off the critical path and providing scaling laws, the paper gives teams a clearer, more predictable path to train large multimodal models efficiently.
- Better multimodal reasoning: Because the model learns to fill in missing pieces across mixed token streams, it naturally supports infilling and conditioning (e.g., “add a sound effect to this image description,” or “continue this story with an illustration”).
- Foundation for future work: The authors share systematic findings at large scale. That helps the community make fair comparisons and design compute-optimal training runs for masked diffusion across multiple modalities.
In short, this paper maps out how to build and scale a single, unified model that understands and generates text, images, and audio—while offering practical tools (like SDE-based optimization and scaling laws) to make training smoother and smarter.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research:
- Quantitative evaluation is incomplete across modalities and tasks: the paper lacks standardized metrics and head-to-head baselines for text (e.g., perplexity, MMLU), T2I (e.g., FID, CLIPScore, ImageReward), ASR (WER/CER), and TTS (MOS/CMOS), as well as multimodal tasks (e.g., captioning, cross-modal retrieval).
- End-to-end comparisons of sampling latency and throughput vs strong autoregressive and continuous diffusion baselines are missing; the practical inference cost of tri-modal MDM remains unclear across step counts and hardware.
- The proposed “optimized inference sampling defaults” and “modality-specific schedules” are not formalized into a principled selection/tuning procedure; it is unknown how to automatically adapt steps, masking schedules, temperature, and guidance across prompts, modalities, or quality–latency targets.
- Inference acceleration for masked diffusion (e.g., step distillation, consistency models, speculative decoding, early-exit criteria, adaptive unmasking, or hybrid AR–diffusion pipelines) is not addressed.
- The effect of tokenizer choice is not studied: how image (VQ) and audio (neural codec) codebooks, codebook sizes, downsampling rates, and reconstruction losses impact cross-modal learning, data efficiency, and final quality.
- No exploration of jointly learned or shared discrete tokenizers across modalities (vs disjoint vocabularies), nor analysis of cross-modal embedding sharing, interference, or benefits of partial vocabulary sharing.
- Data composition and quality are under-specified: the paper does not analyze data sources, modality proportions, alignment noise in pairs, duplication, filtering, language coverage, or bias/toxicity; their impacts on scaling, stability, and downstream quality are open.
- Optimal modality mixing ratios and their dependence on model size and token budget are not identified; dynamic curricula or adaptive mixture schedules during training remain unexplored.
- Use of unpaired unimodal data (image-only, audio-only) in tri-modal MDM training is not studied; strategies to leverage abundant unpaired data while preserving cross-modal capabilities are open.
- The unified vocabulary introduces modality-specific BOS/EOS/MASK and TASK tokens, but ablations on these design choices (e.g., shared vs modality-specific masks, masking of boundary tokens, task-token masking or alternatives) are absent.
- The Bernoulli masking process and weighting are adopted without a systematic comparison to alternative corruption/noise schedules (e.g., span/block masking, uniform-state/mixture-state diffusion, adaptive masking rates per modality or token type).
- The SDE-based reparameterization removes “up to a critical threshold,” but there is no analytic or predictive model of (or ) as a function of sequence length, optimizer hyperparameters, data noise, or architecture; deriving formulas or estimators would make planning more actionable.
- The reported independence of from model size is empirical and constrained to a limited range; it remains unverified at larger scales, different architectures (e.g., deeper/wider configurations, MoE), and other optimizers/schedules.
- The proposed drift–horizon tradeoff () is fitted for a cosine schedule; robustness to alternative schedules (e.g., warmup–stable–decay), gradient clipping, EMA, or optimizers (Adafactor, Lion, Sophia) is unknown.
- Per-module hyperparameter scaling (CompleteP + SDE) is only “preliminary”; comprehensive ablations across modules and modalities, sensitivity to β1/β2/ε, and transfer to larger models and different data mixes are missing.
- The scaling law fit (L = E + (AN{-a/b} + BD{-1})b) is empirical; its stability under different data mixtures, tokenizers, architectures, and modality balances—and the reliability of extrapolation beyond the studied range—remains untested.
- The compute-optimal token law D*(N) = 7754·N0.84 is given for tri-modal training as a whole; there is no guidance on compute allocation across modalities (e.g., how many text-only vs paired tokens) to optimize a specific target task or a portfolio of downstream objectives.
- Cross-directional generation is claimed (e.g., audio→image, image→audio), but evidence and metrics are sparse; robustness and quality across all direction pairs and conditioning styles (infilling, partial conditioning, multimodal prompts) need evaluation.
- The non-causal, bidirectional design is not reconciled with streaming constraints for ASR/TTS; methods for low-latency or online tri-modal diffusion (e.g., chunked/incremental denoising, causal–noncausal hybrids) are unaddressed.
- Long-context scaling and memory efficiency are not explored; the O(L2) bidirectional attention may limit high-resolution images or long audio; architectural variants (e.g., local/sparse attention, Perceiver, recurrent state) warrant study.
- Potential negative transfer and interference between modalities in a shared backbone are not diagnosed; techniques such as adapters, routing/MoE, or orthogonal regularization to mitigate cross-modal interference are not tested.
- Guidance methods for discrete diffusion (e.g., classifier-free guidance) are mentioned but not detailed; their variants, stability, and calibration differences across text/image/audio remain an open design space.
- The role of reconstruction tokenizers in end-to-end quality is not disentangled from the MDM backbone: evaluation that isolates tokenizer artifacts vs model errors is missing.
- Continual and incremental learning with TASK tokens (adding modalities or tasks mid-training) is suggested but not demonstrated; catastrophic forgetting and stability–plasticity tradeoffs are unexplored.
- Safety, alignment, and misuse controls for tri-modal generation (e.g., harmful audio, image realism risks) are not discussed; integrating preference optimization or safety tuning for MDMs remains open.
- Reproducibility gaps exist around token accounting: different sections cite 6.4T tokens and training configurations that imply larger totals; a precise and standardized token-counting methodology (packing, padding, multimodal pairing) is needed.
Practical Applications
Immediate Applications
The paper’s tri-modal masked diffusion model (MDM), SDE-based reparameterization for training, and empirically derived scaling laws enable several deployable applications across sectors. The items below describe concrete use cases, likely workflows/products, and key assumptions or dependencies.
- Unified text–image–audio generation toolkit (software, media/entertainment)
- Use case: A single model that supports text-to-image (T2I), image captioning, text-to-speech (TTS), automatic speech recognition (ASR), and arbitrary cross-modal infilling without modality-specific heads or separate models.
- Workflow/product: “Tri-Modal Studio” plugin for creative suites where users storyboard with text prompts, generate illustrative images, get narrated audio, and caption images—all from one backbone.
- Assumptions/dependencies: Availability of high-quality tokenizers (e.g., MoVQGAN for images, Higgs Audio for audio), access to training compute or pretrained weights, and adherence to the paper’s modality-specific mask/task tokenization scheme. Sampling remains slower than autoregressive models; server-side/offline generation may be needed for latency-sensitive use.
- Multimodal accessibility pipeline (public sector, education, daily life)
- Use case: Automatically caption images and read them aloud; transcribe spoken content and render key visuals from transcripts (e.g., diagrams), improving content accessibility.
- Workflow/product: Web and mobile accessibility services that connect image captioning with TTS for alt-text audio, or ASR for lecture transcripts followed by auto-generated visual summaries.
- Assumptions/dependencies: Caption quality depends on domain coverage; TTS quality is bounded by tokenizer/audio codebook; ensure privacy and consent for audio/image inputs.
- Contact center and meeting solutions (enterprise/finance)
- Use case: Unified ASR for call transcription, TTS for response playback, and image-generation for visual summaries of conversations (e.g., dashboards for agents).
- Workflow/product: Integrate the tri-modal MDM into call analytics platforms to transcribe calls and produce concise textual/visual briefings; use TTS for follow-up messages.
- Assumptions/dependencies: Domain fine-tuning needed for jargon and compliance; latency constraints may require distillation or reduced diffusion steps.
- Batch-size-agnostic training in MLOps (software/infra)
- Use case: Decouple physical batch size (compute-driven) from logical batch size (optimization-driven) via SDE-based reparameterization to stabilize performance across hardware configurations.
- Workflow/product: “Batch-Agnostic Trainer” module for PyTorch/JAX that sets AdamW hyperparameters via the paper’s SDE rules and monitors/alerts for the critical batch threshold B_crit.
- Assumptions/dependencies: Accurate implementation of the SDE reparameterization and monitoring of the critical iteration count S_crit; availability of optimizer-level hooks to rescale LR/momenta/epsilon.
- Compute and data budgeting using scaling laws (R&D management, academia, industry)
- Use case: Plan model and dataset sizes using the provided scaling fit L = E + (A N{-a/b} + B D{-1})b and compute-optimal data curve D*(N) ≈ 7754 * N0.84 for tri-modal MDMs.
- Workflow/product: Internal “Budget Planner” tool that recommends parameter counts, token budgets, and procurement strategy for multimodal corpora under fixed compute.
- Assumptions/dependencies: Laws derived under specific architecture and training recipe (CompleteP + SDE; cosine schedule; bidirectional Transformer); may shift with domain, safety training, or optimizer schedules.
- Modality-specific inference presets for quality/latency trade-offs (software, embedded systems)
- Use case: Apply the paper’s modality-dependent defaults (noise schedules, guidance, temperature) to optimize T2I, TTS, and ASR outputs without re-tuning from scratch.
- Workflow/product: “Modality Preset Manager” that loads per-modality sampling configs with guardrails to prevent cross-modal degradation.
- Assumptions/dependencies: Profiles depend on tokenizer, data distribution, and target QoS; latency improvements still need step-reduction/distillation for real-time use.
- Efficient large-vocabulary training with cut-cross-entropy (CCE) and z-loss (ML engineering)
- Use case: Reduce memory/compute overhead from unified tri-modal vocabularies and stabilize logit scales during training.
- Workflow/product: Drop-in CCE + z-loss packages for large-vocab multimodal models.
- Assumptions/dependencies: Correct integration with masking and modality constraints; validation on organization-specific data.
- Unified task routing and packaging via task/modality tokens (software)
- Use case: Extend models with new tasks mid-training or during supervised fine-tuning by signaling tasks with special tokens and shared vocabularies.
- Workflow/product: Multi-task tri-modal APIs that activate behaviors (e.g., “TASK_text”, “TASK_image-text”, “TASK_audio-text”) without architectural changes.
- Assumptions/dependencies: Requires compatible data formatting pipelines; proper attention masking for PAD/TASK tokens.
- Energy and cost reduction in training operations (energy/ops)
- Use case: Use SDE parametrization to avoid suboptimal batch sizes and reduce wasted compute; match physical batch size to GPU throughput while staying under B_crit.
- Workflow/product: Training scheduler that dynamically adapts global batch size and optimizer hyperparameters to meet cost/energy targets with consistent outcomes.
- Assumptions/dependencies: Accurate tracking of D, L, B_crit/S_crit; robust monitoring; cluster support for schedule adaptation.
- Academic reproducibility and fair comparison standards (academia, policy)
- Use case: Report model and data size pairs (N, D_total) for multimodal comparisons; adopt the paper’s tri-modal recipe to benchmark MDMs.
- Workflow/product: Conference checklists and lab protocols that require joint reporting of model and total token budgets, and declaration of modality mixing ratios.
- Assumptions/dependencies: Community buy-in; shared baselines for tokenizer choices and FLOP accounting (e.g., excluding tokenizer compute, as in the paper).
Long-Term Applications
The following rely on further research in sampling efficiency, domain adaptation, safety alignment, or hardware optimization before broad deployment.
- On-device or near-real-time tri-modal assistants (mobile, consumer devices)
- Use case: Speech-enabled assistants that can generate/describe images and read or summarize content locally.
- Workflow/product: Compressed/distilled tri-modal MDMs with reduced sampling steps and quantization for edge hardware.
- Assumptions/dependencies: Significant improvements in discrete diffusion sampling efficiency, quantization-aware training, and hardware acceleration.
- Multimodal tutoring and courseware generation (education)
- Use case: Personalized lessons with synchronized text, images/diagrams, and narrated audio; automatic creation of practice materials and explanations.
- Workflow/product: “Tri-Modal Tutor” that plans content across modalities and adapts difficulty using bidirectional context.
- Assumptions/dependencies: Pedagogical alignment, safety guardrails, robust evaluation on learning outcomes; domain fine-tuning.
- Clinical and assistive healthcare tools (healthcare)
- Use case: Transcribe consultations (ASR), generate readable summaries, produce illustrative visuals for patient education, and narrate discharge instructions.
- Workflow/product: Regulated, domain-adapted tri-modal MDM integrated with EHR systems.
- Assumptions/dependencies: Medical-grade datasets, rigorous validation, explainability, privacy compliance (HIPAA/GDPR), and specialized tokenizers for medical imaging/audio if extended beyond general images.
- Robotics HRI and multimodal command interfaces (robotics)
- Use case: Speak to a robot, show images of desired configurations, and receive verbal/image feedback or plans generated by a unified model.
- Workflow/product: Multimodal planners that convert spoken commands into visual plans and narrated step-by-step instructions.
- Assumptions/dependencies: Coupling with perception/action modules; real-time constraints; safety and robustness in physical environments.
- Multimodal retrieval and indexing in RAG systems (software/information retrieval)
- Use case: Index text, images, and audio in a shared token space for cross-modal search (e.g., find an audio clip by textual description, or images by spoken query).
- Workflow/product: Unified tri-modal vector stores and retrievers for enterprise knowledge management and media archives.
- Assumptions/dependencies: Training for retrieval objectives; scalable indexing; handling modality-specific token distributions and length disparities.
- Enterprise-grade training orchestration with “γ-planner” (software/infra)
- Use case: Optimize how extra tokens improve either SDE drift (virtual batch size) or horizon (virtual iteration count) using the paper’s γ trade-off to minimize loss at fixed compute.
- Workflow/product: MLOps scheduler that tunes γ dynamically based on learning curves, budget, and desired throughput.
- Assumptions/dependencies: Robust online estimators of α, β and model responsiveness to γ; compatibility with learning-rate schedules other than cosine.
- Data governance and compute policy guided by scaling laws (policy, sustainability)
- Use case: Avoid over- or under-training by grounding procurement in D*(N) ≈ 7754 * N0.84; mandate (N, D_total) reporting for funded projects to benchmark efficiency.
- Workflow/product: Funding and compliance guidelines that tie compute allocation and data acquisition to empirically supported plans; sustainability scorecards.
- Assumptions/dependencies: Cross-institution consensus; adaptation when models or domains deviate from the paper’s recipe.
- Cross-modal safety and alignment frameworks (policy, safety engineering)
- Use case: Develop standards for tri-modal safety (e.g., audio deepfake mitigation, harmful image/text generation controls) that operate in a unified token space.
- Workflow/product: Multimodal red-teaming protocols, tri-modal content filters, and audit trails integrated into generation pipelines.
- Assumptions/dependencies: Advancements in multimodal detection/mitigation; watermarking or provenance systems; legal frameworks for cross-modal harms.
- Domain-specific tri-modal copilots (industry verticals)
- Use case: Generate illustrated maintenance manuals with narrated steps (manufacturing), produce visualized financial summaries with spoken briefings (finance), or create marketing collateral across modalities.
- Workflow/product: Fine-tuned vertical MDMs with custom tokenizers/datasets and preconfigured inference presets by modality.
- Assumptions/dependencies: Curated, licensed datasets; rigorous domain evaluation; integration with enterprise data and security controls.
- Next-gen benchmarks and evaluation protocols (academia, standards)
- Use case: Comprehensive benchmarks that require joint text–image–audio reasoning, generation, and infilling, measured under consistent compute/data disclosures.
- Workflow/product: Open evaluation suites for tri-modal MDMs including latency/quality trade-offs per modality, robustness tests, and energy/compute metrics.
- Assumptions/dependencies: Community effort to standardize tasks and metrics; availability of open tri-modal datasets and tokenizers.
Notes on feasibility and dependencies across applications:
- Sampling efficiency: Discrete diffusion text and tri-modal sampling remains slower than autoregressive decoding; near-real-time deployments may need step-reduction, distillation, or hybrid models.
- Tokenizers matter: Image/audio quality depends on tokenizer/codebook choices and resolution/samplerate; swapping tokenizers may require re-tuning.
- Scaling law scope: The provided laws were derived under a specific architecture/training recipe; expect coefficient shifts with different optimizers, schedules, or domain distributions.
- Safety and compliance: Cross-modal generation raises new safety and regulatory considerations (privacy, bias, deepfakes); alignment must be integrated before production use.
- Compute infrastructure: SDE parameterization and B_crit/S_crit monitoring require training stack changes and careful observability to achieve the promised stability and efficiency.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient-based updates, widely used for large-scale transformer training. "Stochastic Optimization with AdamW operates like the discretization of a Stochastic Differential Equation (SDE)"
- autoregressive LLM: A model that generates tokens sequentially, conditioning each prediction on previously generated tokens. "Discrete diffusion models have emerged as strong alternatives to autoregressive LLMs"
- Bernoulli masking mechanism: A corruption process where each token is independently masked with a certain probability during diffusion training. "Each position is independently corrupted according to a Bernoulli masking mechanism"
- bidirectional RNNs: Recurrent neural networks that process sequences in both forward and backward directions to use past and future context. "Early work on bidirectional RNNs \citep{DBLP:journals/tsp/SchusterP97} and LSTMs \citep{DBLP:journals/nn/GravesS05} demonstrated clear gains over purely forward recurrent models when both past and future states were accessible during training."
- causal transformers: Transformers trained with a left-to-right constraint so each token attends only to previous tokens. "This makes the dominance of causal transformers \citep{DBLP:conf/nips/VaswaniSPUJGKP17} in modern language modeling slightly surprising:"
- CompleteP: A hyperparameter scaling framework that prescribes how to transfer learning rates and related settings across model scales. "using CompleteP + SDE scaling~\citep{mlodozeniec2025completed} within the multimodal \gls{mdm} regime"
- Continuous Time Markov Chains (CTMCs): Stochastic processes with memoryless transitions in continuous time, used here to model diffusion over discrete tokens. "formulated the forward noising process and corresponding reverse process as Continuous Time Markov Chains (CTMCs)"
- cosine learning rate schedule: A decay schedule that follows a cosine curve, often with warmup, to stabilize and improve training. "All experiments presented use a cosine learning rate schedule with 1k steps of linear warmup"
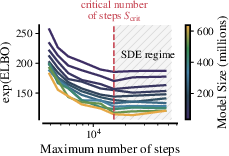
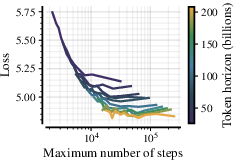
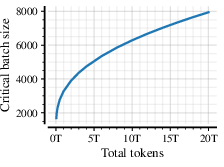
- critical batch size (B_crit): The maximum batch size under SDE parameterization beyond which training ceases to be FLOP-efficient at a fixed token budget. "Critical batch-size $B_{\text{crit}$ as a function of the token horizon"
- cut-cross-entropy (CCE): A memory-efficient variant of cross-entropy that restricts the candidate set, used for large vocabularies. "For memory efficiency and to enforce modality constraints, we implement this loss using cut-cross-entropy (CCE) \citep{DBLP:journals/corr/abs-2411-09009}"
- Dirac measure: A probability measure concentrated at a single point, used to express deterministic transitions in the diffusion kernel. "where denotes the Dirac measure centered at "
- discrete diffusion: A generative process that iteratively denoises corrupted discrete sequences instead of predicting tokens in order. "Discrete diffusion revisits the bidirectional viewpoint by replacing a fixed generation order with iterative refinement"
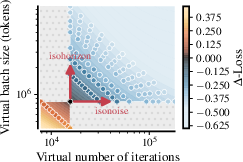
- drift–horizon tradeoff (gamma): The balance between reducing gradient noise (drift) and increasing the number of effective optimization steps (horizon) when allocating tokens. "Drift--horizon tradeoff~."
- ELBO (evidence lower bound): A variational objective that lower-bounds the log-likelihood; here used for the continuous-time masked diffusion process. "we plot the final as a function of the iteration count and model's size "
- FLOP-efficient: Achieving the best possible loss for a fixed compute budget (FLOPs) without wasting computation. "Above it, SDE discretization breaks and training ceases to be FLOP-efficient."
- guidance: A sampling technique (e.g., classifier-free guidance) that steers generation toward desired conditions by adjusting model predictions. "identifying that optimal noise schedules and sampling parameters (guidance, temperature) differ significantly between text, image, and audio generation."
- isohorizon curves: Settings that keep the effective number of optimization steps (horizon) constant when scaling tokens and batch size. "or (b) we can conserve the SDE horizon (isohorizon curves) with ."
- isonoise curves: Settings that keep the effective gradient noise level (drift) constant when scaling tokens and batch size. "we can conserve the SDE drift (isonoise curves) with "
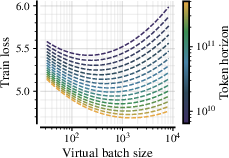
- isoFLOPs: Experimental sweeps that keep total training compute (FLOPs) constant while varying model size and token count. "We sample the pairs along 24 different isoFLOPs logarithmically distributed between"
- KV cache: A mechanism to cache keys and values in transformer attention for efficient streaming decoding. "fast streaming decoding via KV cache"
- logits: Unnormalized scores output by a model before applying a softmax to obtain probabilities. "which predicts logits over the unified vocabulary at each position."
- MaskGIT: A masked-token generative model that iteratively fills in masked positions for image synthesis. "MaskGIT and VQ-Diffusion ~\citep{DBLP:conf/cvpr/ChangZJLF22, DBLP:conf/cvpr/GuCBWZCYG22} instead use pretrained image tokenizers"
- masked diffusion: A diffusion approach where forward corruption replaces tokens with mask tokens and the model learns to reconstruct them. "This approach for masked diffusion with fixed timesteps was extended to a continuous-time framework"
- Mixture-of-Experts (MoE): Architectures that route inputs to specialized expert subnetworks to improve efficiency and capacity. "improve performance and efficiency by introducing variance reduction and mixture-of-experts (MoE) methods to large language diffusion."
- modality-constrained predictive distribution: A restricted output distribution during sampling that only permits tokens from the target modality’s vocabulary. "a candidate token is sampled from the modality-constrained predictive distribution"
- noise schedules: Functions that determine how corruption or denoising intensity varies across diffusion steps. "identifying that optimal noise schedules and sampling parameters (guidance, temperature) differ significantly"
- optimal batch size (B_opt): The batch size that minimizes loss for a fixed token budget in non-SDE settings; shown to be unnecessary under SDE scaling. "Elimination of Optimal Batch Size ($B_{\text{opt}$) and per-module transfer.}"
- QK-norm: A technique that normalizes query and key vectors in attention to stabilize training. "and QK-norm~\citep{DBLP:conf/icml/0001DMPHGSCGAJB23,DBLP:conf/iclr/WortsmanLXEAACG24,DBLP:journals/corr/abs-2405-09818, DBLP:journals/corr/abs-2503-19786}."
- RMSNorm: A normalization method that scales activations by their root-mean-square, used as a stable alternative to LayerNorm. "pre-normalization RMSNorm~\citep{DBLP:conf/nips/ZhangS19a}"
- RoPE (rotary positional embeddings): A method for encoding positions by rotating query/key embeddings, improving generalization to longer contexts. "rotary positional embeddings (RoPE)~\citep{DBLP:journals/corr/abs-2104-09864}"
- scaling laws: Empirical relationships that predict model performance as a function of model size, data, and compute. "We derive empirical scaling laws for validation loss as a function of model size () and token budget ()"
- SDE (stochastic differential equation): A continuous-time stochastic process used to model the dynamics of optimization under noise. "Stochastic Optimization with AdamW operates like the discretization of a Stochastic Differential Equation (SDE)"
- SDE-based reparameterization: Rescaling optimizer hyperparameters to make training dynamics invariant to batch size up to a critical threshold. "We leverage SDE-based reparameterization to render training loss invariant to batch size"
- SDE drift: The component of the SDE that governs deterministic movement due to gradients, influenced by batch size and optimizer parameters. "while SDE drift controls the scale of stochastic fluctuations induced by gradient noise."
- SDE horizon: The effective length of the optimization trajectory under the SDE interpretation, related to the number of updates. "the SDE horizon corresponds to the trajectory length in parameter space (extending from origin)"
- stationary distribution: A distribution that remains unchanged by the forward corruption process at convergence (e.g., fully masked). "turning the data distribution into a stationary distribution "
- SwiGLU: An activation function combining gated linear units with the SiLU nonlinearity for improved MLP performance. "SwiGLU MLPs~\citep{DBLP:journals/corr/abs-2002-05202}"
- token horizon: The total number of training tokens processed (data budget) used to measure training scale. "for a constant token horizon of 13B tokens."
- Tokens Per Parameter (TPP): A ratio indicating how many training tokens are used per model parameter, used in compute scaling analysis. "Token Per Parameter (TPP) ratios between 1 and 2000."
- tri-modal: Involving three modalities (e.g., text, image, audio) in a single unified model. "we introduce the first tri-modal \gls{mdm} pretrained from scratch"
- unmasking schedule: The plan for which masked positions are revealed at each reverse diffusion step during sampling. "Based on the unmasking schedule, a subset of masked positions are revealed"
- uniform-state diffusion: A discrete diffusion variant where corruption transitions to a uniform state rather than a mask token. "using a mix of masked and uniform-state diffusion."
- virtual batch size: A conceptual batch size used to analyze SDE-equivalent dynamics independent of the physical batch size. "a virtual batch size and a corresponding virtual number of iterations "
- VQ-GAN: A vector-quantized generative adversarial network used to tokenize images into discrete codes for diffusion. "use pretrained image tokenizers such as VQ-GAN~\citep{DBLP:conf/cvpr/EsserRO21, sber_movqgan, zheng2022movqmodulatingquantizedvectors}"
- VQ-VAE: A vector-quantized variational autoencoder that discretizes images into codebook indices for downstream generative modeling. "or VQ-VAE~\citep{DBLP:conf/nips/OordVK17} to downsample the full set of image pixels"
- warmup-stable-decay schedule: A learning rate schedule that warms up, stays stable, then decays, proposed as an alternative to cosine. "if, for example, a warmup-stable-decay schedule~\citep{DBLP:conf/nips/HageleBKAWJ24,DBLP:conf/icml/SchaippHTS025} were used instead of the current cosine schedule."
- wall-clock time: The actual elapsed training time, as opposed to theoretical compute. "compute (GPU saturation, FLOP-efficiency, wall-clock time)"
- z-loss regularizer: A regularization term applied to logits to stabilize their scale and improve training dynamics. "and a z-loss regularizer~\citep{DBLP:journals/corr/BrebissonV16a} to stabilize logits amplitudes."
Collections
Sign up for free to add this paper to one or more collections.