- The paper establishes that Muon outperforms traditional GD in nonconvex and star-convex settings by leveraging inherent matrix structures.
- The analysis details convergence complexities under Frobenius and spectral norm smoothness, with low-rank approximations enhancing optimization efficiency.
- Empirical results confirm Muon’s superior performance with momentum and underscore its potential for optimizing large-scale neural networks.
On the Convergence Analysis of Muon
Introduction
This essay addresses the convergence properties of Muon, a novel optimizer tailored for matrix-structured parameters in neural networks. Unlike conventional optimizers that treat matrices as flattened vectors, Muon leverages the inherent matrix structures, potentially improving optimization in neural network training. This paper provides a detailed theoretical convergence analysis of Muon, comparing it against Gradient Descent (GD) and illustrating empirical results supporting the theoretical findings.
Theoretical Analysis
Convergence in Nonconvex Settings
Muon’s convergence was analyzed under various smoothness conditions, focusing on nonconvex optimization tasks common in neural network training.
- Frobenius Norm Lipschitz Smoothness: For functions with this property, Muon can achieve convergence with a complexity of O(r2Lσ2Δϵ−4), where r is the matrix rank and L the Lipschitz constant.
- Spectral Norm Lipschitz Smoothness: When matrix parameters satisfy this condition, Muon benefits from reduced complexity O(rL∗σ2Δϵ−4), with L∗ as the spectral norm smoothness constant. This reflects Muon's advantage in settings where Hessians exhibit low-rank structures or approximate blockwise diagonal properties.
The paper establishes the relationship between these smoothness constants and real-world phenomena, such as neural network Hessians' observed low-rank and blockwise diagonal structures (Figure 1).
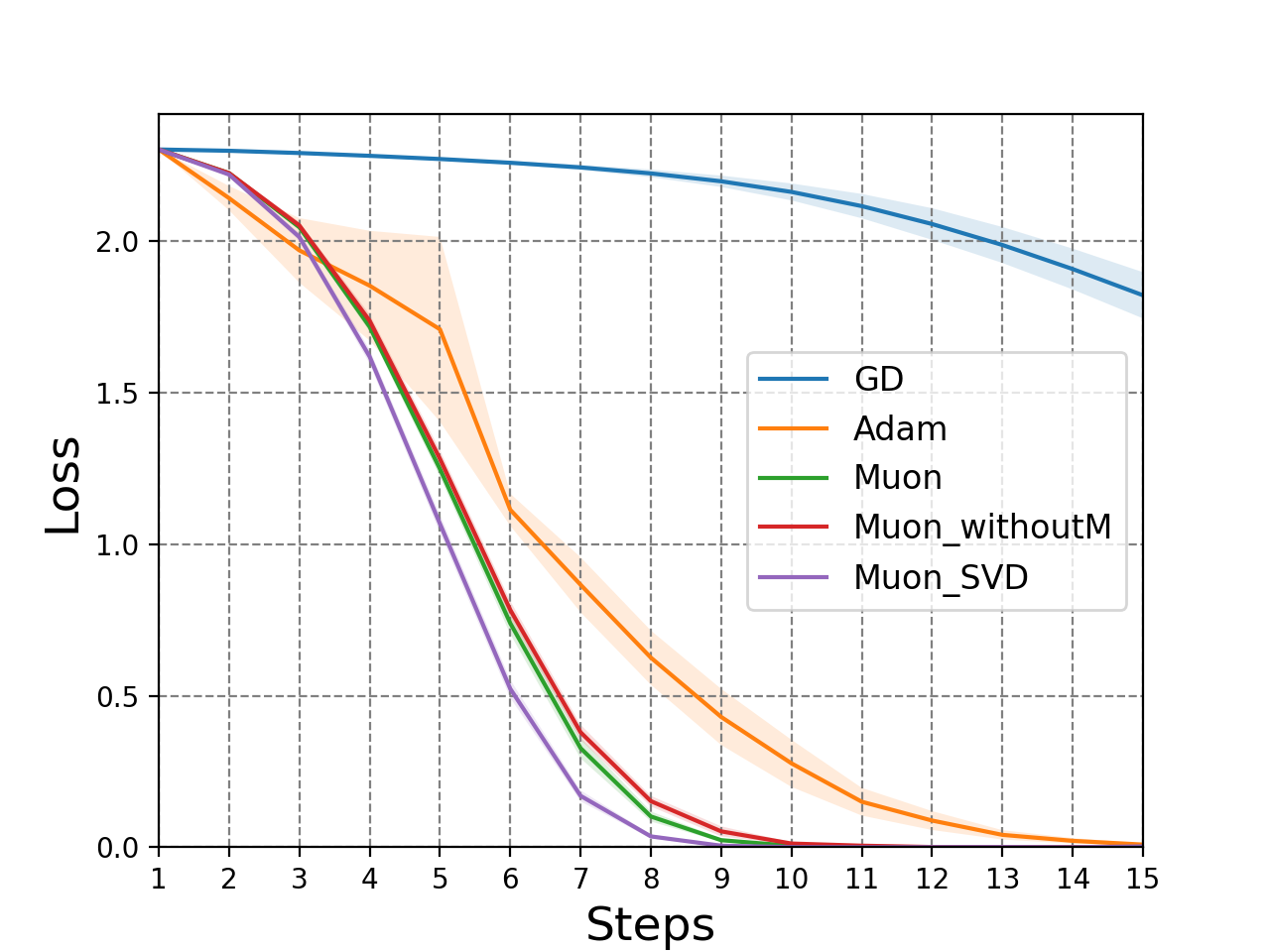
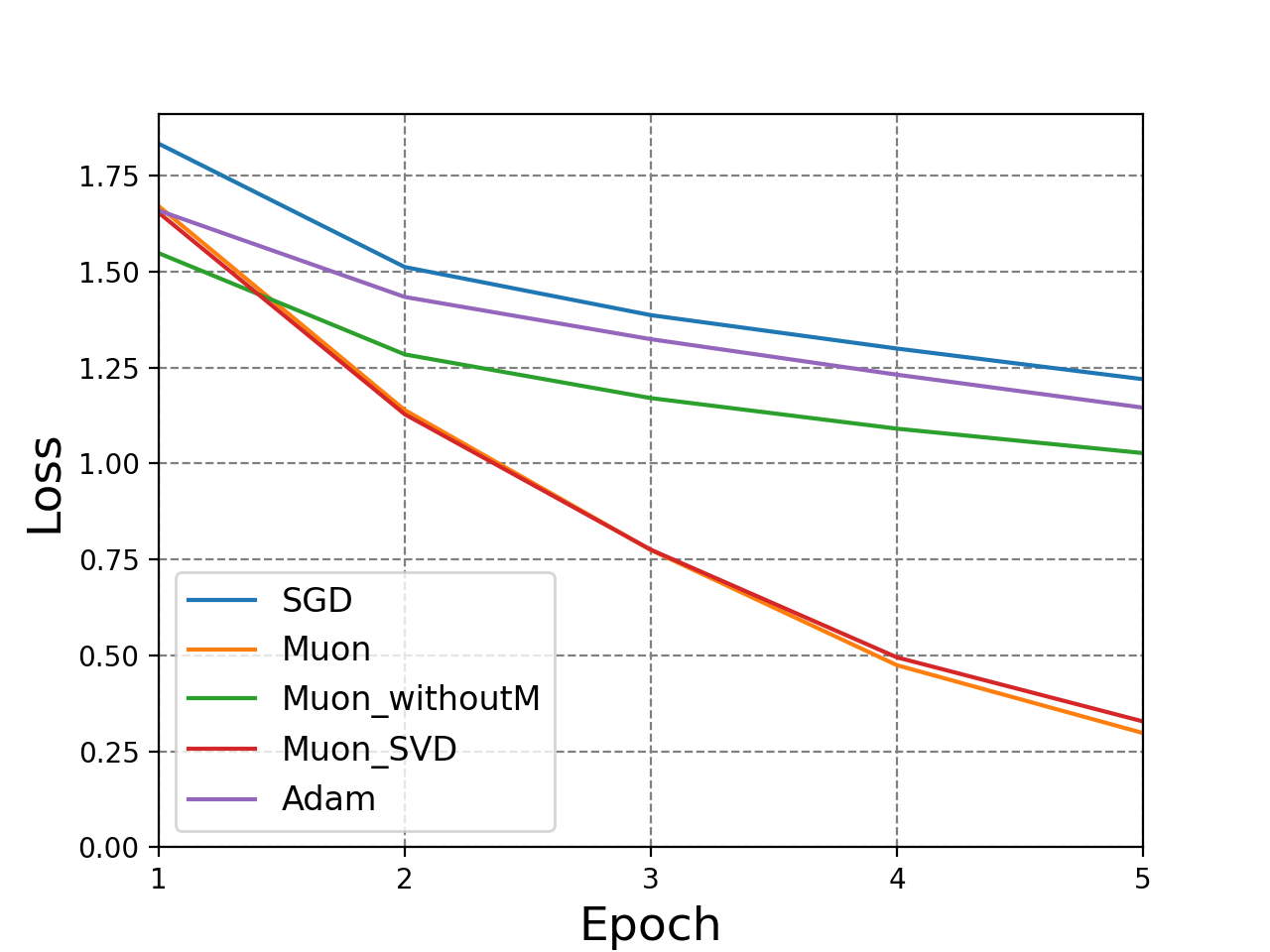
Figure 1: Deterministic
Star-Convex Functions
For star-convex functions, the study further explores convergence rates relative to GD. The paper suggests that under spectral norm conditions, Muon achieves superior convergence, especially when the Hessian structures align with observed low-rank and blockwise characteristics in practice.
Practical Considerations
Muon’s implementation in practice often employs approximations of orthogonalization, utilizing Newton-Schulz iterations (Figure 2). These iterations offer computational benefits while maintaining effective orthogonal gradient updates.
Empirical Validation
The authors conducted comprehensive experiments validating Muon's theoretical advantages. Figure 3 illustrates the empirical superiority of Muon over traditional optimizers like GD and Adam, especially noticeable when applying Muon with momentum.
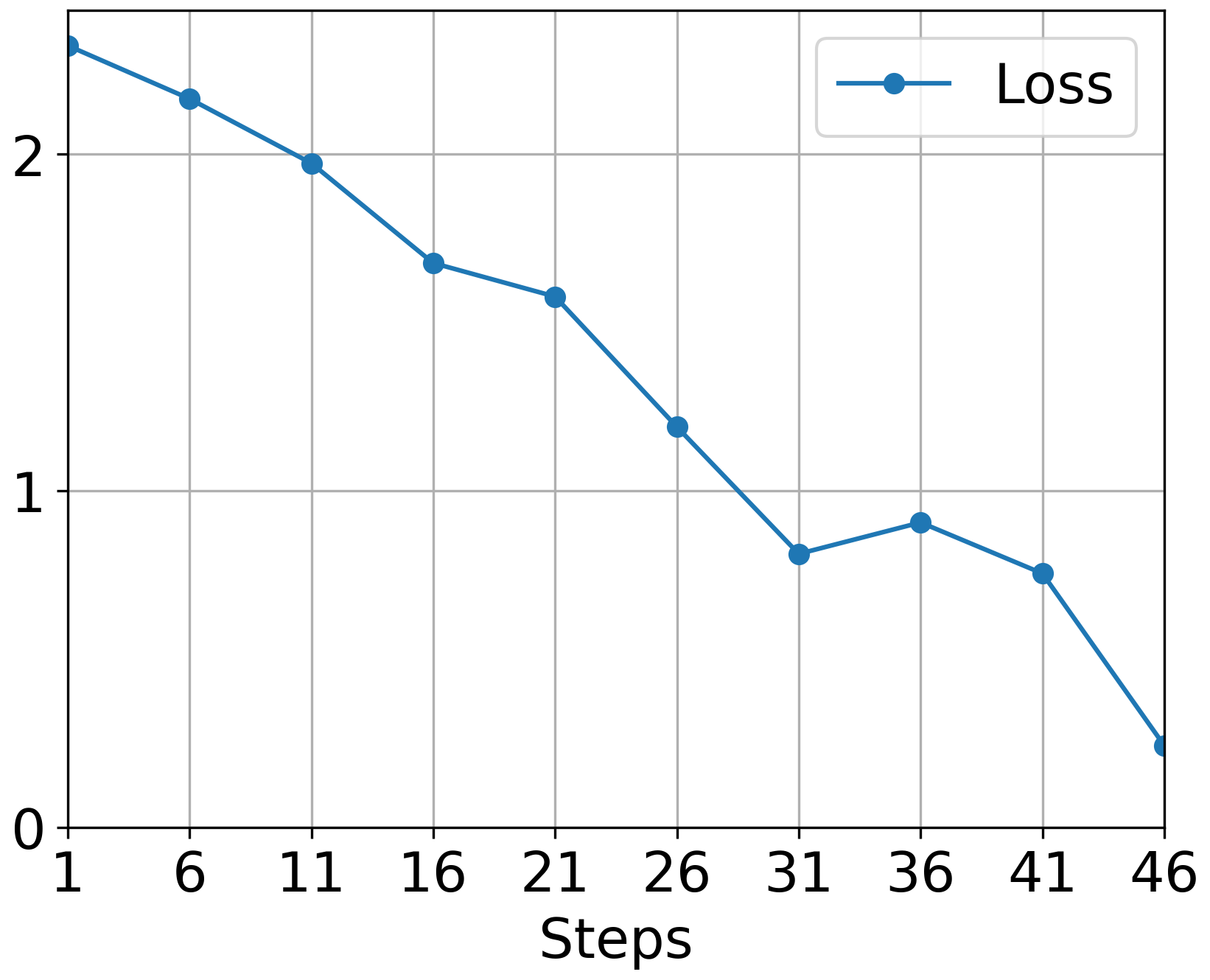
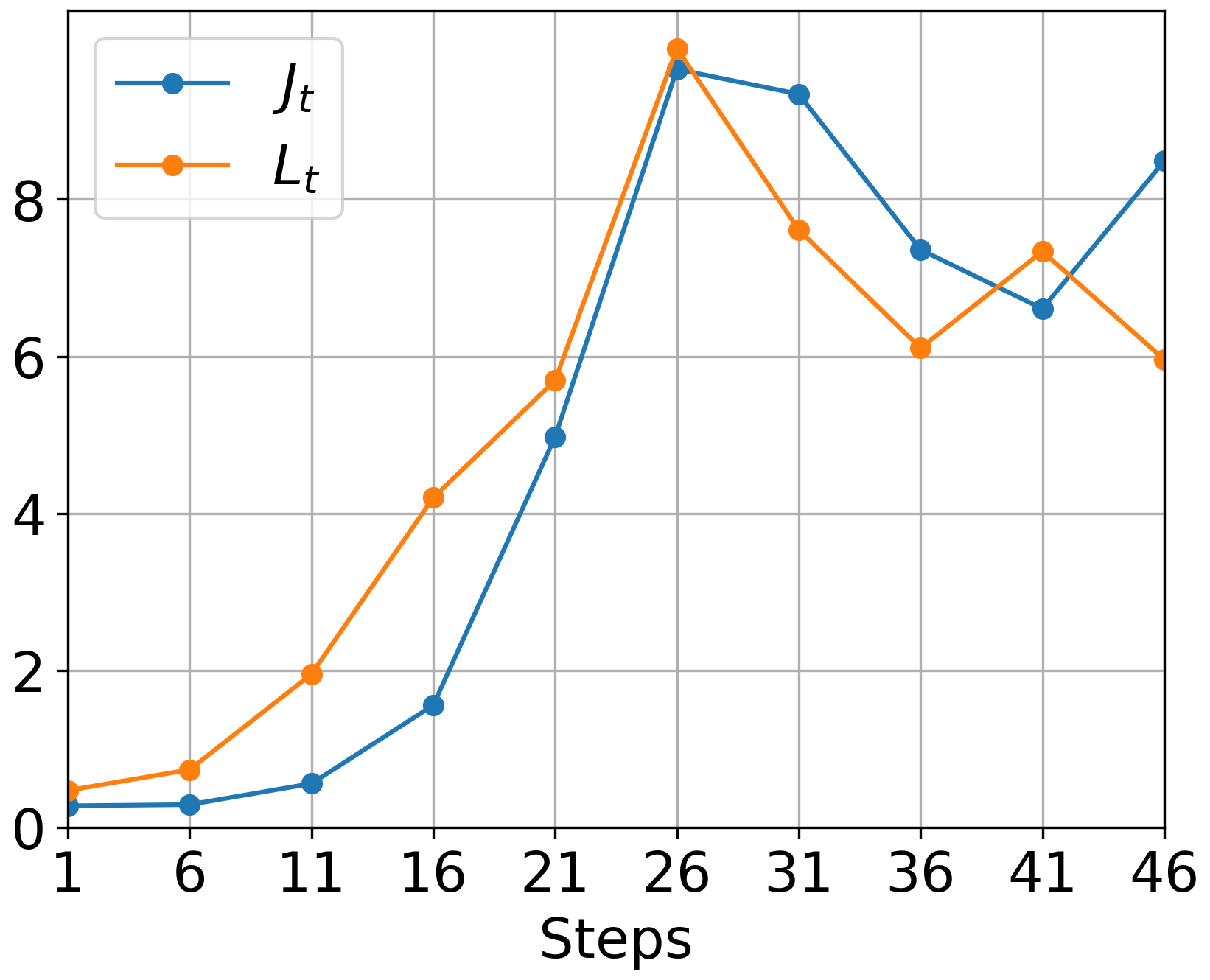
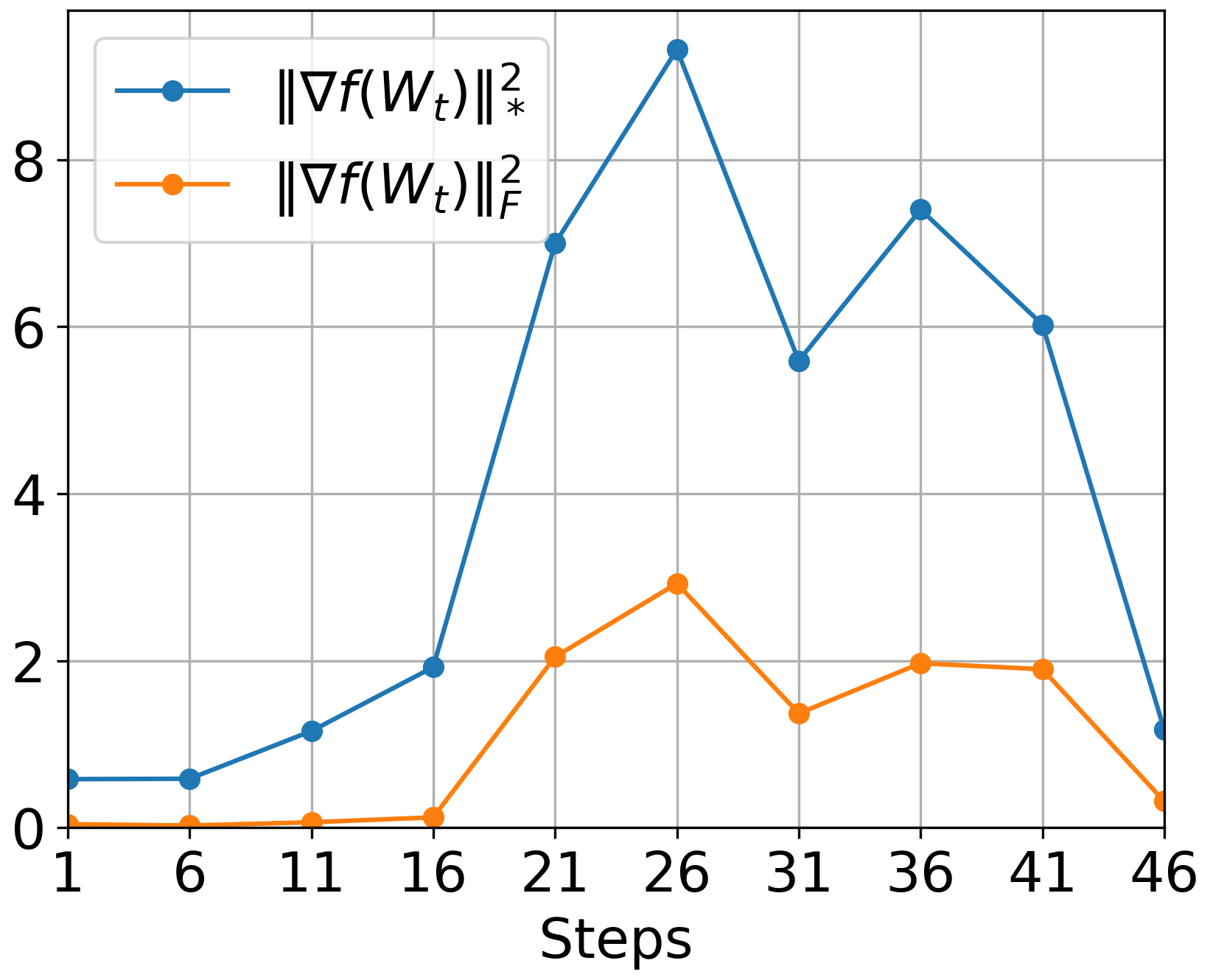
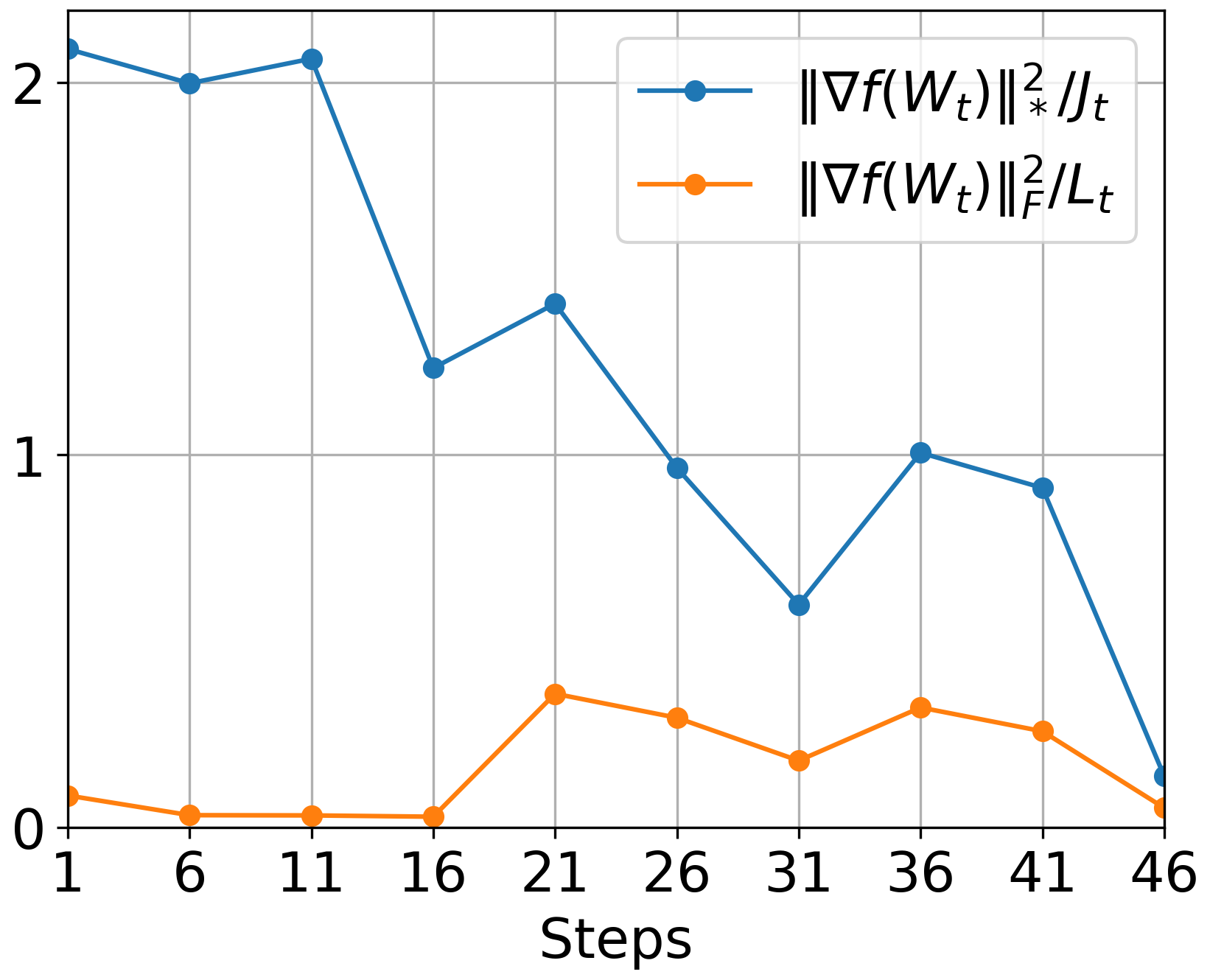
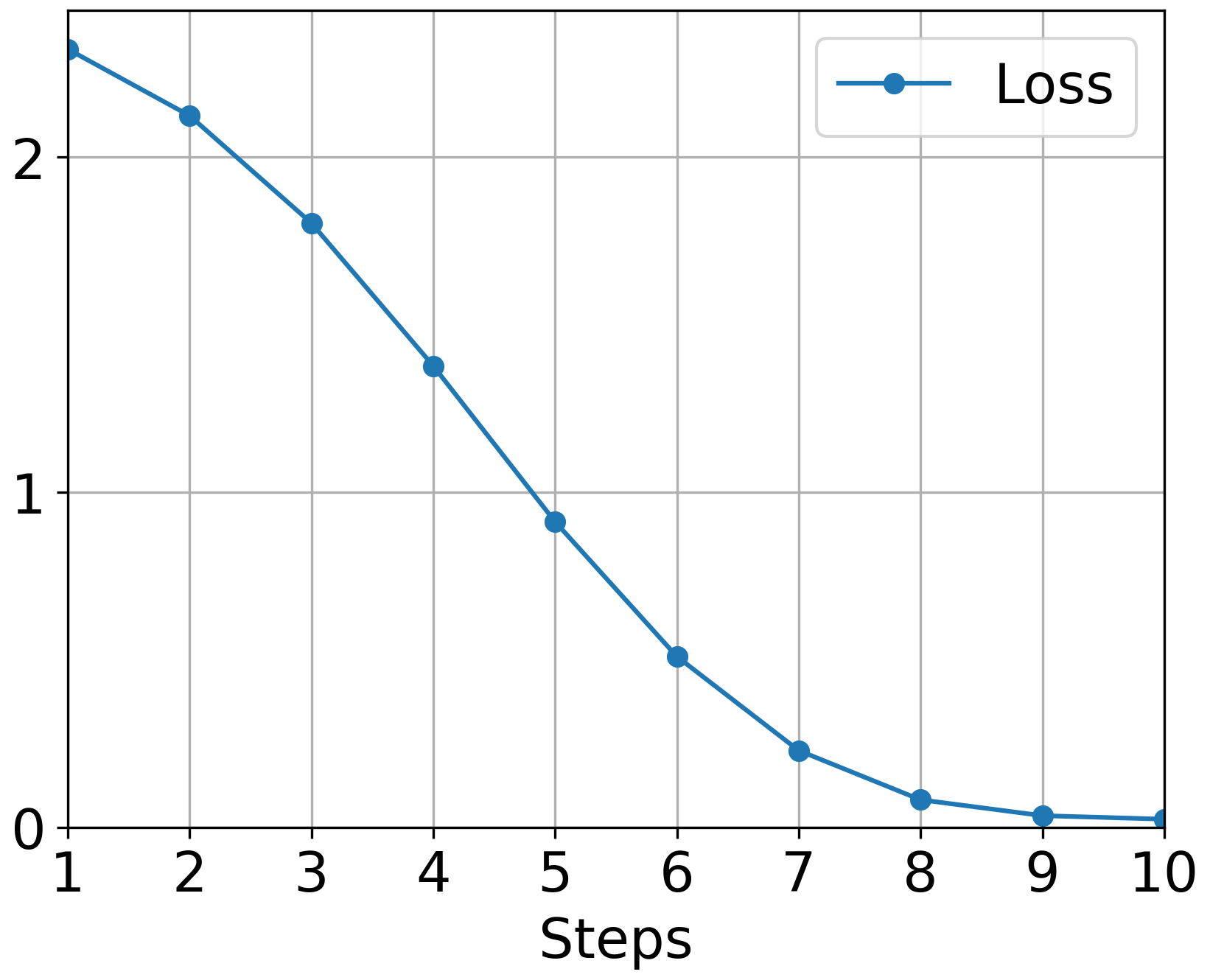
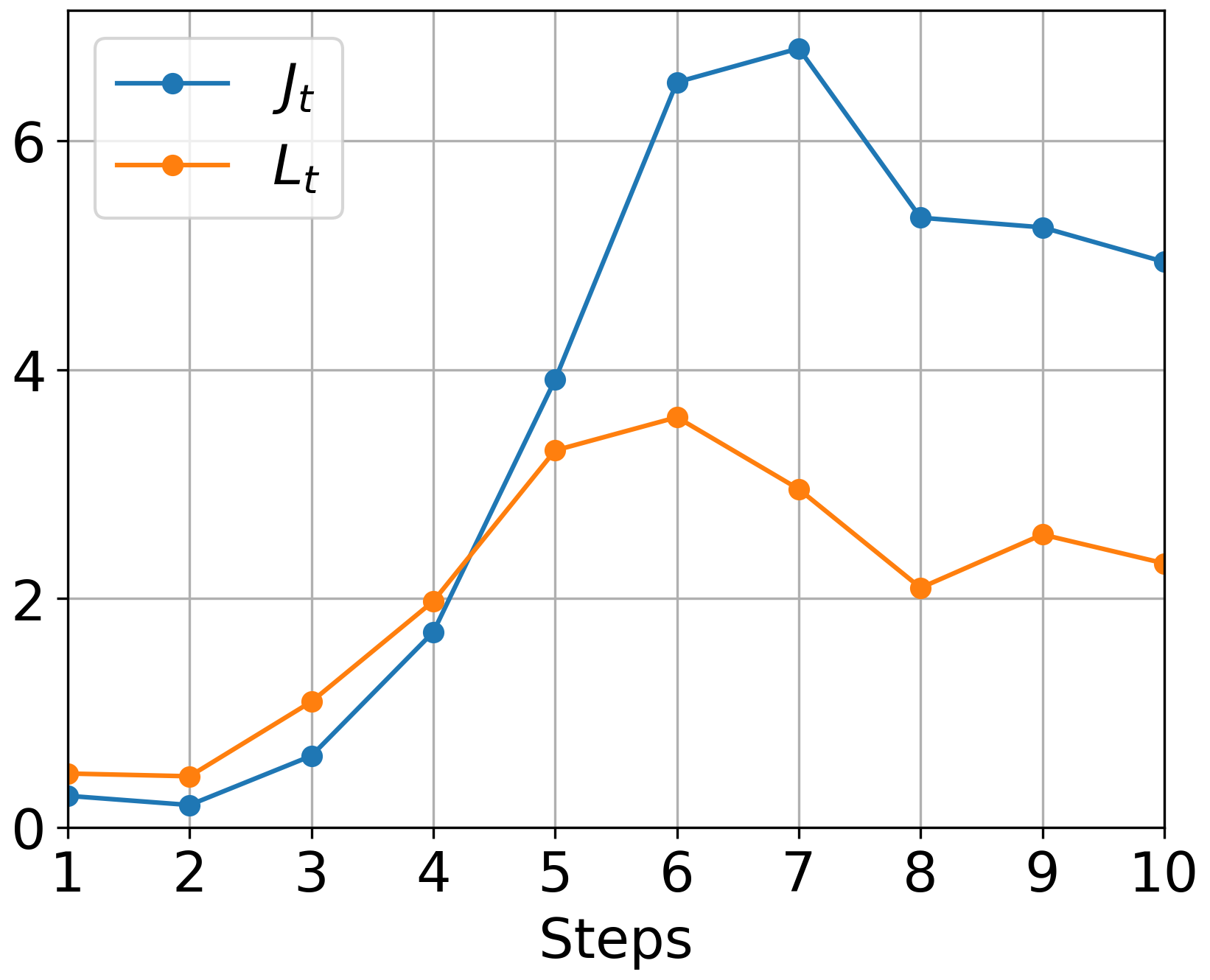
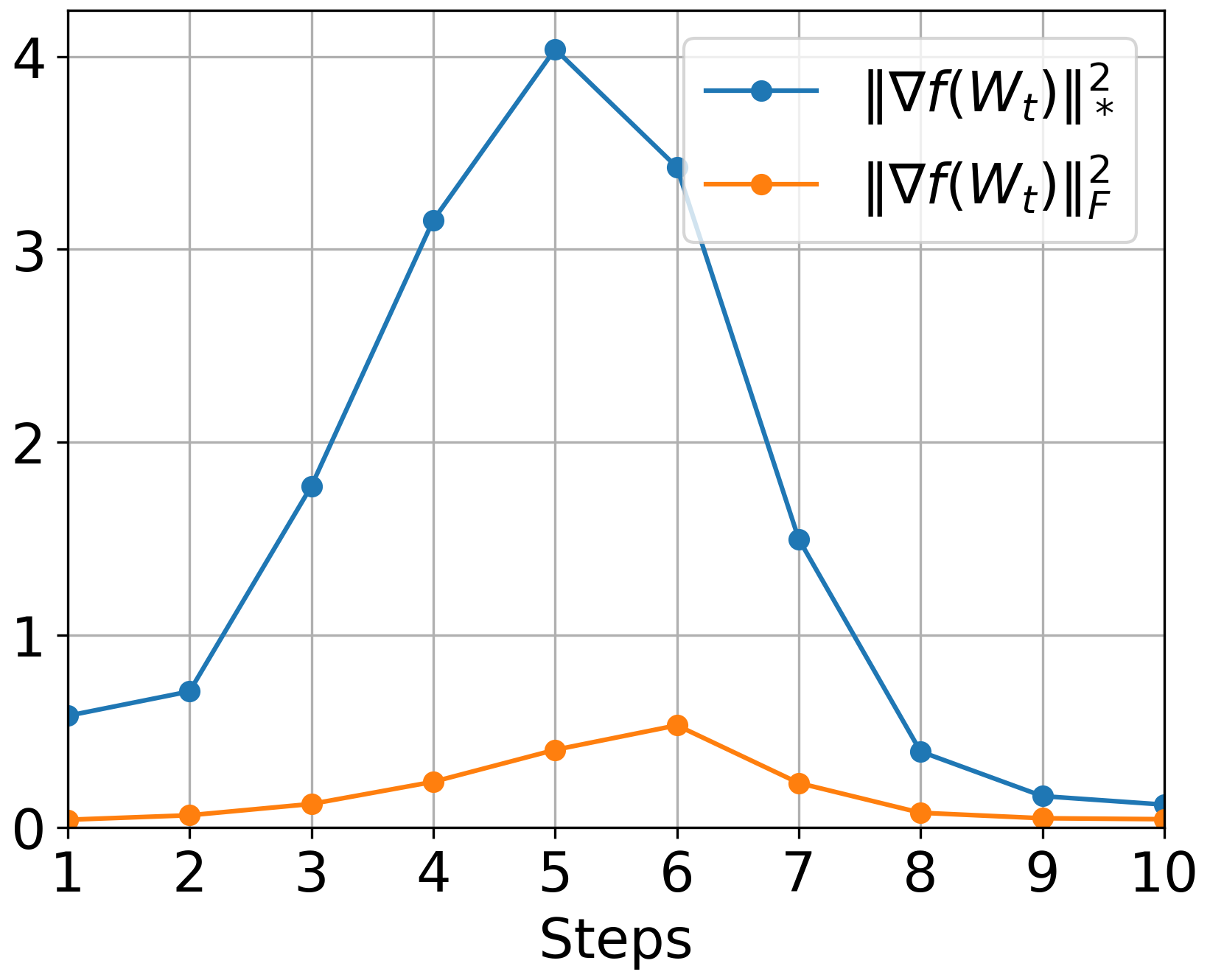
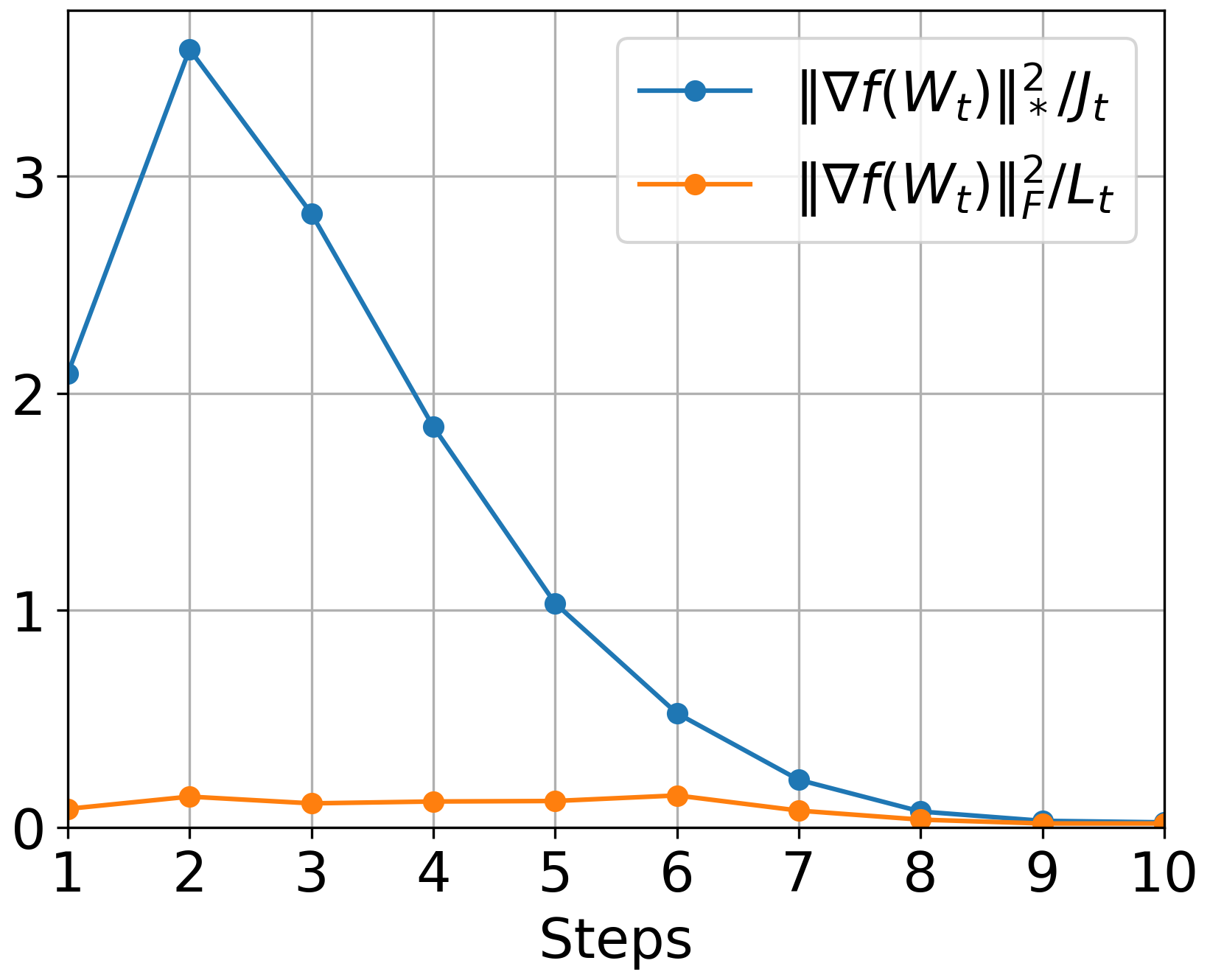
Figure 3: GD: Loss
Implications and Future Directions
The findings underline Muon's potential to outperform classical gradient descent methods, primarily when applied to neural networks with complex parameter structures. The implications for optimizing LLMs and other deep learning architectures are substantial, emphasizing efficiency gains in computational resources and training time.
Future research should focus on expanding Muon's application to large-scale neural network architectures, investigating further the theoretical bounds of Hessian structures, and developing improved approximation techniques for orthogonalization processes.
Conclusion
Muon represents a significant step forward in optimization for network training, exploiting matrix structures in ways that divergent from traditional vector-based approaches. Its convergence properties in both nonconvex and star-convex settings open new avenues for efficient training of complex models, aligning theoretical insights with empirical successes.