- The paper presents the Muon optimizer's main contribution by integrating orthogonalized momentum updates to implicitly enforce spectral norm constraints for regularizing deep models.
- It employs Lyapunov function decrement analysis to ensure convergence to a KKT point while regulating singular values through implicit subgradient computations.
- Empirical results on architectures like ResNet and LLaMA demonstrate that Muon effectively reduces overfitting and maintains robust training dynamics.
Muon Optimizes Under Spectral Norm Constraints
Introduction
The paper "Muon Optimizes Under Spectral Norm Constraints" refers to the development and theoretical analysis of the Muon optimizer. The research examines the intersection of emergent optimization algorithms, particularly Muon, with existing theoretical frameworks, such as the Lion-K family of optimizers. This synthesis highlights the capacity of these optimization techniques to enforce spectral norm constraints implicitly on neural network weights, which introduces an aspect of regularization beneficial for deep learning models.
Theoretical Foundations
Muon is situated within the Lion optimizer framework by employing the nuclear norm, functioning as a special case powered by orthogonalized gradient momentum updates. The theoretical underpinning of Muon involves leveraging the properties of the spectral norm ∥⋅∥2, primarily through analysis that aligns with optimization strategies involving regular constraints on singular value limits.
The Muon optimizer is defined as an extension and generalization of existing frameworks like AdaGrad and AdamW, possessing enhancements for dynamic learning rate adjustments. It employs a structure that ensures convergence to a KKT (Karush-Kuhn-Tucker) point for a constrained optimization problem by utilizing Lyapunov stability principles. The decrement of Lyapunov functions provides insight into the gradient flow and constraint maintenance, critical to understanding scaling effects and optimization trajectory stability.
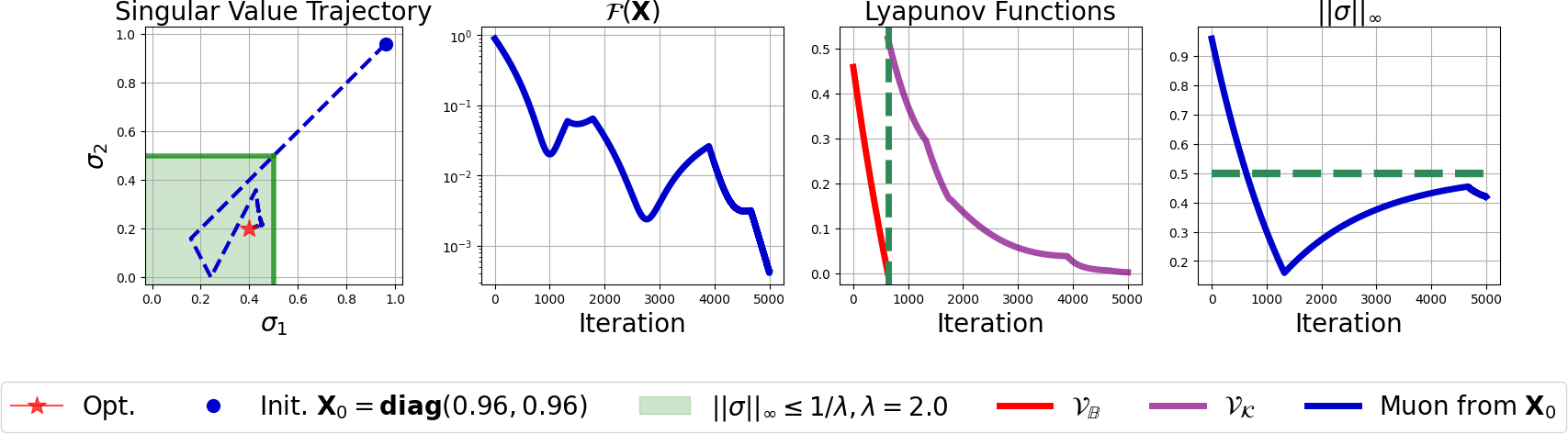
Figure 1: Convergence behavior of the Muon optimizer. Although the primary objective value F(X) exhibits nonmonotonic fluctuations, the Lyapunov functions VB and VK decrease monotonically within their respective domains --- VB when the trajectory is outside B, and VK once the trajectory enters B.
Implementation and Practical Considerations
Implementing the Muon optimizer involves careful adjustment of hyperparameters such as λ, which controls the norm constraint, and ηt, the learning rate, to ensure that the spectral norm constraints are met at every iteration. This requires initializing the weight matrices within feasible regions and performing iterative updates governed by implicit subgradient computations derived from the spectral norm.
The application of these principles shown in the experiments verifies significant results across datasets like CIFAR-10 and models such as ResNet variants. Muon displays properties of constrained optimization by steering the trajectories of singular values within bounded regions and demonstrating robust behavior across diverse network architectures.
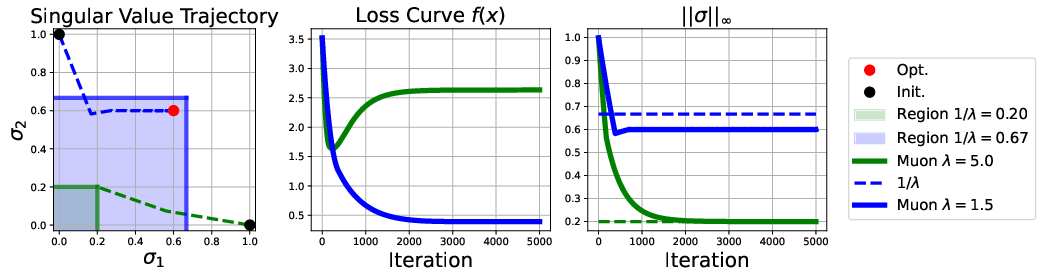
Figure 2: Trajectories of the Muon optimizer for the matrix-valued optimization problem minX. Demonstrates convergence to the feasible solution space respecting the spectral constraints.
Empirical Results
Empirical validations confirm Muon's effectiveness in maintaining spectral norm constraints throughout training processes, emphasizing the systematic regulation and bounding of singular values across diverse and large networks, ensuring regularized training dynamics.
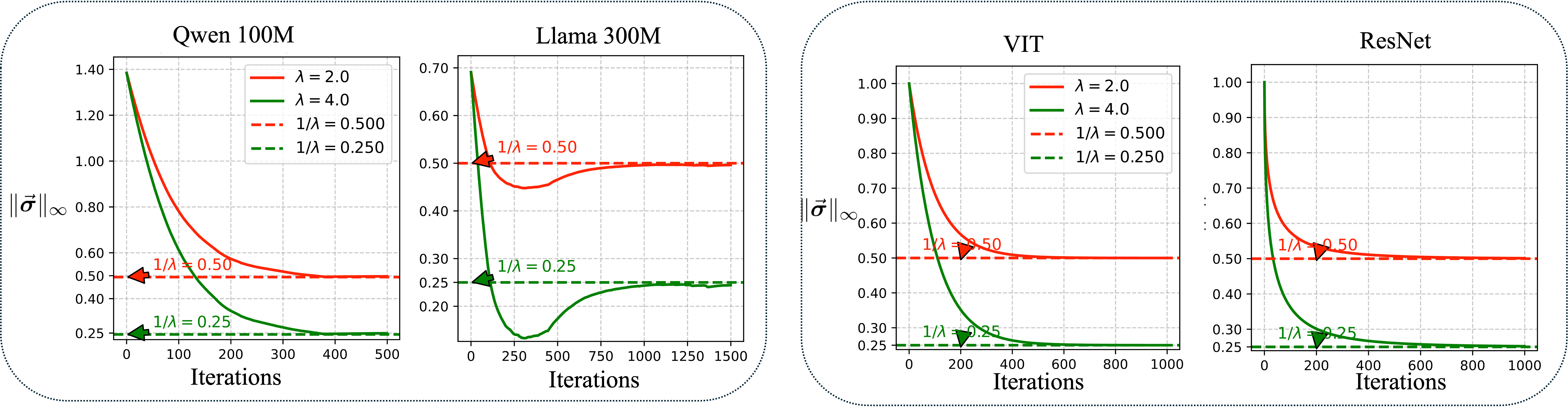
Figure 3: Verification of the implicit constraint enforced by the Muon optimizer on the weight matrices, confirming bounds within the theoretical limits defined by different λ values.
Moreover, applying Muon to architectural giants like LLaMA and ResNet showcases its capability in controlling the complexity of models, effectively reducing overfitting while maintaining high performance—a trade-off advantageous where robustness is prioritized over raw empirical accuracy.
Conclusions
Muon stands as a theoretically substantiated optimizer within the Lion optimization framework. Its role in deep learning extends beyond mere optimization to encompass improved model regularization and constraint adherence. The paper underscores Muon's capacity to enforce spectral constraints, offering an avenue for further explorations in even broader convex formulations and potential improvements in dynamic training environments.
Implications for Future Research:
- Generalization of Convex Functions: Further exploration of diverse convex functions within the Lion framework to assess varying implicit regularization effects.
- Broader Application: Evaluating Muon's performance across more varied architectures and domains, particularly in settings of large-scale unsupervised learning.
- Integration with Other Techniques: Potential integration with existing adaptive gradient methods to exploit contextual advantages in learning patterns and architectural nuances.
This work iteratively builds on Muon’s theoretical grounding, providing a comprehensive outlook that integrates well with modern optimization philosophies in AI and neural network training paradigms.