- The paper presents a comprehensive review of LLM-based Text-to-SQL systems, detailing methodologies like pre-processing, in-context learning, fine-tuning, and post-processing to transform natural queries into SQL.
- It highlights key performance factors such as schema linking, prompt engineering, and SQL correction, with evaluation metrics including execution and string-match accuracy.
- The study identifies challenges including structural ambiguity, insufficient schema comprehension, and data privacy, and suggests future research in advanced schema linking, efficient fine-tuning, and multilingual tasks.
Exploring the Landscape of Text-to-SQL with LLMs
Recent advancements in LLMs have significantly influenced the development of Text-to-SQL systems, highlighting the capacity of these models to transform natural language queries into structured SQL statements. This paper presents a comprehensive review of the current state and evolving trends in LLM-based Text-to-SQL research, outlining methodologies, challenges, and potential future directions.
Research Trends in LLM-Based Text-to-SQL Studies
LLM-based Text-to-SQL approaches have attracted increasing attention, particularly from September 2023 onwards, demonstrating notable interest in creating systems that effectively leverage the capabilities of LLMs. Most studies were published in conferences related to natural language processing, such as EMNLP and ACL, indicating a strong focus on improving methodologies rather than datasets or evaluation metrics.
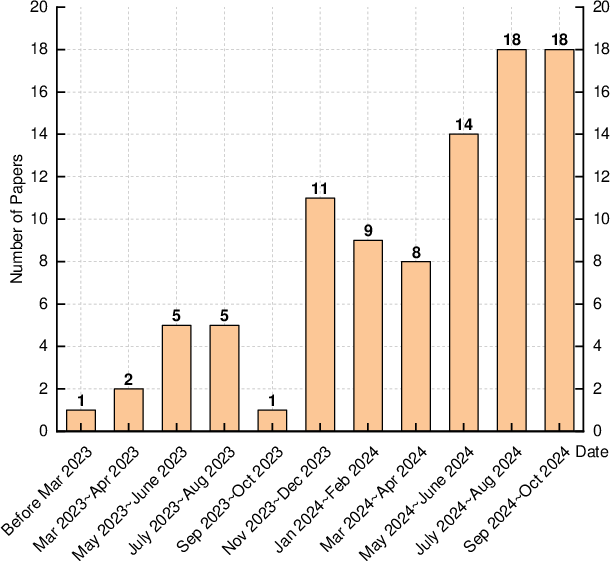
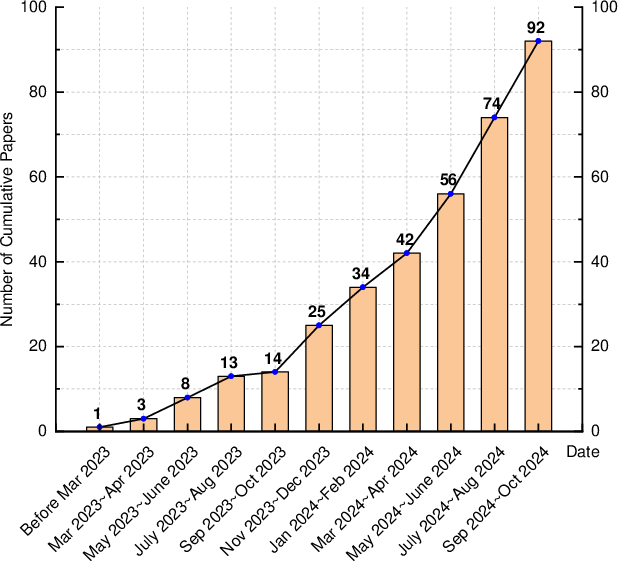
Figure 1: Publication trends of the surveyed LLM-based text-to-SQL approaches from April 2022 to October 2024.
Current State of Research on LLM-Based Text-to-SQL Techniques
Pre-Processing Paradigm
Pre-processing is crucial for preparing data before SQL generation. Key strategies include schema linking, cell value acquisition, question rewriting, and data augmentation. These methods facilitate connection and alignment of natural language queries with database schemas, thereby enhancing the accuracy and effectiveness of SQL generation.
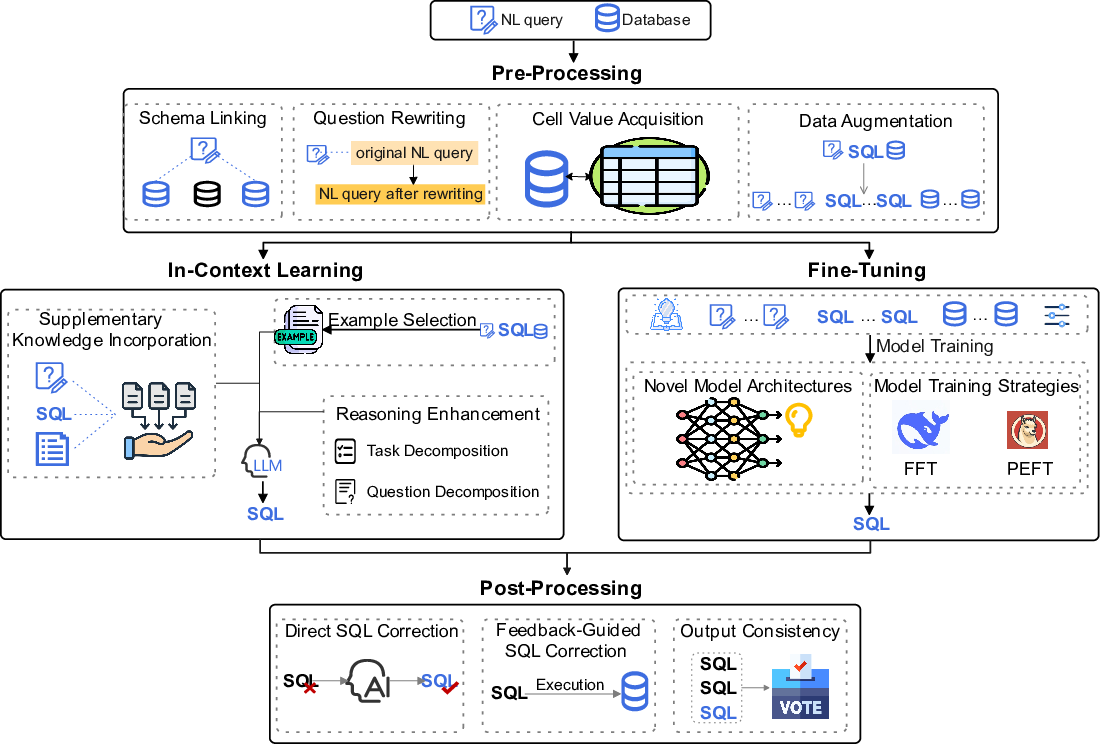
Figure 2: Illustration of a typical LLM-based text-to-SQL workflow, involving pre-processing, in-context learning, fine-tuning and post-processing paradigms.
In-Context Learning (ICL) Paradigm
ICL techniques predominantly utilize prompt engineering to adapt models without retraining, offering adaptability across different scenarios. This includes supplementary knowledge integration, effective selection of examples, and enhancement of reasoning through task and question decomposition to improve SQL accuracy.
Fine-Tuning (FT) Paradigm
FT techniques focus on adjusting model architectures or parameters to improve performance in SQL tasks. These approaches include developing novel model architectures and leveraging parameter-efficient fine-tuning strategies like LoRA and QLoRA, although they are relatively less explored compared to ICL techniques.
Post-Processing Paradigm
Post-processing strategies involve refining the SQL output. Direct SQL correction, feedback-guided correction, and consistency checks are employed to ensure accuracy and reliability in the generated SQL, addressing syntax errors and incorporating semantic consistency through feedback loops.
Characteristics of Datasets and Evaluation Metrics
Several datasets have been released, ranging from single-domain to cross-domain and multilingual datasets. Evaluation metrics commonly assess the content matching and execution results of SQL queries, including string-match accuracy, component-match accuracy, and execution accuracy.
Challenges and Future Directions
Key Unresolved Challenges
Several challenges persist in the current research landscape:
- Structural Complexity and Linguistic Ambiguity: Achieving accurate interpretation of complex user queries to generate reliable SQL remains challenging.
- Insufficient Database Schema Comprehension: Models often struggle with comprehending complex and domain-specific schemas.
- Lower Model Efficiency and Generalization: Efficiency challenges such as input capacity limits and slower inference speeds hinder large-scale adoption.
- Data Scarcity and Quality Issues: High-quality labeled datasets are scarce, impacting model training.
- Data Privacy Concerns: Reliance on proprietary LLMs raises privacy issues due to database schema exposure.
Future Research Directions
Further research should explore:
- Enhancing Schema Linking and Question Rewriting: Improve precision in schema linking and mitigate ambiguity in natural language queries.
- Advancing FT Techniques: Develop novel parameter-efficient methods to optimize model performance.
- Improving Model Efficiency: Architectural innovations and advanced prompt engineering to optimize performance.
- Mitigating Data Security Concerns: Explore federated learning and open-source alternatives for secure data handling.
- Exploring Multilingual Context-Dependent Tasks: Enhance model robustness and generalization across diverse languages and multi-turn dialogues.
Conclusion
This survey offers a comprehensive review of the advancements in LLM-based Text-to-SQL systems, analyzing research trends, methodologies, datasets, challenges, and implications for future work. Through systematic exploration, the survey aims to inspire innovation and guide future research endeavors in leveraging LLMs for efficient SQL generation.

